원문: Reliable LLM Inference at Scale 저자: Ying Chen, Wendy Hu, Ankit Mathur, Mike Eastham, Pei-Lun Liao, Wai Wu, Arjun DCunha 게시일: 2026년 5월 27일
요약
- 멀티 테넌트 LLM 서빙은 워크로드 전반의 용량(capacity)을 추론할 수 있어야 합니다. “Model unit” 이라는 VM 유사 추상화를 도입해 고객별로 GPU 자원을 할당·라우팅·확장할 수 있게 했습니다.
- Model unit 위에서 동작하는 비용 인식(cost-aware) 로드 밸런싱과 오토스케일링으로, 정적 프로비저닝 대비 GPU 비용을 80% 이상 절감하면서도 지연 목표를 유지했습니다.
- 블랙박스 헬스체크 같은 런타임 신뢰성 장치가 silent 장애를 자동으로 감지하고 복구하며, 멀티모달 병목을 프로파일링해 3배 처리량 향상을 끌어냈습니다.
Databricks 에서 우리는 모든 프런티어 모델을 서빙하는 고유한 추론 플랫폼을 구축해 왔습니다 — Kimi, Qwen 같은 오픈소스 모델부터 OpenAI, Gemini, Claude 같은 독점 모델까지 모두. Superhuman, Yipit Data, Fox Sports 등 세계에서 가장 큰 에이전트 애플리케이션들의 추론을 떠받칩니다. 오늘 우리는 월 120조 토큰(120T) 이상을 서빙합니다. 대규모에서 LLM 서빙을 어렵게 만드는 것은 신뢰성입니다. 에이전트가 우리가 일하고 살아가는 방식의 인터페이스가 되면서 추론 수요는 기하급수적으로 증가하고 있습니다. 업무 시간에 정점을 찍는 매우 스파이크한 수요 곡선을 봅니다.
대규모 LLM 추론 운영의 도전
신뢰성 있는 추론 플랫폼이란 무엇인가? 계약(contract)은 단순해 보입니다 — 가용성(Availability)은 요청이 처리될 수 있느냐 입니다. 그러나 실제로는 사용 사례마다 지연 요구가 크게 다르며, 이것이 가용성에 함께 영향을 줍니다. 가장 진보된 에이전트는 p95 TTFT(time to first token) 과 OPTS(output tokens per second) 가 저하되는 것을 감당할 수 없습니다. 멀티 테넌트 LLM 서빙 시스템에서 신뢰성과 지연을 동시에 달성하는 것은 도전적입니다.신뢰성
프런티어 성능에는 KV 캐시 전송을 위한 고대역폭 인터커넥트가 있는 최신 GPU 가 필요합니다. 이런 컴퓨트 셋업은 본질적으로 고전적 CPU 시스템보다 신뢰성이 낮고, 비쌉니다. all-to-all 통신이 요구되므로, 한 노드의 다운타임은 disaggregated prefill/decode 셋업에서 다른 여러 노드의 재구성을 강요합니다. 최고 대역폭 네트워킹은 단일 물리 랙 내 single-spine 연결을 요구합니다(예: NVL72 시스템). 이는 데이터센터 단일 랙 내 특정 시스템의 장애가 광범위한 폭발 반경(blast radius) 을 가진 장애를 만들 수 있다는 의미입니다. 멀티-AZ 또는 백업 인스턴스 타입을 활용하는 분산 시스템의 표준 트릭은 비싼 백업 GPU 를 유휴 상태로 유지하는 것 — 비용상 금지 옵션입니다. 오버 프로비저닝은 또 다른 고전적 트릭이지만, 컴퓨트 공급이 매우 제한적이므로 극도로 비싸고 비현실적입니다. 따라서 시스템은 무거운 부담 아래에서도 운영 가능한 상태를 유지해야 합니다. 이러한 제약 아래에서 출시 속도도 높게 유지해야 합니다 — 우리의 추론 수요는 전년 대비 여러 자릿수 성장했고, 그 성장을 떠받치며 혁신 기능을 출하하는 것이 도전이었습니다. 이미지, 비디오, 안전성 분류 같은 기능들은 각각 다른 전처리 시스템을 요구하며 모두 독립적으로 확장되어야 합니다. 마지막으로, 동급 최고 성능과 새 모델 아키텍처 지원을 위해서는 커스텀 커널부터 자체(proprietary) 추론 엔진에 이르는 광범위한 최적화가 필요합니다. 아키텍처가 미세하게 변할 때마다 새 저수준 소프트웨어가 도입되며, 대규모에서 불투명한 방식으로 실패할 수 있습니다 — 서버 행(hang)부터 GPU 크래시까지 디버깅이 어려운 시나리오로 표면화됩니다.지연
다양한 부하 패턴에서 지연을 통제하는 것은 어렵습니다. 요청을 서빙하는 비용이 사전에 추정하기 어렵고 매우 가변적이기 때문입니다. 무거운 부하 아래의 건강한 서버들도 모든 요청을 더 느리게 처리하며, 이는 처리량(즉 비용 효율성)과 제품이 처리해야 하는 가장 빠른 지연 사이의 트레이드오프를 노출합니다. 또한 서버에 할당된 요청의 혼합에 따라 매우 빠르게 비정상 상태에 진입할 수 있어, 신뢰성 문제로도 나타날 수 있습니다.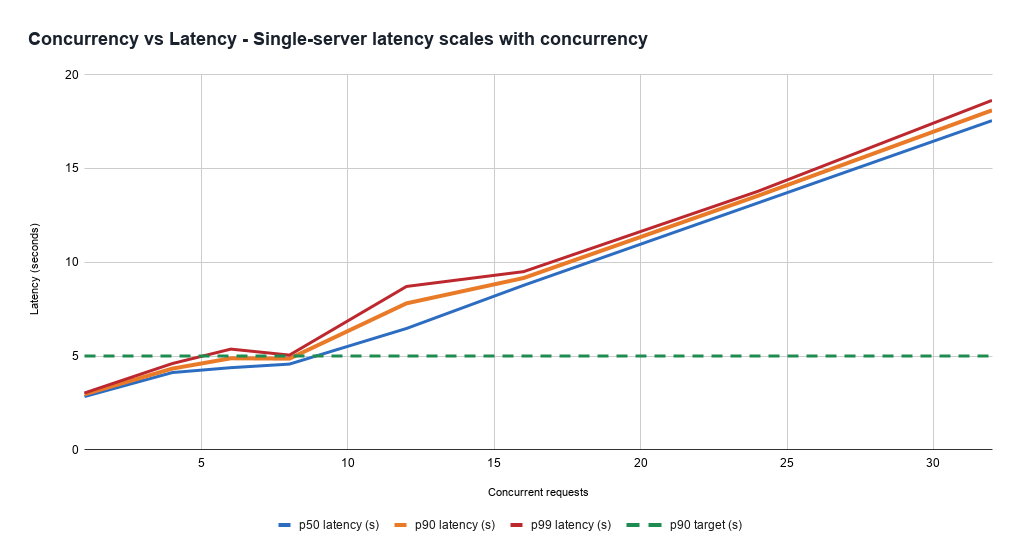 또한 지연은 출력 토큰 생성에 의해 지배되지만, 모델이 얼마나 길게 말할지 예측하기 어려우므로 사전 비용 추정이 어렵습니다. 따라서 저지연 서빙에는 복잡한 용량 관리, 로드 밸런싱, 요청 우선순위화 시스템이 필요합니다.
또한 지연은 출력 토큰 생성에 의해 지배되지만, 모델이 얼마나 길게 말할지 예측하기 어려우므로 사전 비용 추정이 어렵습니다. 따라서 저지연 서빙에는 복잡한 용량 관리, 로드 밸런싱, 요청 우선순위화 시스템이 필요합니다.
전체 아키텍처
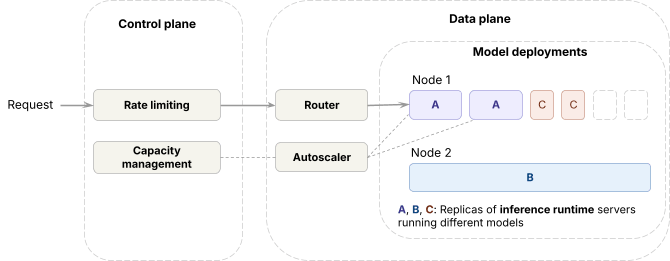
문제 해결의 구체로 들어가기 전에, 서빙 인프라의 고수준 개요를 살펴봅니다. 데이터 플레인:- 추론 런타임(오픈소스 + 자체 엔진)이 프런티어 GPU 위에 배포됩니다.
- 모델 배포 전반의 트래픽을 처리하기 위해, 데이터 플레인은 동일 모델의 복제본 간 부하를 분산하는 라우터(우리는 Axon 이라 부름) 와 복제본 수를 조정하는 오토스케일러 를 운영합니다.
- 요청은 데이터 플레인 도달 전 레이트 리미팅 을 거칩니다.
- 요청 메트릭에 기반해, 용량 관리(capacity management) 알고리즘 이 각 워크로드가 얻을 GPU 용량을 결정하고, 오토스케일러가 이를 적용합니다.
용량을 다루기
용량을 대략 추론할 수 있어야 합니다 — 얼마나 가지고 있고, 얼마나 팔았고, 고객이 얼마나 사용하는지. 이를 위해 “model unit” 이라는 추상화를 도입했습니다. 한 복제본이 분당 고정 수의 model unit (예: 100) 을 처리할 수 있다고 투영하면, 다음 가정이 가능합니다.- 입력이나 출력이 긴 요청은 더 많은 model unit 을 소비합니다(같은 시간 윈도우 안에 더 적게 완료되므로).
- prefill 과 decode 의 처리량 특성이 다르므로, 출력이 긴 요청이 입력이 긴 요청보다 비쌉니다.
 따라서 요청 비용을 다음과 같은 다차원 함수로 모델링합니다.
계수 α, β, γ 는 각 모델·하드웨어 타입별 자동 벤치마킹으로 결정합니다. Model unit 은 prefix caching 같은 최적화를 위해 추가 조정될 수 있으며, 멀티모달리티 같은 기능도 반영해야 합니다.
이런 추정은 구조적으로 불완전하지만, 멀티 테넌트 시스템을 클라우드 VM 과 유사한 더 다루기 쉬운 형태로 분해하는 방법으로 작동합니다. VM 은 특정 고객에게 할당될 수 있는 예측 가능한 성능을 제공하는 바람직한 속성을 갖습니다. 운영 에이전트 워크로드에는 저지연과 용량에 대한 보장을 제공하는 것이 중요한데, 이런 할당 시스템이 없다면 우리가 할 수 있는 최선은 “best-effort” 용량을 제공하는 것뿐이며, 너무 많은 고객이 시스템을 사용하면 회수될 수 있습니다.
따라서 요청 비용을 다음과 같은 다차원 함수로 모델링합니다.
계수 α, β, γ 는 각 모델·하드웨어 타입별 자동 벤치마킹으로 결정합니다. Model unit 은 prefix caching 같은 최적화를 위해 추가 조정될 수 있으며, 멀티모달리티 같은 기능도 반영해야 합니다.
이런 추정은 구조적으로 불완전하지만, 멀티 테넌트 시스템을 클라우드 VM 과 유사한 더 다루기 쉬운 형태로 분해하는 방법으로 작동합니다. VM 은 특정 고객에게 할당될 수 있는 예측 가능한 성능을 제공하는 바람직한 속성을 갖습니다. 운영 에이전트 워크로드에는 저지연과 용량에 대한 보장을 제공하는 것이 중요한데, 이런 할당 시스템이 없다면 우리가 할 수 있는 최선은 “best-effort” 용량을 제공하는 것뿐이며, 너무 많은 고객이 시스템을 사용하면 회수될 수 있습니다.
비용 기반 로드 밸런싱과 오토스케일링
요청이 서버에 미치는 영향이 매우 가변적이므로, 거의 최적의 라우팅 결정이 중요합니다. 일반적으로 로드 밸런싱은 P2C(power of two choices) 같은 통계적 접근에 기대어 큐 크기 기반으로 부하를 추정하고 샘플링을 활용해 가능한 모든 타깃을 이해하는 메모리·지연 오버헤드를 줄입니다. 하지만 LLM 의 지연은 높고, 서버 수는 스케일아웃된 CPU 시스템보다 적으며, 잘못된 라우팅의 비용은 가혹합니다. 따라서 LLM 서빙은 다른 접근을 요구합니다. 현재 우리는 Dicer — Databricks 의 auto-sharder — 를 사용해 워크로드를 서버 전반에 동적으로 라우팅합니다. 부하 인식 라우팅이 없으면, 긴 컨텍스트 요청이 개별 서버를 핫스팟으로 만들고 다른 서버들은 미활용 상태로 남습니다. 우리는 model unit 을 Dicer 와 통합하여 라우팅 결정이 전통적인 요청 기반 휴리스틱이 아닌 model unit 단위 서버 부하에 기반하도록 했습니다. Dicer 는 상태 유지(stateful) 세션 도 제공하여 요청 라우팅을 sticky 하게 만듭니다 — 한 워크로드의 요청들이 서버 부분 집합에만 가게 되어 캐시 히트율을 개선(코딩 에이전트처럼 지연 민감 워크로드에 결정적)하고 폭발 반경을 제한합니다. 향후 더 많은 학습을 통해 더 높은 정밀도의 비용 메트릭에 기반해 부하 메트릭을 튜닝하고 더 최적의 라우팅 시스템을 사용할 수도 있습니다.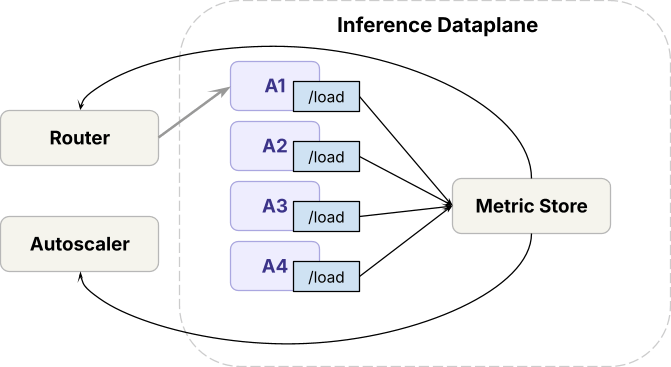 오토스케일링에도 유사한 문제가 존재합니다. 대기 요청 수만으로는 실제 부하를 반영하지 못합니다. 긴 컨텍스트 요청의 스파이크는 짧은 요청의 스파이크와 똑같아 보이고, CPU·메모리 메트릭은 실제 GPU 활용도와 마찬가지로 상관이 없습니다.
Model unit 을 사용하면 오토스케일러는 model unit 활용 비율에 따라 확장/축소 결정을 내릴 수 있습니다. 추론 엔진이 (하드웨어 타입·워크로드 형상에 따라 결정되는) 최대 model unit 의 일정 비율에 가까이 동작하면, 피크 처리량에 접근하고 있는 것이며 이는 확장(scale-up) 을 트리거합니다. 반대 상황은 축소(scale-down) 를 트리거합니다. 모델마다 수동으로 오토스케일링 규칙을 조정하는 대신, 이 접근은 모델 비의존적 스케일링 인프라를 가능하게 합니다.
LLM 추론 패턴 위에 오토스케일링을 구축한 것은 우리가 항상 최대 복제본으로 확장하는 것을 막아 줬습니다. 트래픽이 버스티한 모델의 경우, 오토스케일링이 복제본 수를 실제 수요에 가깝게 유지하여 피크 시점의 정적 프로비저닝 대비 80% 이상의 GPU 절감으로 이어졌습니다.
오토스케일링에도 유사한 문제가 존재합니다. 대기 요청 수만으로는 실제 부하를 반영하지 못합니다. 긴 컨텍스트 요청의 스파이크는 짧은 요청의 스파이크와 똑같아 보이고, CPU·메모리 메트릭은 실제 GPU 활용도와 마찬가지로 상관이 없습니다.
Model unit 을 사용하면 오토스케일러는 model unit 활용 비율에 따라 확장/축소 결정을 내릴 수 있습니다. 추론 엔진이 (하드웨어 타입·워크로드 형상에 따라 결정되는) 최대 model unit 의 일정 비율에 가까이 동작하면, 피크 처리량에 접근하고 있는 것이며 이는 확장(scale-up) 을 트리거합니다. 반대 상황은 축소(scale-down) 를 트리거합니다. 모델마다 수동으로 오토스케일링 규칙을 조정하는 대신, 이 접근은 모델 비의존적 스케일링 인프라를 가능하게 합니다.
LLM 추론 패턴 위에 오토스케일링을 구축한 것은 우리가 항상 최대 복제본으로 확장하는 것을 막아 줬습니다. 트래픽이 버스티한 모델의 경우, 오토스케일링이 복제본 수를 실제 수요에 가깝게 유지하여 피크 시점의 정적 프로비저닝 대비 80% 이상의 GPU 절감으로 이어졌습니다.
런타임 신뢰성
스마트한 라우팅과 스케일링은 훌륭한 기반을 제공했지만, 엔진 수준의 장애를 막지는 못합니다. 어떤 추론 엔진(자체 엔진이든 인기 오픈소스 옵션이든)을 배포하더라도, 운영 규모에서는 엣지 케이스와 자원 경합이 나타납니다. 장애를 자동으로 감지·복구하는 메커니즘이 필요합니다.Silent 장애 감지와 복구
우리가 마주치는 한 가지 장애 모드는 silent hang 입니다. 엣지 케이스(구조화 출력, 멀티모달 입력)가 관련된 요청은 추론 엔진의 멀티프로세스 아키텍처에서 미처리 오류를 트리거할 수 있고, 서버가 오류를 표면화하지 않은 채 응답을 멈추게 합니다. 이를 주기적 블랙박스 헬스체크 로 감지합니다 — 최근 실제 요청이 완료되지 않았을 때 전송되는 최소한의 end-to-end 요청. 헬스체크가 실패하면 Kubernetes liveness probe 가 서버를 재시작합니다. 내부 구현과 무관하게 모든 엔진에서 동작합니다. 그러나 높은 부하 아래에서는 헬스체크 자체가 타임아웃되어, 실제로는 정상인 서버를 liveness probe 가 죽이는 일이 발생할 수 있습니다. 이는 연쇄 장애 위험을 만듭니다. 이를 해결하기 위해 헬스체크 요청에 최고 우선순위 스케줄링을 부여하여, 무거운 부하에서도 헬스체크가 완료되도록 했습니다. 우선순위 헬스체크와 함께, 행 감지 → 비정상 서버 종료 → 복구의 전체 사이클이 5분 미만으로 줄었습니다. 거짓 liveness probe 실패는 주당 여러 건에서 0건으로 떨어졌습니다.멀티모달 요청의 예상치 못한 부하 처리
큰 멀티모달 요청 배치가 도착했을 때, 우리는 완전히 다른 출처에서 오류율과 타임아웃의 스파이크를 봤습니다. 조사 결과 요청들이 추론 엔진의 코어 프로세스에 도달하지조차 못하고 있었습니다. 이미지 요청 서빙은 텍스트 전용 요청보다 자원 비용이 더 큽니다 — GPU 위에서 동작하는 추가 비전 인코더뿐 아니라, CPU 집약적 이미지 처리 때문입니다. 특정 모델의 경우 이미지 처리가 극도로 느려 이벤트 루프를 완전히 블로킹했습니다. 블로킹 연산을 별도 스레드와 프로세스로 옮겨도 문제는 해결되지 않았고, 높은 이미지 부하 아래 요청이 계속 쌓였습니다. Python 프로세스를 프로파일링해 다음을 발견했습니다.- 이미지 관련 모든 CPU 연산 중, 이미지 처리(리사이즈 + 정규화)가 base64 디코딩 같은 다른 연산보다 10배 느림.
- 일부 Hugging Face 모델은 PIL 기반 이미지 프로세서를 기본으로 사용하는 반면, 다른 모델은 더 빠른 Torchvision 기반 프로세서를 사용함.
- 컨테이너화된 환경에서,
OMP_NUM_THREADS(Torch 의 CPU 연산용 OpenMP 스레드 수 제어) 가 호스트 머신의 vCPU 수를 기본값으로 사용. 멀티테넌트 셋업에서 이는 형편없는 기본값입니다 — 호스트가 192 vCPU 일 수 있지만 컨테이너는 12 개에만 접근. 결과적으로 가용 코어보다 훨씬 많은 스레드가 동작하고, CPU 사용량이 컨테이너 한도를 넘어 throttling 이 트리거됨.
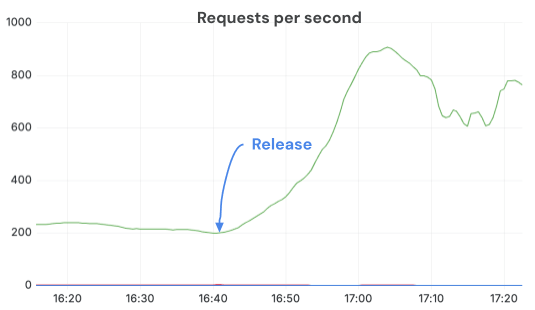
OMP_NUM_THREADS 를 적절히 구성함으로써, 우리는 훨씬 높은 QPS 를 유지하고 GPU 를 완전히 활용했습니다. 수정 출하 후, 동일한 복제본·부하에서 초당 완료 요청 수가 3배 이상 점프했습니다. CPU throttling 이 사라지고 서버가 훨씬 더 건강한 상태로 동작했습니다.