원문: Introducing Apache Spark 4.0

참고 Free Edition이 Community Edition을 대체하여, 비용 없이 더 향상된 기능을 제공합니다. 지금 바로 Free Edition 을 사용해 보세요.Apache Spark 4.0은 Spark 분석 엔진 발전 역사에서 중요한 이정표입니다. 이번 릴리스는 SQL 언어 기능 강화와 연결성 확장부터 새로운 Python 기능, 스트리밍 개선, 사용성 향상까지 전 영역에 걸쳐 획기적인 발전을 이루었습니다. Spark 4.0은 기존 Spark 워크로드와의 호환성을 유지하면서도 그 어느 때보다 강력하고, ANSI 표준을 준수하며, 사용자 친화적인 플랫폼으로 설계되었습니다. 이 포스트에서는 Spark 4.0에 도입된 주요 기능과 개선 사항을 설명하고, 빅데이터 처리 경험을 어떻게 향상시키는지 소개합니다. Spark 4.0의 주요 하이라이트:
- SQL 언어 기능 강화: 세션 변수와 제어 흐름을 갖춘 SQL 스크립팅, 재사용 가능한 SQL User-Defined Function (UDF), 복잡한 분석 워크플로를 간소화하는 직관적인 PIPE 구문 등 새로운 기능이 추가되었습니다.
- Spark Connect 기능 강화: Spark의 새로운 클라이언트-서버 아키텍처인 Spark Connect가 Spark 4.0에서 Spark Classic과 거의 동등한 기능을 갖추게 되었습니다. 이번 릴리스에서는 Python과 Scala 간 향상된 호환성, Go, Swift, Rust 신규 클라이언트를 포함한 다중 언어 지원, 새로운
spark.api.mode설정을 통한 간소화된 마이그레이션 경로가 추가되었습니다. 개발자는 더 모듈화되고 확장 가능하며 유연한 아키텍처의 이점을 누리기 위해 Spark Classic에서 Spark Connect로 원활하게 전환할 수 있습니다. - 안정성 및 생산성 향상: 기본 활성화된 ANSI SQL 모드는 엄격한 데이터 무결성과 더 나은 상호 운용성을 보장하며, 반정형 JSON 데이터를 효율적으로 처리하는 VARIANT 데이터 타입과 향상된 가시성 및 쉬운 문제 해결을 위한 구조화된 JSON 로깅이 제공됩니다.
- Python API 발전: PySpark DataFrame에서 직접 사용 가능한 네이티브 Plotly 기반 플로팅, 커스텀 Python 배치 및 스트리밍 커넥터를 지원하는 Python Data Source API, 동적 스키마 지원과 더 큰 유연성을 제공하는 다형성 Python UDTF가 추가되었습니다.
- Structured Streaming 발전: 강력하고 내결함성 있는 커스텀 스테이트풀 로직을 위한 새로운 Arbitrary Stateful Processing API
transformWithState(Scala, Java, Python 지원), State Store 사용성 개선, 향상된 디버깅 및 가시성을 위한 새로운 State Store Data Source가 도입되었습니다.
Databricks Runtime 17.0에서 이제 사용 가능
Spark Connect의 주요 개선 사항
Spark 4.0에서 가장 흥미로운 업데이트 중 하나는 Spark Connect 전반의 개선, 특히 Scala 클라이언트의 발전입니다. Spark 4에서는 모든 Spark SQL 기능이 Spark Connect와 Classic 실행 모드 간 거의 완전한 호환성을 제공하며, 극히 일부 차이점만 남아 있습니다. Spark Connect는 사용자 애플리케이션을 Spark 클러스터로부터 분리하는 새로운 클라이언트-서버 아키텍처로, 4.0에서는 그 어느 때보다 강력해졌습니다:- 향상된 호환성: Spark Connect의 Python과 Scala API 호환성이 크게 개선되어, Spark Classic과 Spark Connect 간 전환이 원활해진 것이 Spark 4의 주요 성과입니다. 즉, 대부분의 사용 사례에서
spark.api.mode를connect로 설정하기만 하면 Spark Connect를 활성화할 수 있습니다. Spark의 강력한 쿼리 최적화 및 실행 엔진의 이점을 최대한 활용하기 위해, 새로운 작업과 애플리케이션을 개발할 때는 Spark Connect를 활성화한 상태로 시작하는 것을 권장합니다. - 다중 언어 지원: Spark Connect 4.0은 광범위한 언어와 환경을 지원합니다. Python과 Scala 클라이언트가 완전히 지원되며, Go, Swift, Rust를 위한 새로운 커뮤니티 지원 Connect 클라이언트도 사용 가능합니다. 이 폴리글랏(polyglot) 지원은 개발자가 JVM 에코시스템 밖에서도 Connect API를 통해 자신이 선택한 언어로 Spark를 사용할 수 있음을 의미합니다. 예를 들어, Rust로 작성된 데이터 엔지니어링 애플리케이션이나 Go 서비스가 이제 Spark 클러스터에 직접 연결해 DataFrame 쿼리를 실행할 수 있어, Spark의 활용 범위가 기존 사용자층을 훨씬 넘어서게 됩니다.
SQL 언어 기능
Spark 4.0은 데이터 분석을 간소화하는 새로운 기능을 추가합니다:- SQL User-Defined Function (UDF) – Spark 4.0은 SQL UDF를 도입하여 사용자가 직접 SQL로 재사용 가능한 커스텀 함수를 정의할 수 있게 합니다. 이 함수들은 복잡한 로직을 단순화하고 유지 관리성을 개선하며, Spark의 쿼리 최적화기와 원활하게 통합되어 기존 코드 기반 UDF에 비해 쿼리 성능을 향상시킵니다. SQL UDF는 임시 및 영구 정의를 모두 지원하므로, 팀이 여러 쿼리와 애플리케이션에 걸쳐 공통 로직을 쉽게 공유할 수 있습니다. [블로그 포스트 읽기]
- SQL PIPE 구문 – Spark 4.0은 새로운 PIPE 구문을 도입하여
|>연산자로 SQL 연산을 연결할 수 있게 합니다. 이 함수형 스타일 접근 방식은 변환의 선형 흐름을 가능하게 해 쿼리의 가독성과 유지 관리성을 향상시킵니다. PIPE 구문은 기존 SQL과 완전히 호환되어 현재 워크플로에 점진적으로 채택하고 통합할 수 있습니다. [블로그 포스트 읽기] - 언어, 발음 부호, 대소문자 인식 Collation - Spark 4.0은 STRING 타입에 새로운 COLLATE 속성을 도입합니다. Spark가 정렬 및 비교를 결정하는 방식을 제어하기 위해 다양한 언어 및 지역 인식 collation 중 하나를 선택할 수 있습니다. 또한 collation의 대소문자, 발음 부호, 후행 공백 무시 여부도 결정할 수 있습니다. [블로그 포스트 읽기]
- 세션 변수 - Spark 4.0은 세션 로컬 변수를 도입합니다. 이를 통해 호스트 언어 변수를 사용하지 않고도 세션 내 상태를 유지하고 관리할 수 있습니다. [블로그 포스트 읽기]
- 파라미터 마커 - Spark 4.0은 명명된(
":var") 방식과 익명("?") 방식의 파라미터 마커를 도입합니다. 이 기능을 사용하면 쿼리를 파라미터화하고spark.sql()API를 통해 안전하게 값을 전달할 수 있습니다. 이를 통해 SQL 인젝션의 위험을 완화할 수 있습니다. [문서 보기] - SQL 스크립팅: Spark 4.0에서는 새로운 SQL 스크립팅 기능 덕분에 다단계 SQL 워크플로를 더 쉽게 작성할 수 있습니다. 이제 로컬 변수와 제어 흐름을 포함한 멀티 스테이트먼트 SQL 스크립트를 실행할 수 있습니다. 이 기능 향상으로 데이터 엔지니어는 ETL 로직의 일부를 순수 SQL로 이동할 수 있으며, Spark 4.0은 이전에는 외부 언어나 저장 프로시저로만 가능했던 구문을 지원합니다. 이 기능은 곧 오류 조건 처리 기능이 추가되어 더욱 향상될 예정입니다. [블로그 포스트 읽기]
데이터 무결성 및 개발자 생산성
Spark 4.0은 플랫폼을 더욱 안정적이고 표준을 준수하며 사용자 친화적으로 만드는 여러 업데이트를 도입합니다. 이러한 기능 향상은 개발 및 프로덕션 워크플로를 모두 간소화하여 더 높은 데이터 품질과 빠른 문제 해결을 보장합니다.- ANSI SQL 모드: Spark 4.0에서 가장 중요한 변화 중 하나는 ANSI SQL 모드를 기본으로 활성화하여 Spark를 표준 SQL 의미론에 더 가깝게 맞춘 것입니다. 이 변경은 숫자 오버플로나 0으로 나누기처럼 이전에는 자동 잘림이나 null로 처리되던 연산에 명시적인 오류 메시지를 제공하여 엄격한 데이터 처리를 보장합니다. 또한 ANSI SQL 표준 준수는 상호 운용성을 크게 향상시켜, 다른 시스템에서 SQL 워크로드를 마이그레이션할 때 대규모 쿼리 재작성이나 팀 재교육 없이도 쉽게 작업할 수 있게 합니다. 전반적으로 이 발전은 더 명확하고 안정적이며 이식 가능한 데이터 워크플로를 촉진합니다. [문서 보기]
- 새로운 VARIANT 데이터 타입: Apache Spark 4.0은 반정형 데이터를 위해 특별히 설계된 새로운 VARIANT 데이터 타입을 도입합니다. 이를 통해 단일 컬럼 내에 복잡한 JSON 또는 맵 형태의 구조를 저장하면서도 중첩 필드를 효율적으로 쿼리할 수 있습니다. 이 강력한 기능은 상당한 스키마 유연성을 제공하여, 사전 정의된 스키마에 맞지 않는 데이터를 더 쉽게 수집하고 관리할 수 있게 합니다. 또한 Spark에 내장된 JSON 필드 인덱싱과 파싱은 쿼리 성능을 향상시켜 빠른 조회 및 변환을 가능하게 합니다. 반복적인 스키마 진화 단계의 필요성을 최소화함으로써 VARIANT는 ETL 파이프라인을 단순화하고 더 효율적인 데이터 처리 워크플로를 만들어 냅니다. [블로그 포스트 읽기]
- 구조화된 로깅: Spark 4.0은 디버깅과 모니터링을 단순화하는 새로운 구조화된 로깅 프레임워크를 도입합니다.
spark.log.structuredLogging.enabled=true를 활성화하면 Spark는 타임스탬프, 로그 레벨, 메시지, 전체 MDC(Mapped Diagnostic Context) 컨텍스트와 같은 구조화된 필드를 포함한 각 항목을 JSON 라인으로 로그를 기록합니다. 이 현대적인 형식은 Spark SQL, ELK, Splunk 같은 가시성 도구와의 통합을 단순화하여 로그를 훨씬 쉽게 파싱, 검색, 분석할 수 있게 합니다. [자세히 알아보기]
Python API 발전
Python 사용자들은 Spark 4.0에서 많은 것을 기대할 수 있습니다. 이번 릴리스는 Spark를 더욱 Pythonic하게 만들고 PySpark 워크로드의 성능을 향상시킵니다:- 네이티브 플로팅 지원: PySpark에서의 데이터 탐색이 더 쉬워졌습니다. Spark 4.0은 PySpark DataFrame에 네이티브 플로팅 기능을 추가합니다. 이제 DataFrame에서
.plot()메서드나 관련 API를 호출하여 데이터를 pandas로 수동으로 수집하지 않고도 Spark 데이터에서 직접 차트를 생성할 수 있습니다. 내부적으로 Spark는 기본 시각화 백엔드로 Plotly를 사용하여 차트를 렌더링합니다. 즉, 히스토그램이나 산점도 같은 일반적인 플롯 타입을 PySpark DataFrame 한 줄의 코드로 생성할 수 있으며, Spark는 노트북이나 GUI에서 플로팅할 데이터의 샘플이나 집계를 처리합니다. 네이티브 플로팅을 지원함으로써 Spark 4.0은 탐색적 데이터 분석을 간소화합니다. Spark 컨텍스트를 벗어나거나 별도의 matplotlib/plotly 코드를 작성하지 않고도 데이터셋의 분포와 추세를 시각화할 수 있습니다. 이 기능은 EDA에 PySpark를 사용하는 데이터 과학자들의 생산성을 크게 향상시킵니다. - Python Data Source API: Spark 4.0은 개발자가 배치 및 스트리밍 전용 커스텀 데이터 소스를 완전히 Python으로 구현할 수 있는 새로운 Python DataSource API를 도입합니다. 이전에는 새로운 파일 형식, 데이터베이스, 데이터 스트림을 위한 커넥터를 작성하는 데 종종 Java/Scala 지식이 필요했습니다. 이제 Python으로 리더(reader)와 라이터(writer)를 생성할 수 있어, Spark가 더 광범위한 개발자 커뮤니티에 개방됩니다. 예를 들어, 커스텀 데이터 형식이나 Python 클라이언트만 있는 API가 있다면, 이 API를 사용해 Spark DataFrame 소스/싱크(sink)로 감쌀 수 있습니다. 이 기능은 배치 및 스트리밍 컨텍스트 모두에서 PySpark의 확장성을 크게 향상시킵니다. Python으로 간단한 커스텀 데이터 소스를 구현하는 예제는 PySpark 심화 포스트를 참조하거나, 여기서 예제들을 확인하세요. [블로그 포스트 읽기]
- 다형성 Python UDTF: SQL UDTF 기능을 기반으로, PySpark는 이제 입력에 따라 다른 스키마 형태를 반환할 수 있는 다형성 UDTF를 포함한 Python의 User-Defined Table Function을 지원합니다. 데코레이터를 사용하여 출력 행의 이터레이터를 생성하는 Python 클래스를 UDTF로 만들고, Spark SQL이나 DataFrame API에서 호출할 수 있도록 등록할 수 있습니다. 강력한 측면은 동적 스키마 UDTF입니다. UDTF는 파라미터를 기반으로 즉석에서 스키마를 생성하는
analyze()메서드를 정의할 수 있습니다(예: 출력 컬럼 결정을 위해 설정 파일 읽기). 이 다형성 동작은 UDTF를 매우 유연하게 만들어, 가변 JSON 스키마 처리나 입력을 가변 출력 집합으로 분할하는 시나리오를 가능하게 합니다. PySpark UDTF는 Python 로직이 Spark 실행 엔진 내에서 호출당 전체 테이블 결과를 출력할 수 있게 합니다. [문서 보기]
Streaming 기능 강화
Apache Spark 4.0은 향상된 성능, 사용성, 가시성을 위해 Structured Streaming을 계속 개선합니다:- Arbitrary Stateful Processing v2: Spark 4.0은
transformWithState라는 새로운 Arbitrary Stateful Processing 연산자를 도입합니다. TransformWithState는 객체 지향적 로직 정의, 복합 타입, 타이머 및 TTL 지원, 초기 상태 처리, 상태 스키마 진화 및 기타 다양한 기능을 지원하는 복잡한 운영 파이프라인 구축을 가능하게 합니다. 이 새로운 API는 Scala, Java, Python에서 사용 가능하며, 상태 데이터 소스 리더, 연산자 메타데이터 처리 등 다른 중요한 기능들과 네이티브로 통합됩니다. [블로그 포스트 읽기] - State Data Source - Reader: Spark 4.0은 스트리밍 상태를 테이블로 쿼리하는 기능을 추가합니다. 이 새로운 State Store 데이터 소스는 스테이트풀 스트리밍 집계(카운터, 세션 윈도우 등), 조인 등에서 사용되는 내부 상태를 읽을 수 있는 DataFrame으로 노출합니다. 추가 옵션을 통해 업데이트 단위로 상태 변경을 추적하여 세밀한 가시성을 제공합니다. 이 기능은 스트리밍 작업이 처리하는 상태를 이해하는 데도 도움이 되며, 스트림의 스테이트풀 로직 문제 해결 및 모니터링을 지원하고 기본 손상이나 불변성 위반을 탐지하는 데 도움을 줍니다. [블로그 포스트 읽기]
- State Store 기능 강화: Spark 4.0은 또한 개선된 SST(Static Sorted Table) 파일 재사용 관리, 스냅샷 및 유지 관리 개선, 개편된 상태 체크포인트 형식, 추가적인 성능 향상 등 수많은 State Store 개선 사항을 추가합니다. 이와 함께 더 쉬운 모니터링과 디버깅을 위한 개선된 로깅 및 오류 분류와 관련된 다양한 변경 사항이 추가되었습니다.
감사의 말
Spark 4.0은 Apache Spark 프로젝트의 큰 도약으로, 핵심 개선에서 더 풍부한 API까지 모든 레이어에 걸친 최적화와 새로운 기능을 포함합니다. 이번 릴리스에서 커뮤니티는 5,000개 이상의 JIRA 이슈를 해결했으며, 독립 개발자부터 Databricks, Apple, LinkedIn, Intel, OpenAI, eBay, Netease, Baidu 같은 조직에 이르기까지 약 400명의 개인 기여자들이 이러한 개선을 이끌었습니다. 티켓을 등록하거나, 코드를 리뷰하거나, 문서를 개선하거나, 메일링 리스트에서 피드백을 공유한 모든 기여자에게 진심으로 감사드립니다. SQL, Python, 스트리밍의 주요 개선 사항 외에도, Spark 4.0은 Java 21 지원, Spark K8S 연산자, XML 커넥터, Connect의 Spark ML 지원, PySpark UDF 통합 프로파일링도 제공합니다. 변경 사항의 전체 목록과 기타 모든 엔진 수준의 개선 사항은 공식 Spark 4.0 릴리스 노트를 참조하세요.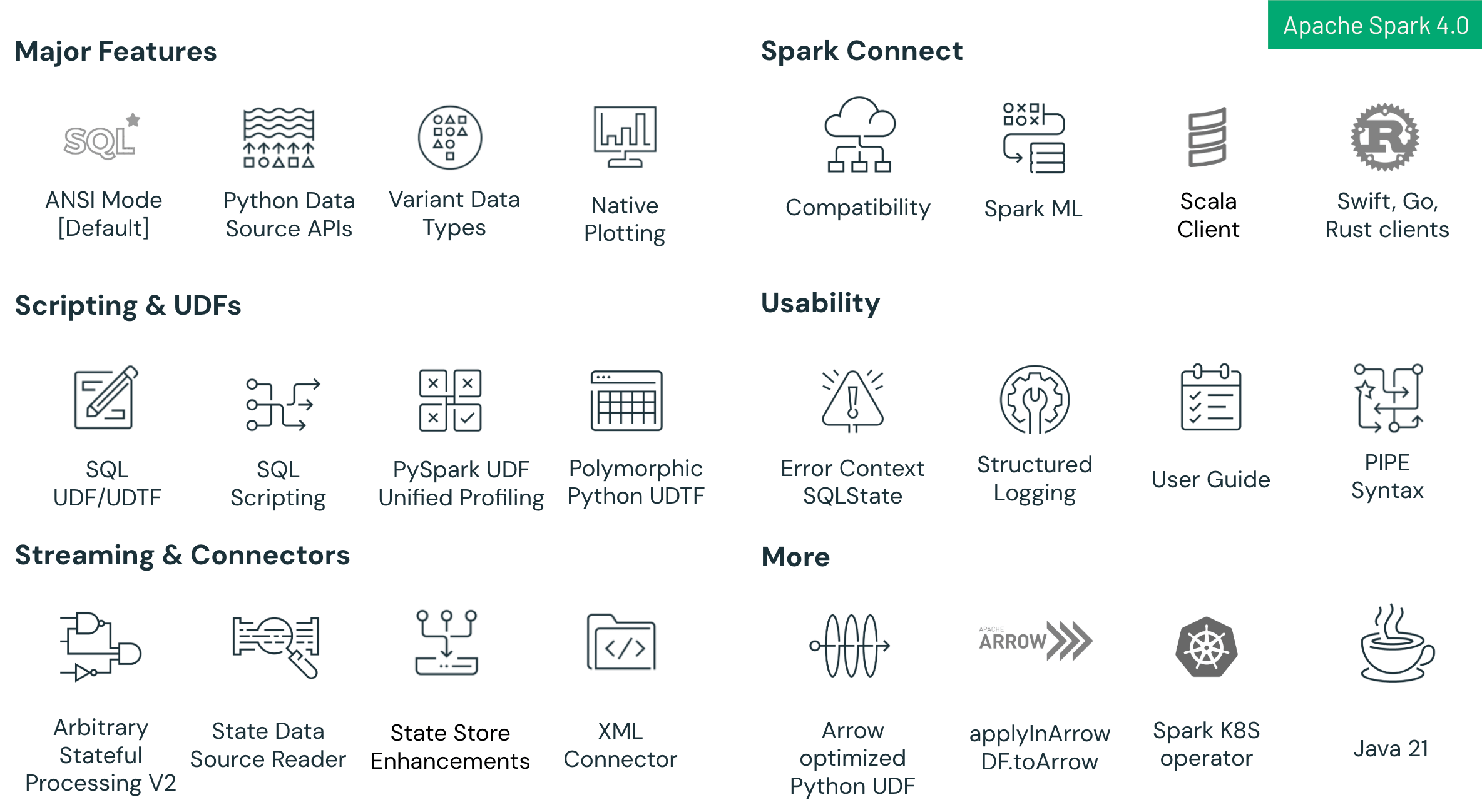 Spark 4.0 받기: 완전한 오픈 소스로, spark.apache.org에서 다운로드할 수 있습니다. 많은 기능이 이미 Databricks Runtime 15.x 및 16.x에서 제공되었으며, 이제 Runtime 17.0에서 기본으로 제공됩니다. 관리된 환경에서 Spark 4.0을 체험해 보려면, Community Edition에 가입하거나 트라이얼을 시작하고, 클러스터 생성 시 “17.0”을 선택하면 몇 분 안에 Spark 4.0을 실행할 수 있습니다.
Spark 4.0 받기: 완전한 오픈 소스로, spark.apache.org에서 다운로드할 수 있습니다. 많은 기능이 이미 Databricks Runtime 15.x 및 16.x에서 제공되었으며, 이제 Runtime 17.0에서 기본으로 제공됩니다. 관리된 환경에서 Spark 4.0을 체험해 보려면, Community Edition에 가입하거나 트라이얼을 시작하고, 클러스터 생성 시 “17.0”을 선택하면 몇 분 안에 Spark 4.0을 실행할 수 있습니다.
 Spark 4.0의 이러한 기능들을 논의한 Spark 4.0 밋업을 놓치셨다면, 여기서 녹화 영상을 시청하실 수 있습니다. 또한 Spark 4.0 기능에 대한 향후 심화 밋업도 기대해 주세요.
Spark 4.0의 이러한 기능들을 논의한 Spark 4.0 밋업을 놓치셨다면, 여기서 녹화 영상을 시청하실 수 있습니다. 또한 Spark 4.0 기능에 대한 향후 심화 밋업도 기대해 주세요.