원문: Introducing LakehouseIQ: The AI-Powered Engine that Uniquely Understands Your Business (2023-06-28)작성자: Ali Ghodsi, Matei Zaharia, Sam Shah, Weston Hutchins, Austin Green
참고: 원래 요청된 URL(introducing-databricksiq)은 현재 404 페이지입니다. 이 포스트가 해당 원본 콘텐츠이며, LakehouseIQ는 이후 DatabricksIQ로 이름이 변경되었습니다.
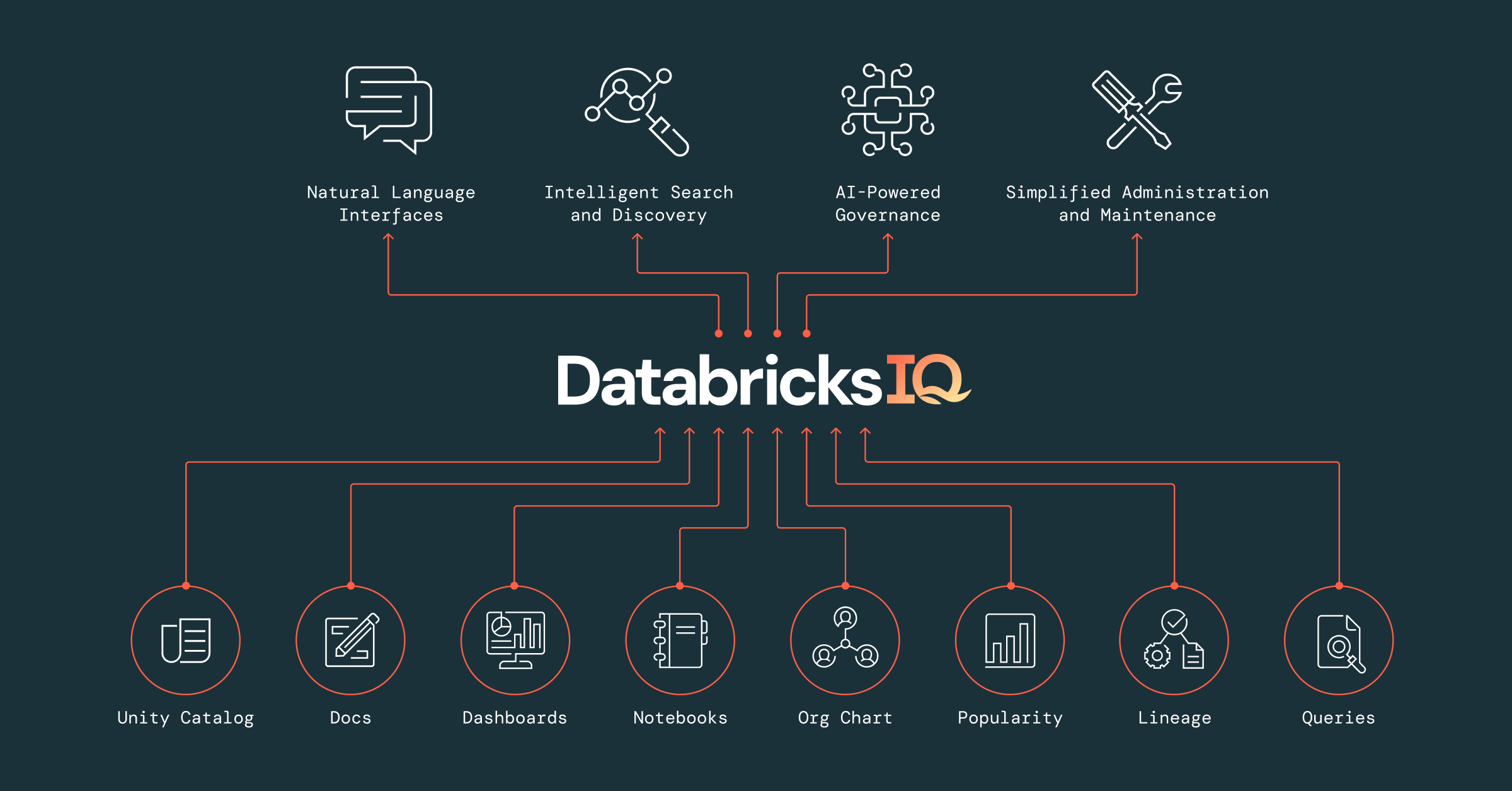 오늘, LakehouseIQ 를 발표하게 되어 매우 기쁩니다. LakehouseIQ는 비즈니스와 데이터의 고유한 뉘앙스를 학습하여 다양한 사용 사례에서 자연어 기반의 데이터 접근을 가능하게 하는 지식 엔진(knowledge engine)입니다. 조직의 모든 구성원이 LakehouseIQ를 통해 자연어로 데이터를 검색하고, 이해하며, 쿼리할 수 있습니다. LakehouseIQ는 데이터, 사용 패턴, 조직도에 관한 정보를 활용하여 비즈니스의 전문 용어와 고유한 데이터 환경을 파악하고, 단순히 Large Language Models(LLMs)를 사용하는 것보다 훨씬 더 정확한 답변을 제공합니다.
물론, Large Language Models은 데이터에 자연어 인터페이스를 제공할 것이라는 기대를 불러일으켰고, 모든 데이터 기업이 AI 어시스턴트를 추가하고 있습니다. 그러나 실제로는 이러한 솔루션 대부분이 기업 데이터에서 기대에 미치지 못합니다. 모든 기업은 비즈니스 질문에 답하기 위해 반드시 필요한 고유한 데이터셋, 전문 용어, 내부 지식을 갖고 있습니다. 인터넷에서 학습된 LLM을 단순히 호출하는 것만으로는 잘못된 결과를 낳습니다. “고객(customer)“의 정의나 회계연도(fiscal year)처럼 단순해 보이는 것조차 기업마다 다르게 정의됩니다.
LakehouseIQ는 기업 내의 비즈니스 및 데이터 개념을 자동으로 학습함으로써 이 문제를 직접 해결하는 최초의 지식 엔진입니다. LakehouseIQ는 Unity Catalog, 대시보드, 노트북, 데이터 파이프라인, 문서 등 Databricks Lakehouse 플랫폼 전반의 신호를 활용하여, Databricks 플랫폼의 엔드투엔드 특성을 통해 실제로 데이터가 어떻게 활용되는지를 파악합니다. 이를 통해 LakehouseIQ는 기업에 특화된 고도로 정확한 모델을 구축합니다.
오늘, LakehouseIQ 를 발표하게 되어 매우 기쁩니다. LakehouseIQ는 비즈니스와 데이터의 고유한 뉘앙스를 학습하여 다양한 사용 사례에서 자연어 기반의 데이터 접근을 가능하게 하는 지식 엔진(knowledge engine)입니다. 조직의 모든 구성원이 LakehouseIQ를 통해 자연어로 데이터를 검색하고, 이해하며, 쿼리할 수 있습니다. LakehouseIQ는 데이터, 사용 패턴, 조직도에 관한 정보를 활용하여 비즈니스의 전문 용어와 고유한 데이터 환경을 파악하고, 단순히 Large Language Models(LLMs)를 사용하는 것보다 훨씬 더 정확한 답변을 제공합니다.
물론, Large Language Models은 데이터에 자연어 인터페이스를 제공할 것이라는 기대를 불러일으켰고, 모든 데이터 기업이 AI 어시스턴트를 추가하고 있습니다. 그러나 실제로는 이러한 솔루션 대부분이 기업 데이터에서 기대에 미치지 못합니다. 모든 기업은 비즈니스 질문에 답하기 위해 반드시 필요한 고유한 데이터셋, 전문 용어, 내부 지식을 갖고 있습니다. 인터넷에서 학습된 LLM을 단순히 호출하는 것만으로는 잘못된 결과를 낳습니다. “고객(customer)“의 정의나 회계연도(fiscal year)처럼 단순해 보이는 것조차 기업마다 다르게 정의됩니다.
LakehouseIQ는 기업 내의 비즈니스 및 데이터 개념을 자동으로 학습함으로써 이 문제를 직접 해결하는 최초의 지식 엔진입니다. LakehouseIQ는 Unity Catalog, 대시보드, 노트북, 데이터 파이프라인, 문서 등 Databricks Lakehouse 플랫폼 전반의 신호를 활용하여, Databricks 플랫폼의 엔드투엔드 특성을 통해 실제로 데이터가 어떻게 활용되는지를 파악합니다. 이를 통해 LakehouseIQ는 기업에 특화된 고도로 정확한 모델을 구축합니다.
 저희는 LakehouseIQ를 활용하여 쿼리에서 트러블슈팅까지, Databricks 전반에 걸친 다양한 자연어 인터페이스를 구동하고 있습니다. 더 중요한 것은, 고객들이 이 자동으로 학습된 지식을 활용하는 자체 AI 앱을 구축할 수 있도록 API를 통해 기능을 공개하고 있다는 점입니다. 저희는 이러한 기업용 지식 엔진이 차세대 소프트웨어 스택의 핵심 구성 요소가 될 것이라고 믿습니다.
저희는 LakehouseIQ를 활용하여 쿼리에서 트러블슈팅까지, Databricks 전반에 걸친 다양한 자연어 인터페이스를 구동하고 있습니다. 더 중요한 것은, 고객들이 이 자동으로 학습된 지식을 활용하는 자체 AI 앱을 구축할 수 있도록 API를 통해 기능을 공개하고 있다는 점입니다. 저희는 이러한 기업용 지식 엔진이 차세대 소프트웨어 스택의 핵심 구성 요소가 될 것이라고 믿습니다.
자연어 쿼리 (Natural Language Queries)
Databricks 사용자들이 처음으로 접하게 될 AI 기능은 쿼리 작성, 쿼리 설명, 질문 응답이 가능한 SQL 에디터 및 노트북의 새로운 Assistant입니다. 이미 사용자들의 수백 시간을 절약해주고 있습니다. Assistant는 각 작업에 적합한 데이터를 찾고 정확한 답변을 제공하기 위해 LakehouseIQ에 크게 의존합니다. LakehouseIQ와 같은 지식 엔진 없이는, LLM이 기업 내에서 데이터가 어떻게 사용되는지 파악하지 못하는 경우가 많습니다. 예를 들어 아래 예시에서, LakehouseIQ를 끈 Assistant는 “Europe”이라는 영업 지역을 검색하여 결과를 찾지 못합니다. 실제로는 해당 기업이 “North”와 “South”라는 두 개의 유럽 지역을 갖고 있음을 알지 못하기 때문입니다. LakehouseIQ를 활성화한 버전은 이 정보를 알고 있을 뿐만 아니라, 이 데이터셋을 사용한 다른 쿼리, 대시보드, 노트북에서 학습하여 내부 사용량을 제외하는 필터를 자동으로 추가합니다.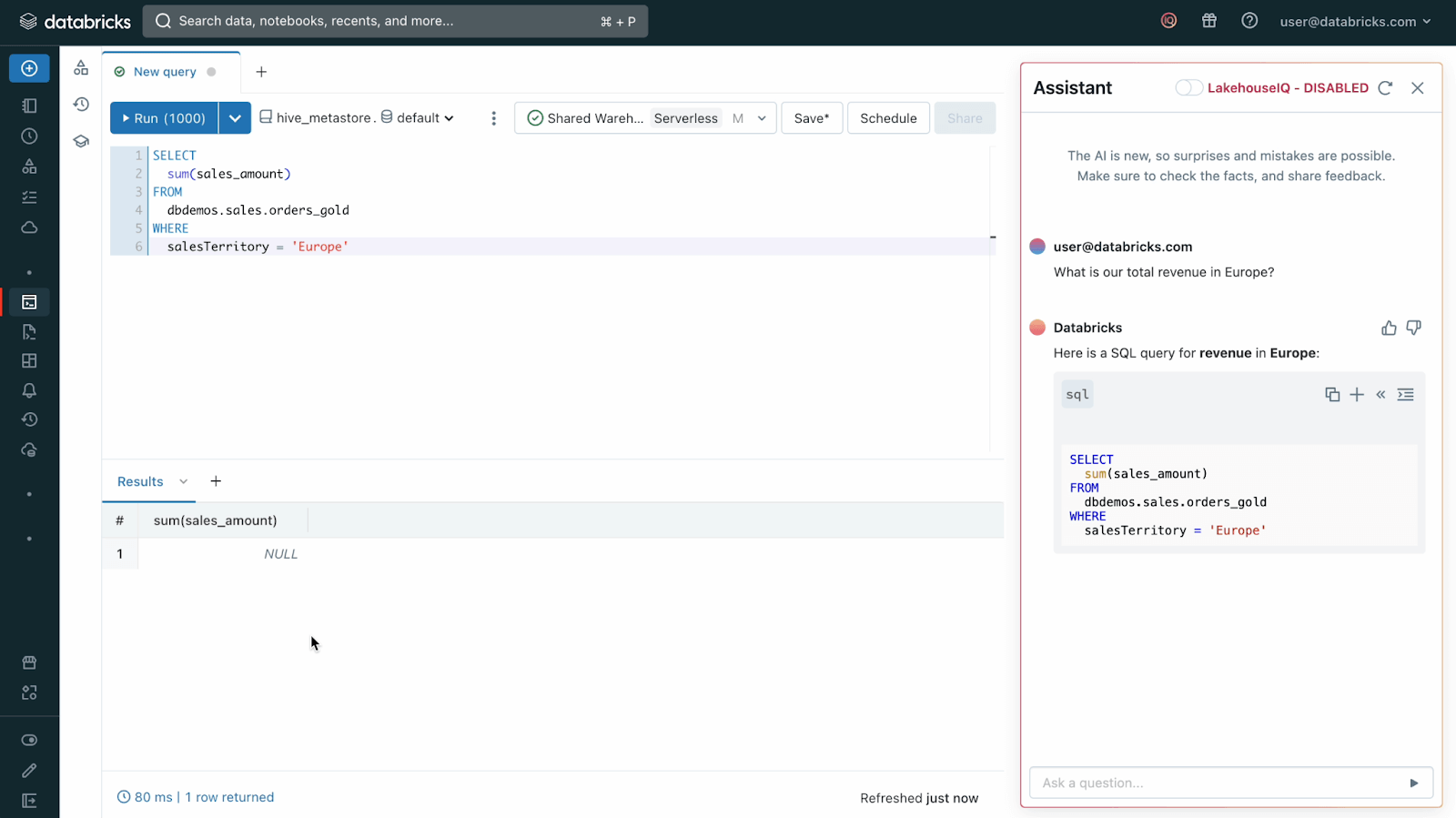
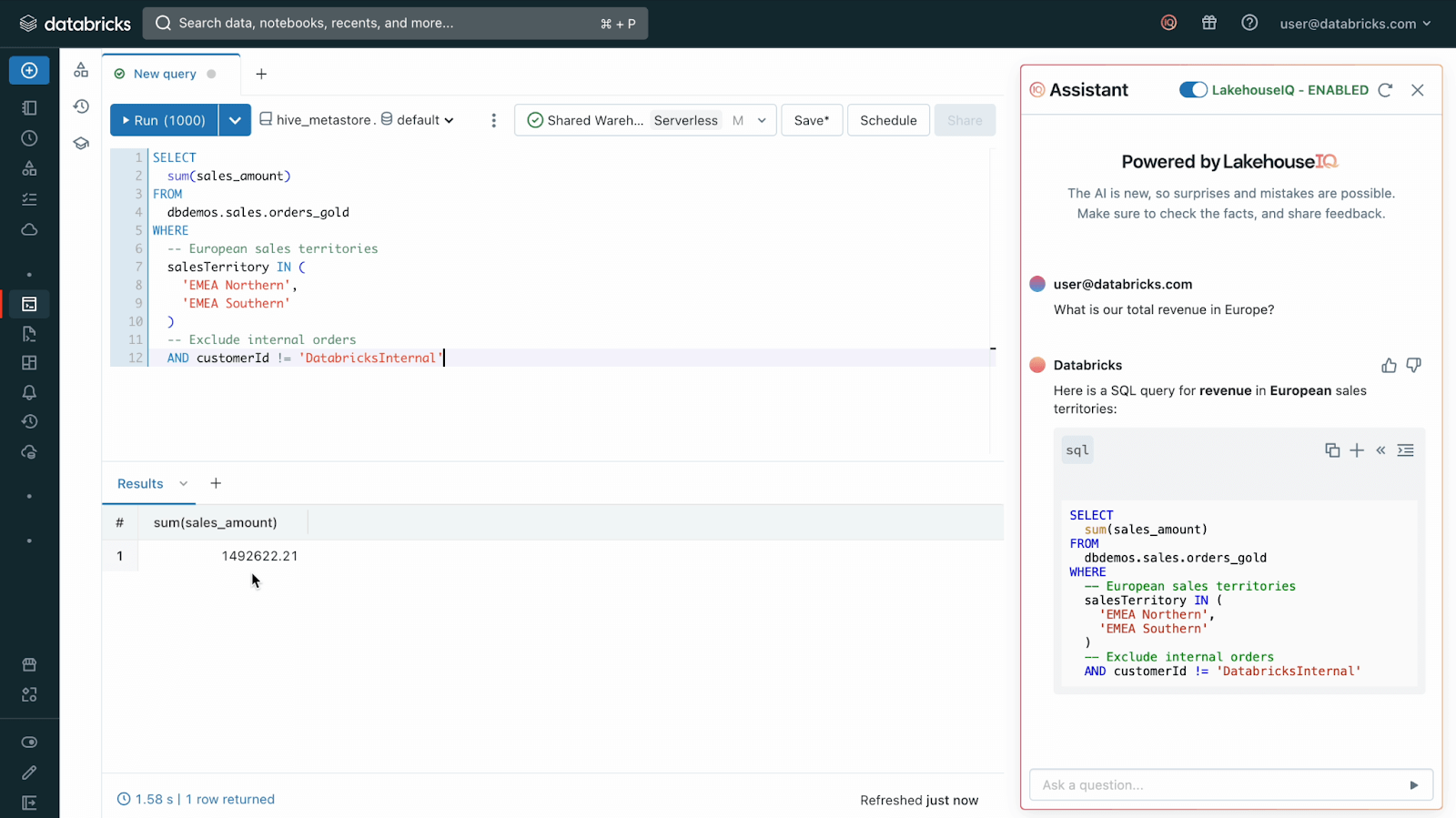
LakehouseIQ를 활용한 검색 (Search with LakehouseIQ)
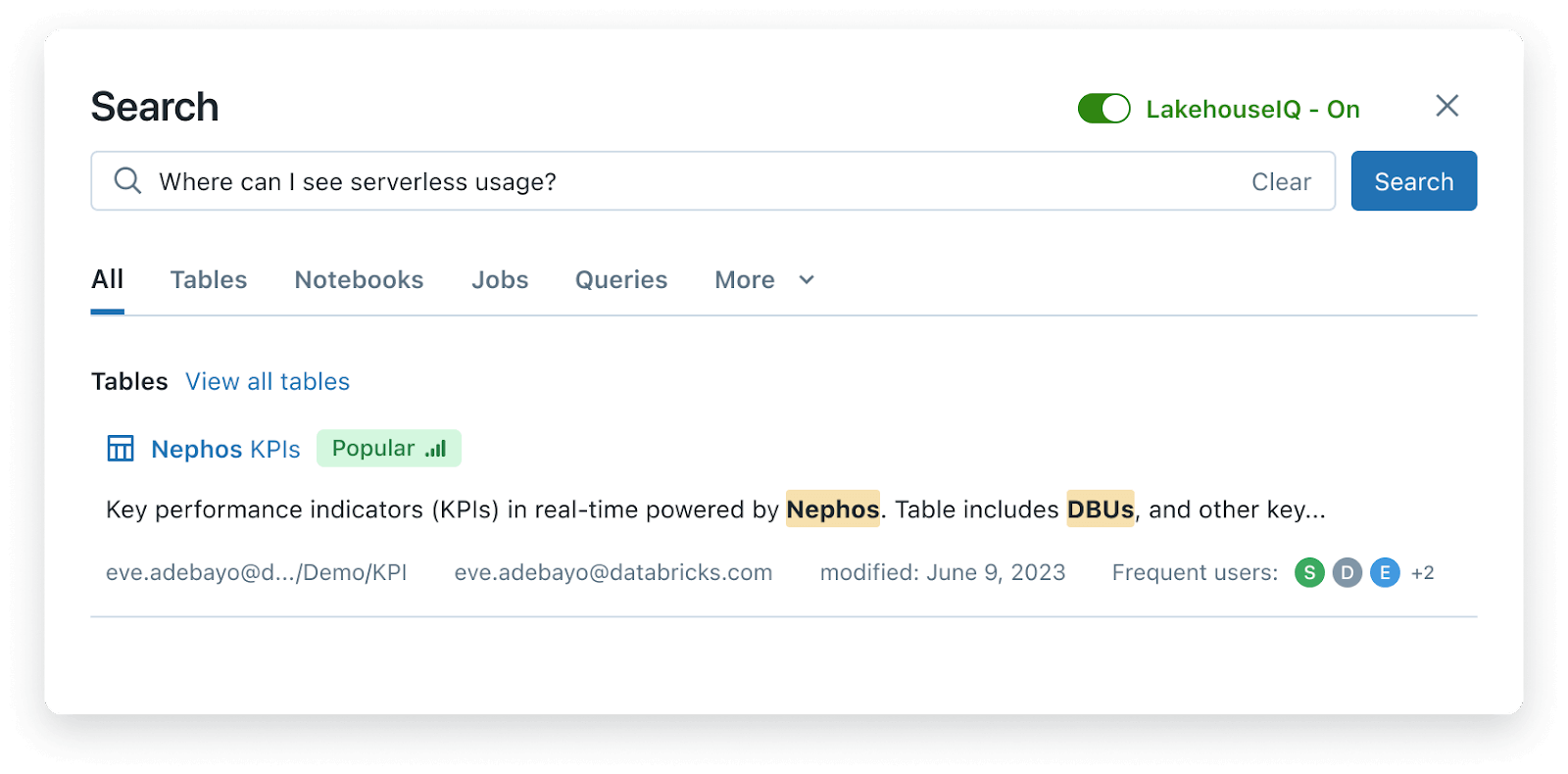
LakehouseIQ는 Databricks의 인프로덕트 Search 기능도 크게 향상시킵니다. 새로운 검색 엔진은 단순히 데이터를 찾는 것을 넘어, 데이터를 해석하고, 정렬하며, 실행 가능한 맥락 있는 형식으로 제시하여 모든 사용자가 데이터를 더 빠르게 활용할 수 있도록 돕습니다. 내부 데이터에 적용한 아래 예시에서, LakehouseIQ는 Databricks에서 serverless의 코드명이 “Nephos”이고, “DBU”는 사용량의 단위임을 이해하여 올바른 결과를 찾아냅니다. 또한 각 테이블에 대한 인기도, 최신성, 자주 사용하는 사용자에 관한 신호도 노출합니다.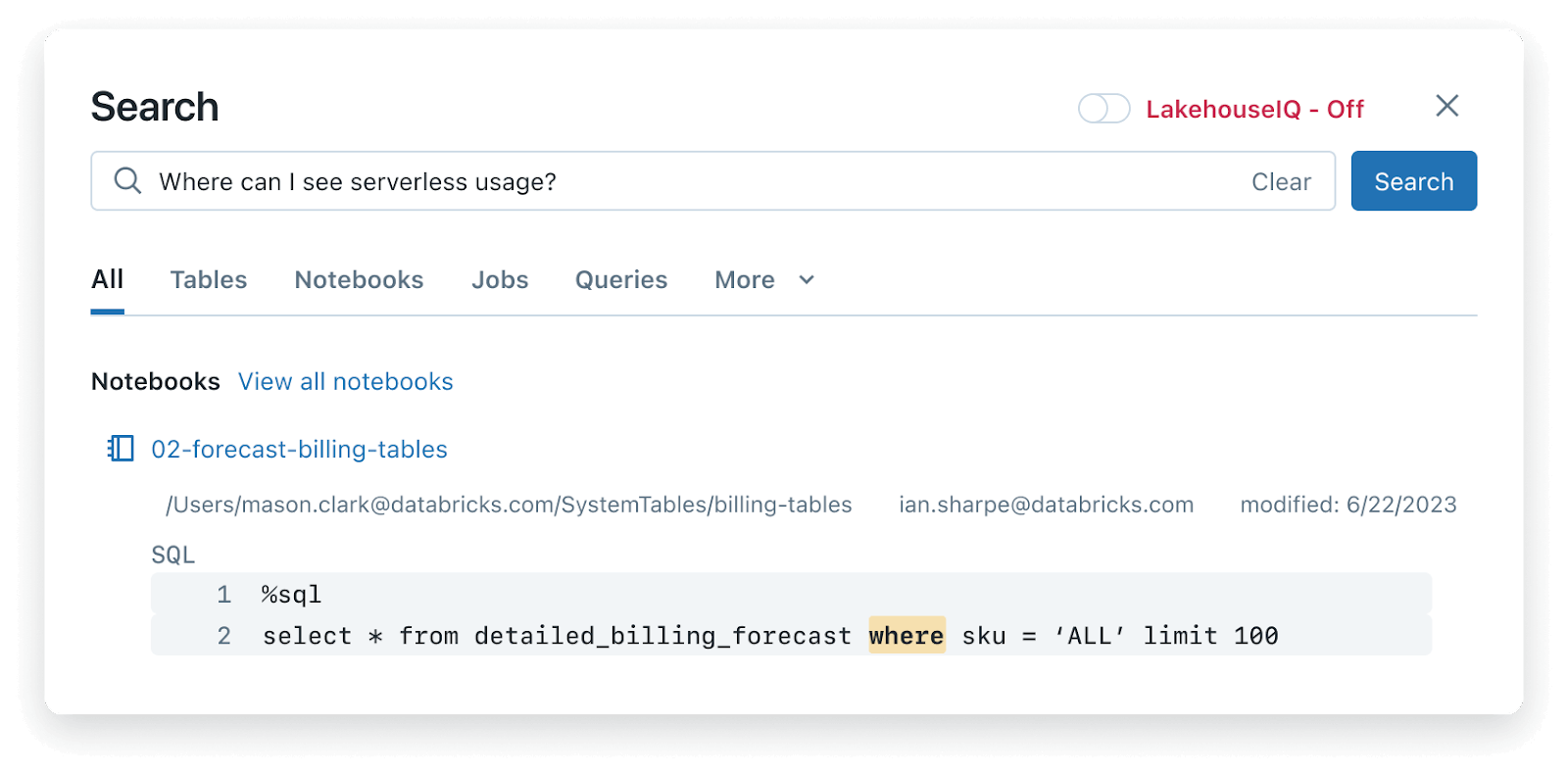
관리 및 트러블슈팅 (Management and Troubleshooting)
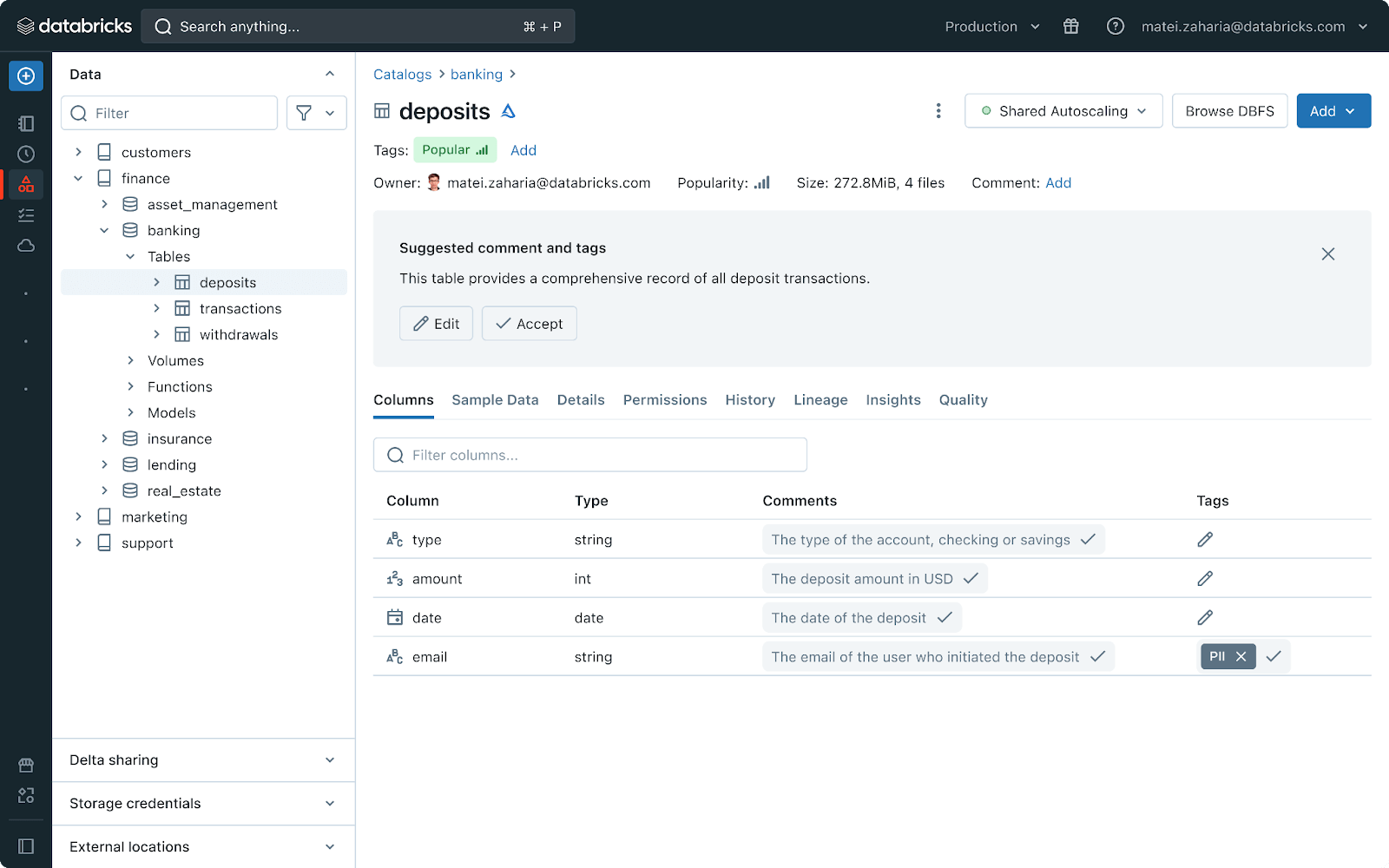
저희는 또한 Lakehouse의 다양한 관리 워크플로우에 LakehouseIQ를 통합하고 있습니다. 예를 들어, 데이터셋에 의미 있는 주석(comment)을 제공하는 작업이 자동 제안을 통해 더 쉬워집니다. 문서화를 더 많이 추가할수록 LakehouseIQ가 해당 데이터를 더 잘 활용할 수 있게 됩니다. LakehouseIQ는 또한 Job, 데이터 파이프라인, Spark 및 SQL 쿼리를 이해하고 디버깅할 수 있습니다(예: 상위 Job이 실패하고 있어 데이터셋이 불완전할 수 있다고 알려주는 것). 이를 통해 사용자는 문제가 발생했을 때 원인을 신속하게 파악할 수 있습니다.