원문: Announcing Mosaic AI Agent Framework and Agent Evaluation (2024-07-02)작성자: Eric Peter, Akhil Gupta, Mani Parkhe, Alkis Polyzotis, Chenen Liang, Maheswaran Venkatachalam, Michael Carbin, Niall Turbitt
프로덕션 품질의 에이전틱 및 검색 증강 생성(RAG) 앱 구축
Databricks는 Data + AI Summit 2024에서 Mosaic AI Agent Framework와 Agent Evaluation의 퍼블릭 프리뷰를 Generative AI Cookbook과 함께 발표했습니다. 이 도구들은 개발자들이 Databricks Data Intelligence Platform 내에서 고품질의 에이전틱(Agentic) 및 검색 증강 생성(RAG, Retrieval Augmented Generation) 애플리케이션을 구축하고 배포할 수 있도록 설계되었습니다.고품질 생성형 AI 애플리케이션 구축의 과제
GenAI 애플리케이션의 개념 증명(PoC)을 구축하는 것은 비교적 간단하지만, 고품질 애플리케이션을 실제로 제공하는 것은 많은 고객들에게 큰 도전으로 증명되었습니다. 고객 대면 애플리케이션에 요구되는 품질 기준을 충족하려면 AI 출력이 정확하고(accurate), 안전하며(safe), 거버넌스를 갖추어야(governed) 합니다. 이 수준의 품질에 도달하기 위해 개발자들은 다음과 같은 어려움을 겪습니다:- 애플리케이션의 품질을 평가하기 위한 올바른 지표 선택
- 애플리케이션 품질을 측정하기 위한 효율적인 사람의 피드백 수집
- 품질 문제의 근본 원인 파악
- 프로덕션 배포 전 애플리케이션 품질을 빠르게 개선하기 위한 반복(iteration)
Mosaic AI Agent Framework와 Agent Evaluation 소개
Databricks AI Research 팀과의 긴밀한 협업을 통해 구축된 Agent Framework와 Agent Evaluation은 이러한 과제들을 해결하기 위해 특별히 설계된 여러 기능을 제공합니다. 빠른 사람 피드백 수집 — Agent Evaluation을 통해 GenAI 애플리케이션의 고품질 답변이 어떤 모습이어야 하는지 정의할 수 있습니다. Databricks 사용자가 아닌 조직 내 도메인 전문가들을 초대해 애플리케이션 응답의 품질을 검토하고 피드백을 제공하도록 할 수 있습니다. GenAI 애플리케이션의 손쉬운 평가 — Agent Evaluation은 Databricks AI Research와 협력하여 개발된 지표(metrics) 모음을 제공하여 애플리케이션의 품질을 측정합니다. 응답과 사람의 피드백을 자동으로 평가 테이블에 기록하고 결과를 빠르게 분석하여 잠재적인 품질 문제를 식별할 수 있습니다. 시스템 제공 AI 심사위원(AI judges)은 정확성, 환각(hallucination), 유해성(harmfulness), 유용성(helpfulness) 등 일반적인 기준에 따라 응답을 평가하며, 품질 문제의 근본 원인을 파악합니다. 이 심사위원들은 도메인 전문가의 피드백을 사용하여 보정(calibration)되지만, 사람의 레이블 없이도 품질을 측정할 수 있습니다. 그런 다음 Agent Framework를 사용하여 애플리케이션의 다양한 구성을 실험하고 조정함으로써 이러한 품질 문제를 해결하고, 각 변경 사항이 앱 품질에 미치는 영향을 측정할 수 있습니다. 품질 임계값에 도달하면 Agent Evaluation의 비용 및 지연(latency) 지표를 사용하여 품질/비용/지연 간의 최적 트레이드오프를 결정할 수 있습니다. 빠른 엔드투엔드 개발 워크플로우 — Agent Framework는 MLflow와 통합되어 개발자들이log_model 및 mlflow.evaluate와 같은 표준 MLflow API를 사용하여 GenAI 애플리케이션을 기록하고 품질을 평가할 수 있게 합니다. 품질에 만족하면 MLflow를 사용하여 애플리케이션을 프로덕션에 배포하고 사용자의 피드백을 받아 품질을 더욱 향상시킬 수 있습니다. Agent Framework와 Agent Evaluation은 MLflow 및 Data Intelligence Platform과 통합되어 GenAI 애플리케이션을 구축하고 배포하는 완전한 경로를 제공합니다.
앱 수명 주기 관리(App Lifecycle Management) — Agent Framework는 권한 관리부터 Databricks Model Serving을 통한 배포에 이르기까지 에이전틱 애플리케이션의 수명 주기를 관리하기 위한 간소화된 SDK를 제공합니다.
Agent Framework와 Agent Evaluation을 사용하여 고품질 애플리케이션 구축을 시작하는 데 도움이 되도록, Generative AI Cookbook은 앱을 PoC에서 프로덕션으로 가져가기 위한 모든 단계를 보여주는 확정적인 방법론 가이드이며, 애플리케이션 품질을 높일 수 있는 가장 중요한 구성 옵션 및 접근 방식을 설명합니다.
고품질 RAG 에이전트 구축하기
이 새로운 기능들을 이해하기 위해, Agent Framework를 사용하여 고품질 에이전틱 애플리케이션을 구축하고 Agent Evaluation을 사용하여 품질을 개선하는 예를 살펴보겠습니다. 이 예시에서는 사전 생성된 벡터 인덱스에서 관련 청크를 검색하고 이를 쿼리에 대한 응답으로 요약하는 간단한 RAG 애플리케이션을 구축하고 배포합니다. LangChain을 포함한 어떤 프레임워크나 네이티브 Python 코드를 사용하여 RAG 애플리케이션을 구축할 수 있지만, 이 예에서는 LangChain을 사용합니다.1단계: MLflow 트레이싱 활성화
먼저 MLflow를 활용하여 트레이싱(tracing)을 활성화하고 애플리케이션을 배포합니다. 세 줄의 간단한 코드를 추가하여 Agent Framework가 트레이스를 통해 애플리케이션을 쉽게 관찰하고 디버깅할 수 있도록 합니다.
2단계: Unity Catalog에 등록 및 PoC 배포
다음 단계는 GenAI 애플리케이션을 Unity Catalog에 등록하고, Agent Evaluation의 리뷰 애플리케이션을 사용하여 이해관계자들의 피드백을 받기 위한 개념 증명(PoC)으로 배포하는 것입니다. 브라우저 링크를 이해관계자들과 공유하면 즉시 피드백 수집을 시작할 수 있습니다. 피드백은 Unity Catalog의 델타 테이블에 저장되며 평가 데이터셋 구축에 사용될 수 있습니다.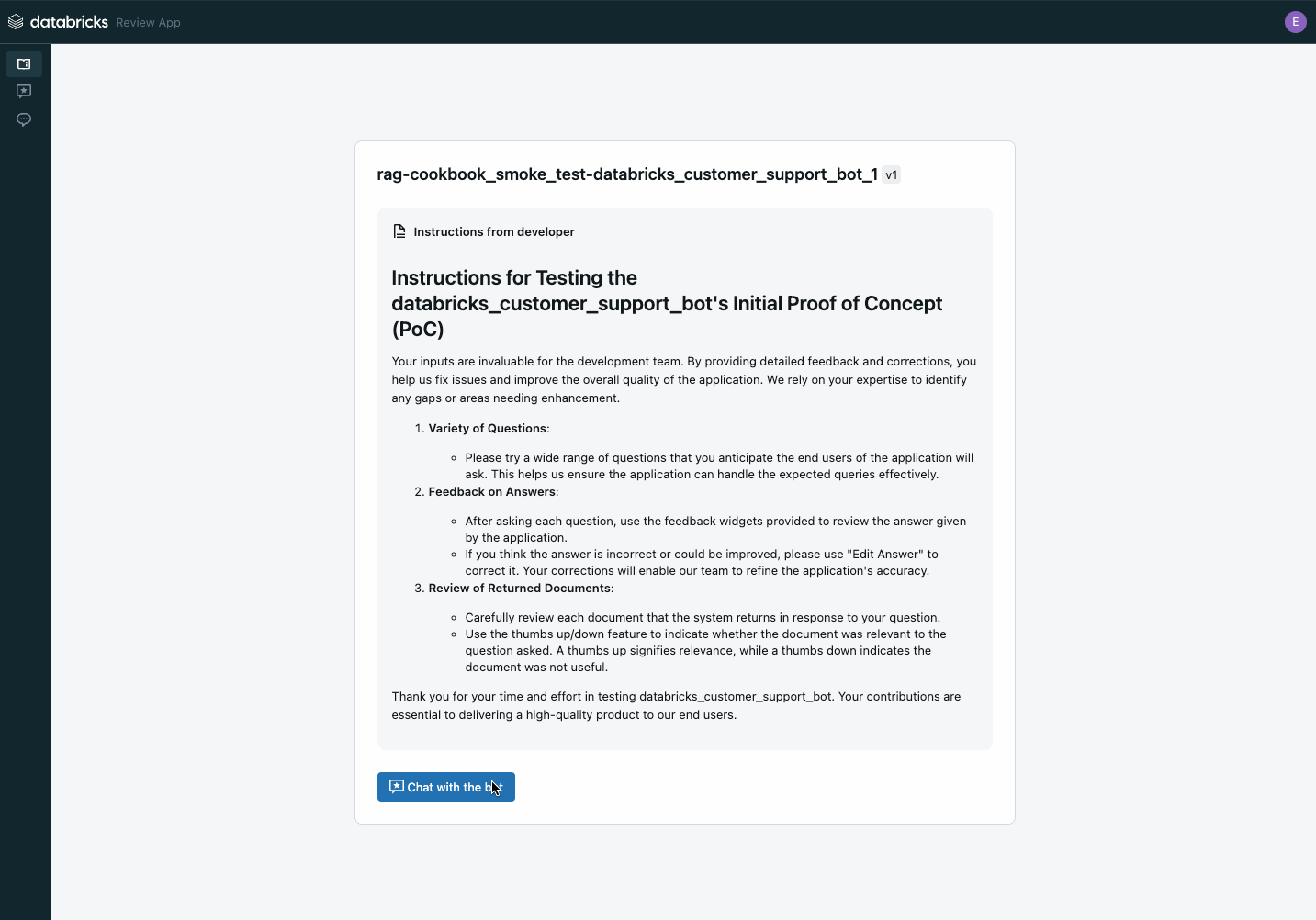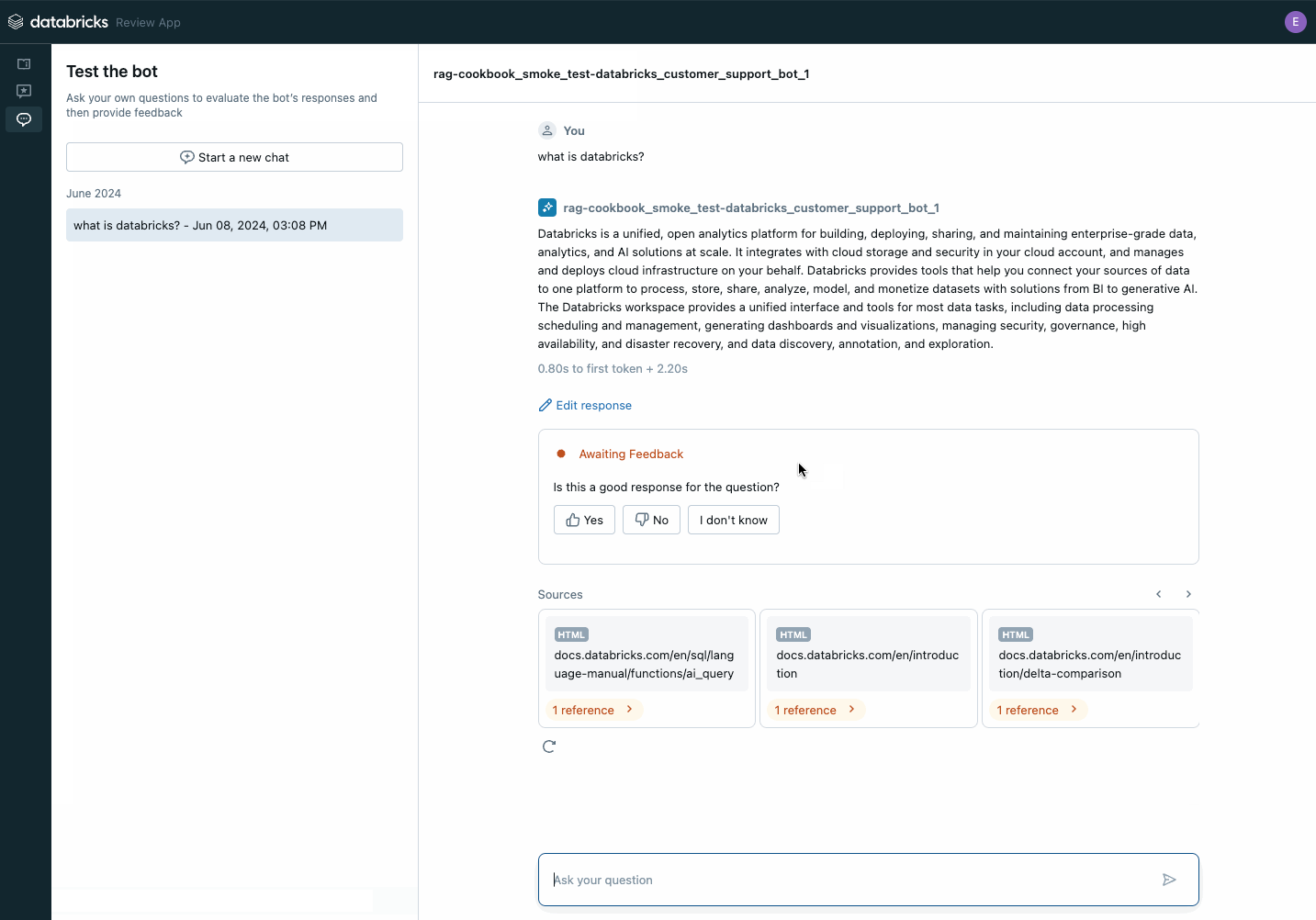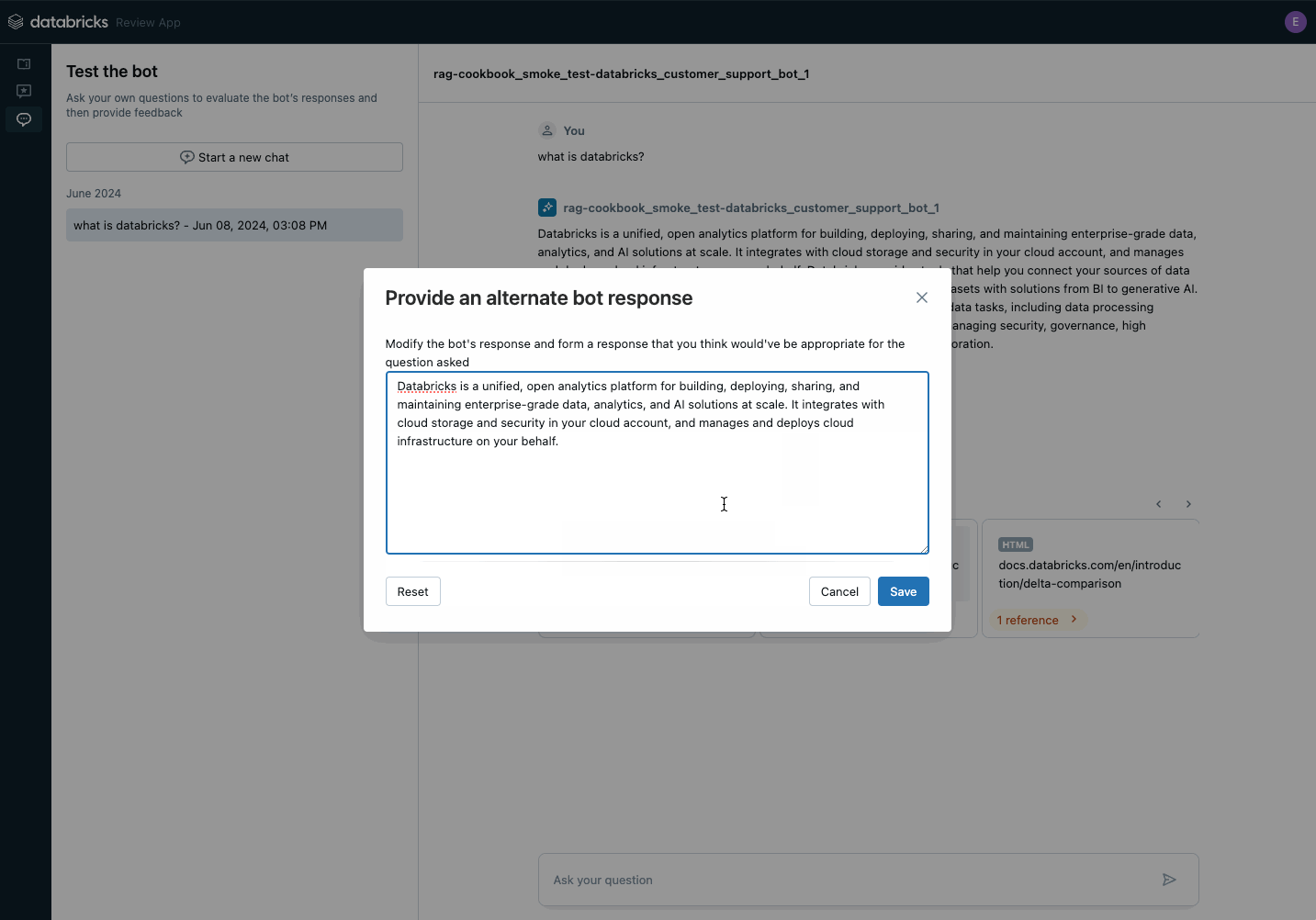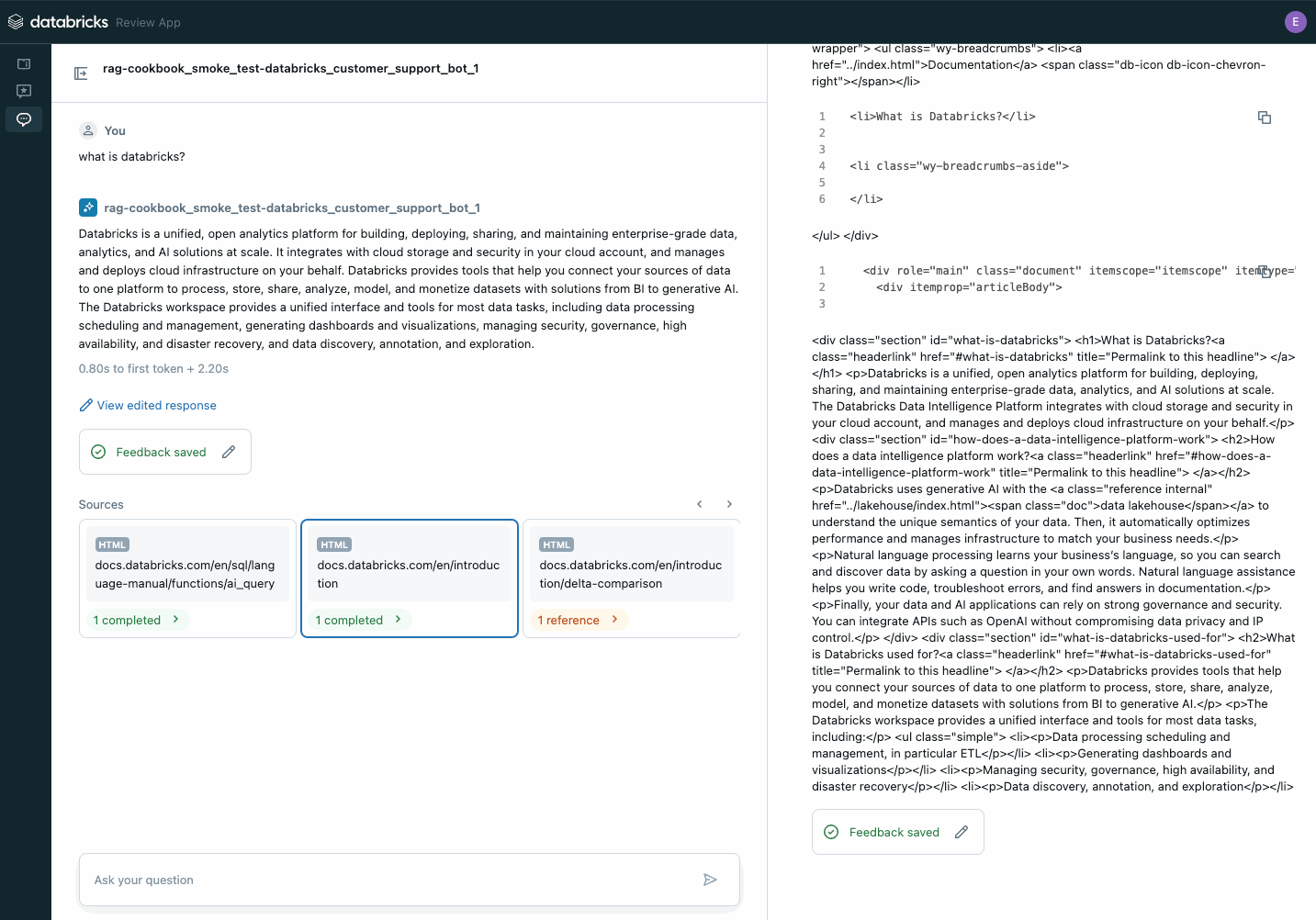
고객 사례 — Corning “Corning은 소재 과학 기업으로, 우리의 유리 및 세라믹 기술은 다양한 산업 및 과학 분야에 사용되며, 데이터를 이해하고 활용하는 것이 필수적입니다. 우리는 Databricks Mosaic AI Agent Framework를 사용하여 수십만 개의 미국 특허청 데이터를 포함한 문서들을 색인화하는 AI 연구 보조 도구를 구축했습니다. LLM 기반 보조 도구가 높은 정확도로 질문에 답변하는 것이 매우 중요했습니다. 이를 구현하기 위해 Databricks Mosaic AI Agent Framework를 활용하여 미국 특허청 데이터로 증강된 생성형 AI 솔루션을 구축했습니다. Databricks Data Intelligence Platform을 활용함으로써 검색 속도, 응답 품질, 정확도를 크게 향상시켰습니다.” — Denis Kamotsky, Principal Software Engineer, Corning
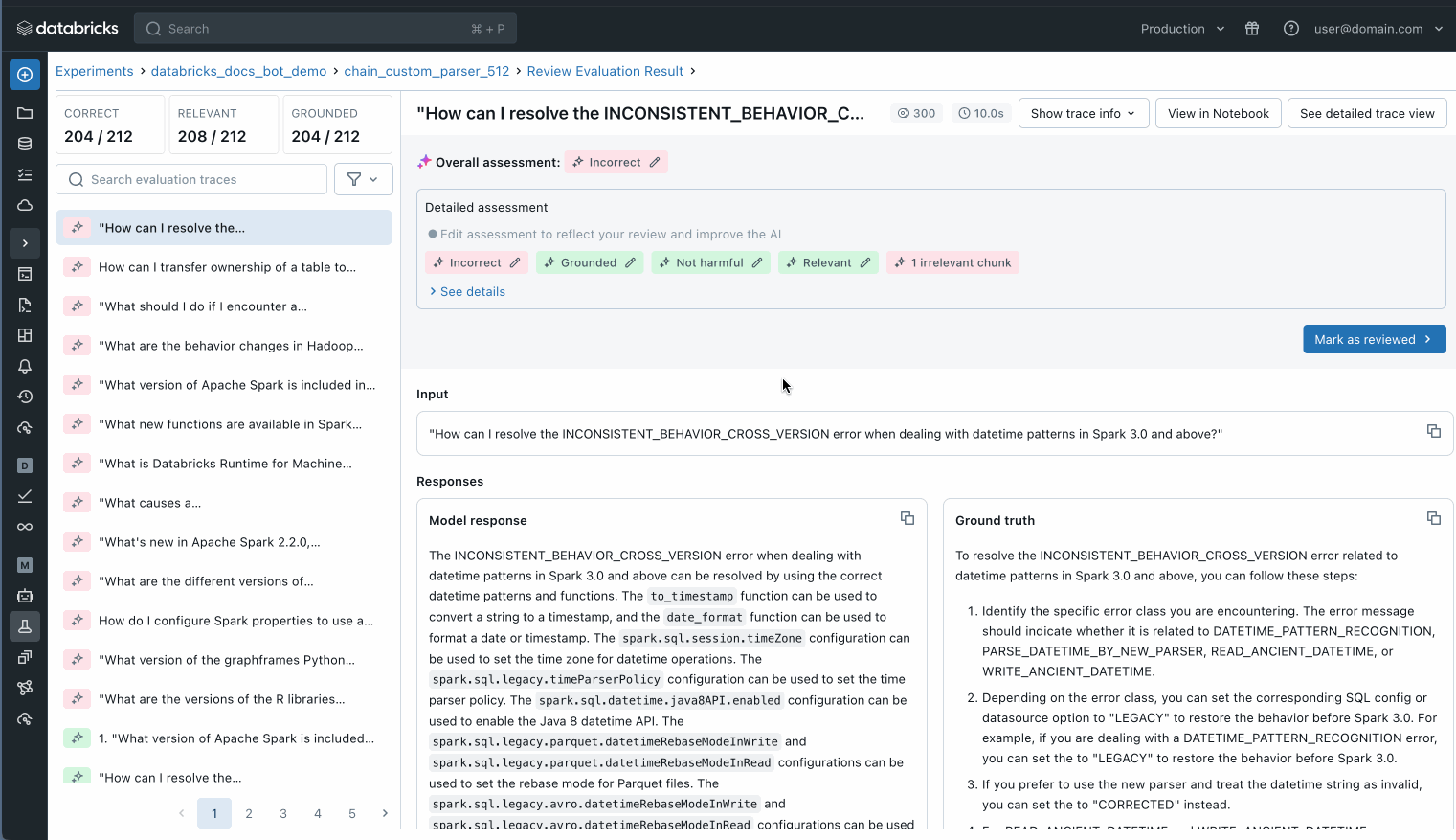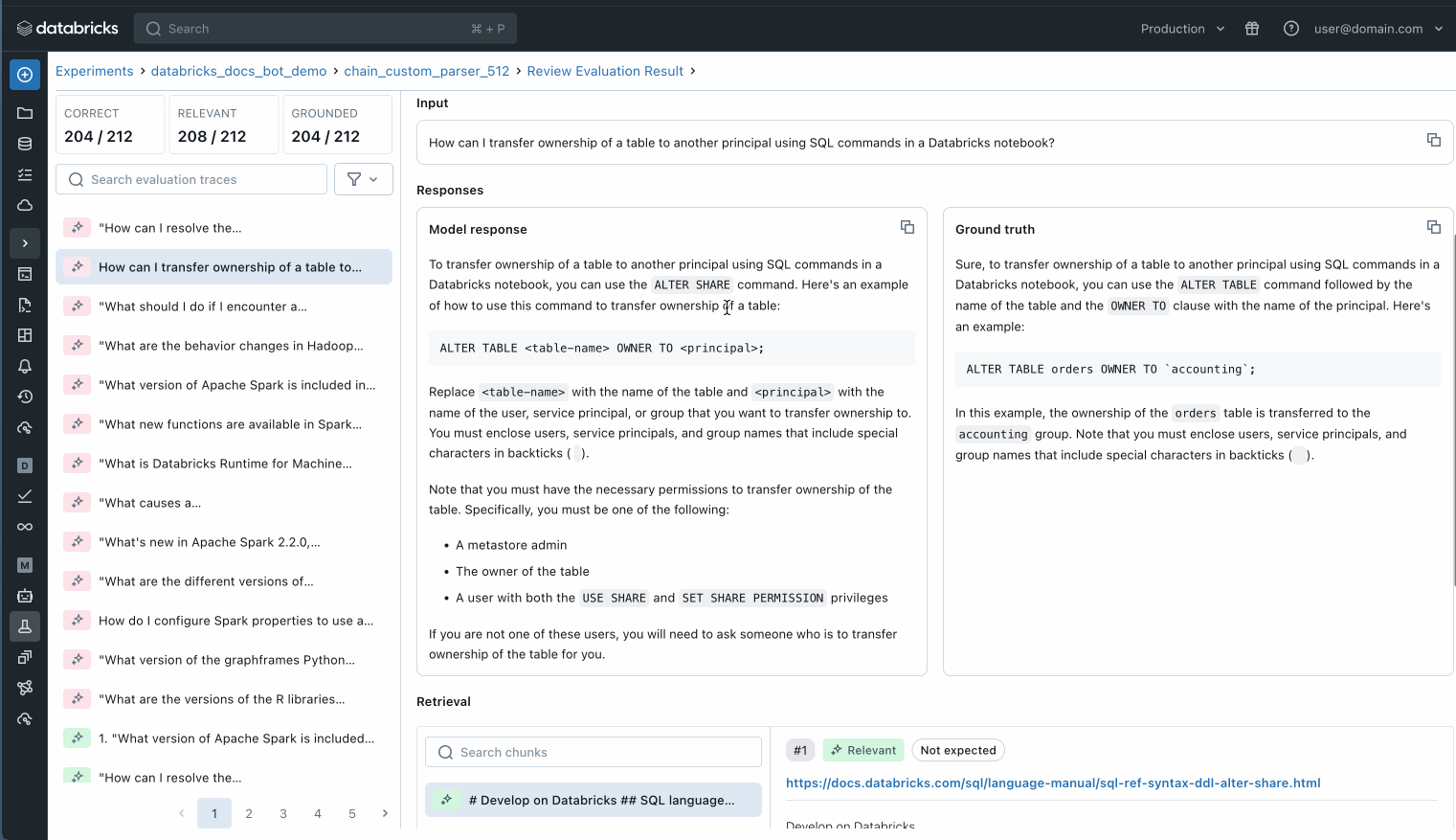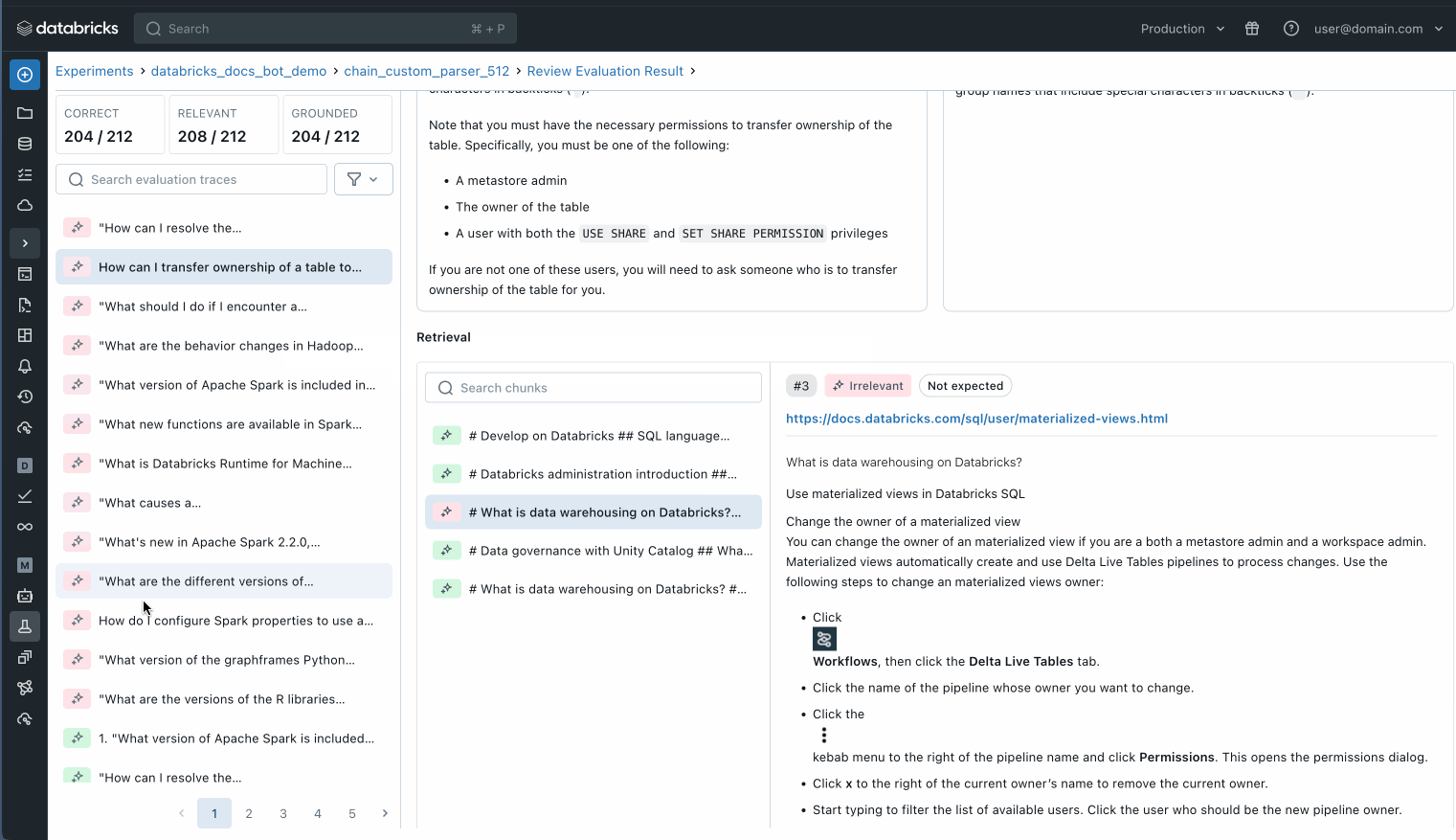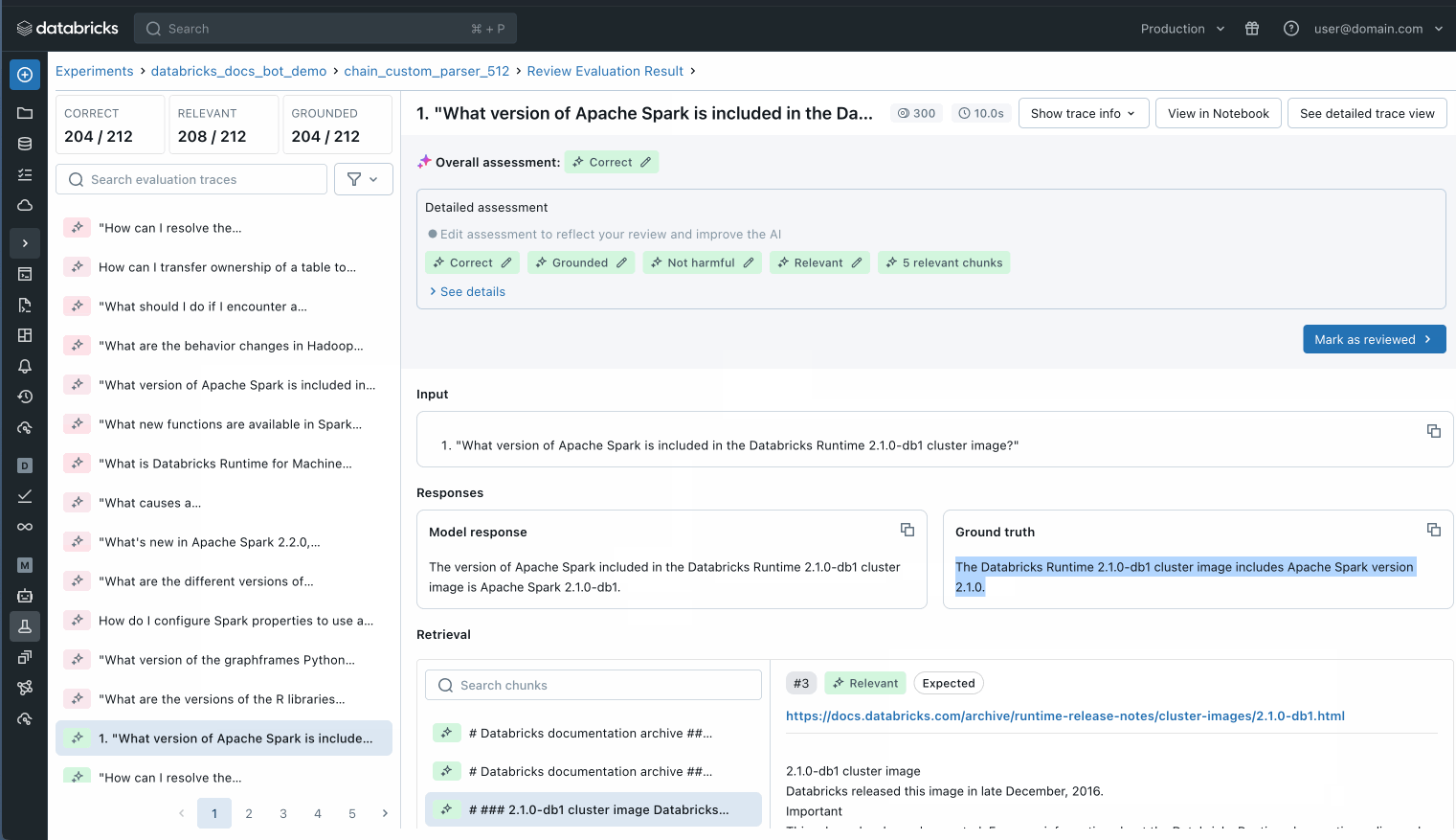
3단계: AI 심사위원으로 품질 평가
평가 데이터셋 구축을 위한 피드백을 받기 시작하면, Agent Evaluation과 내장된 AI 심사위원을 사용하여 다음과 같은 사전 구축된 지표를 기반으로 각 응답의 품질을 검토할 수 있습니다:- 정답 정확성(Answer Correctness) — 앱의 응답이 정확한가?
- 근거성(Groundedness) — 앱의 응답이 검색된 데이터에 기반하는가, 아니면 환각하고 있는가?
- 검색 관련성(Retrieval Relevance) — 검색된 데이터가 사용자의 질문과 관련이 있는가?
- 답변 관련성(Answer Relevance) — 앱의 응답이 사용자의 질문에 적합한가?
- 안전성(Safety) — 앱의 응답에 유해한 콘텐츠가 포함되어 있는가?
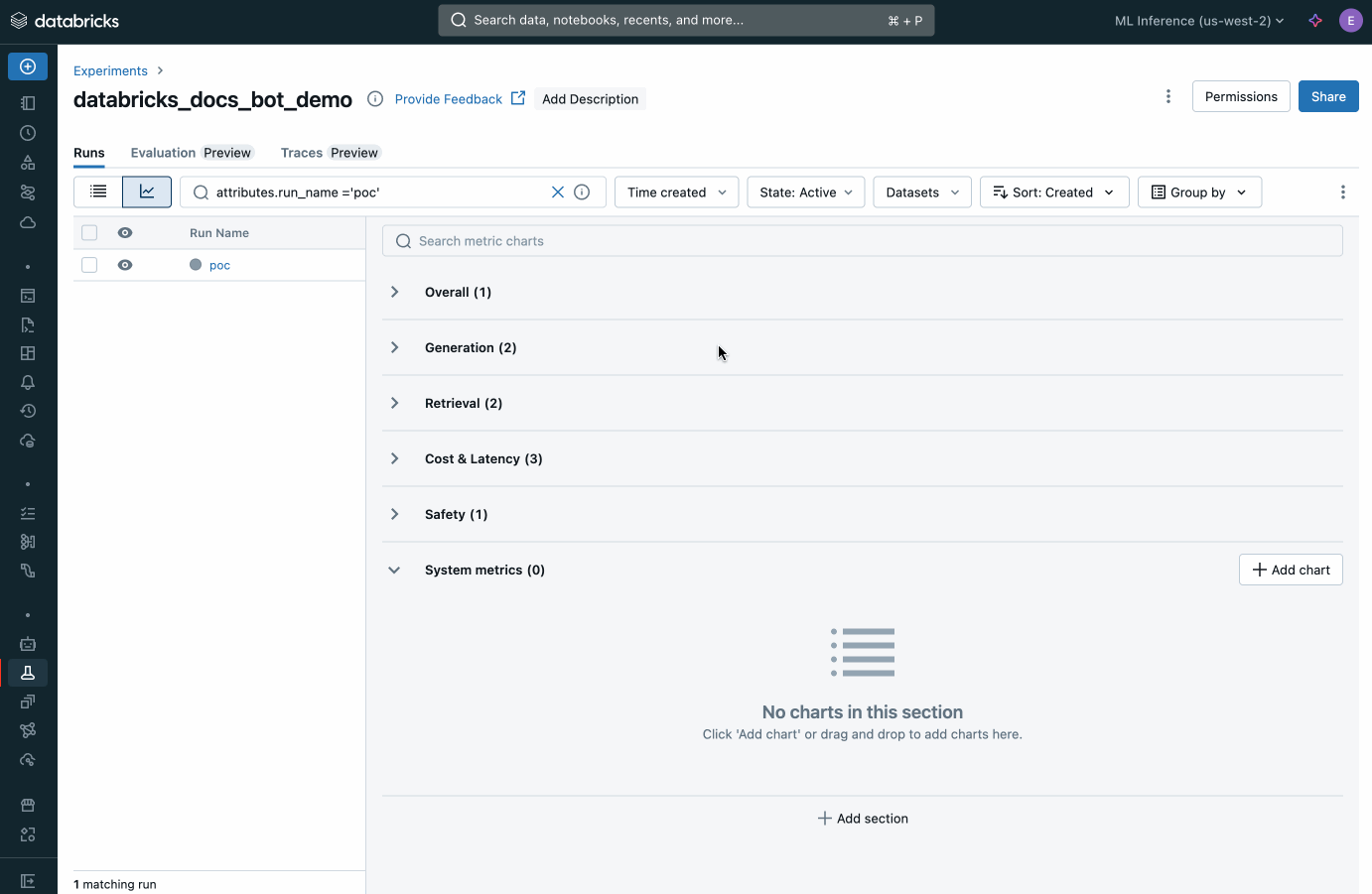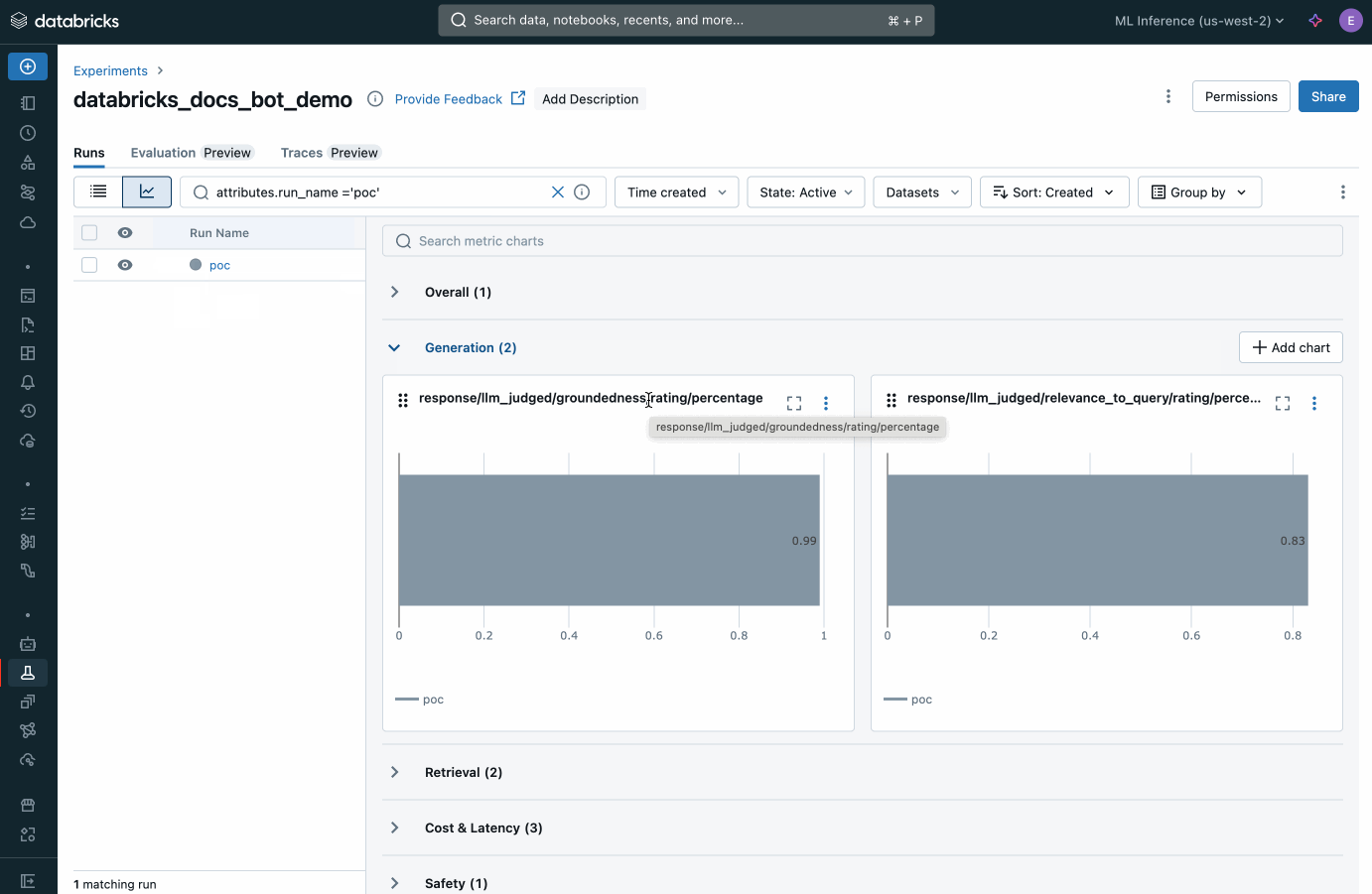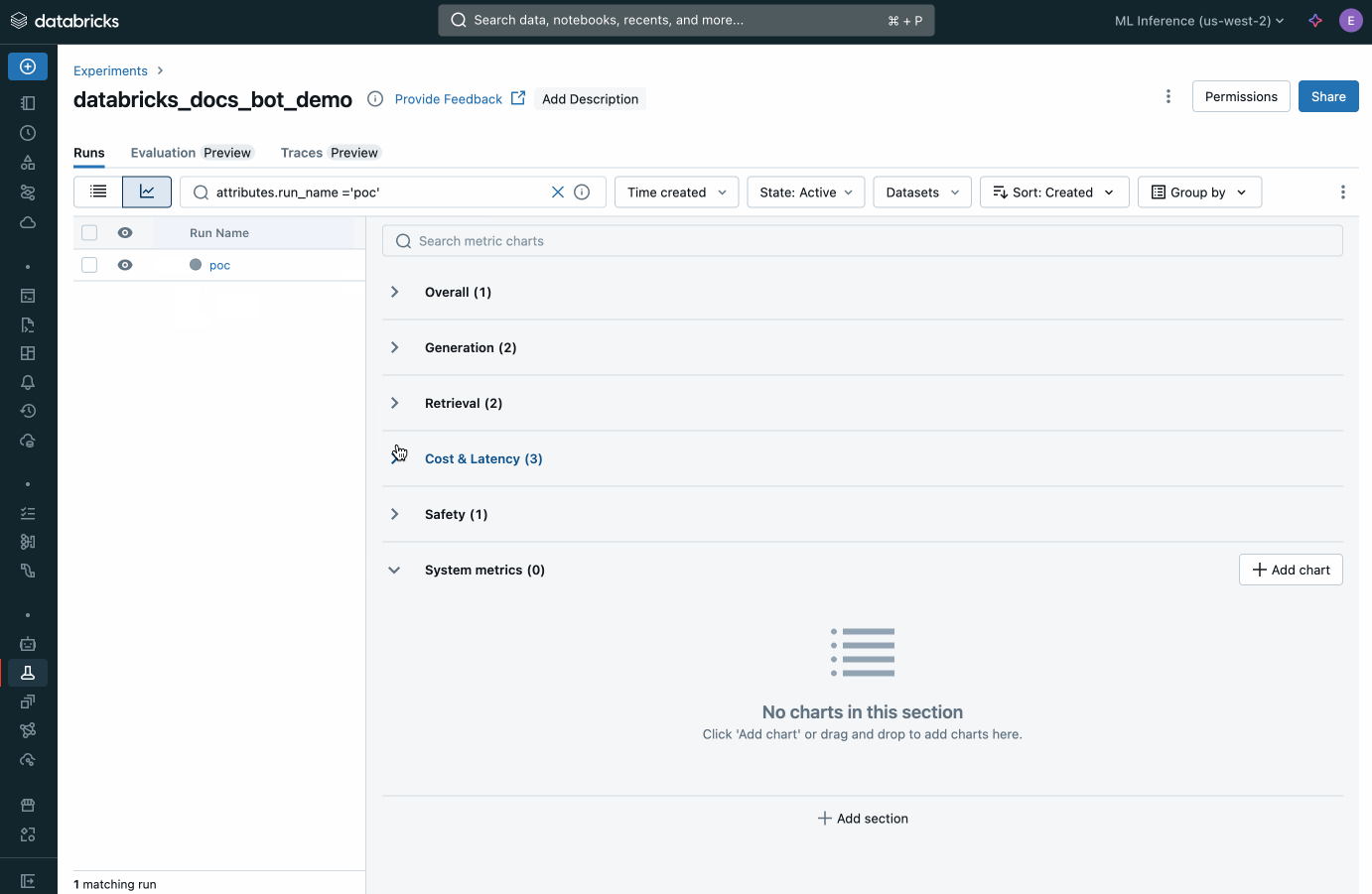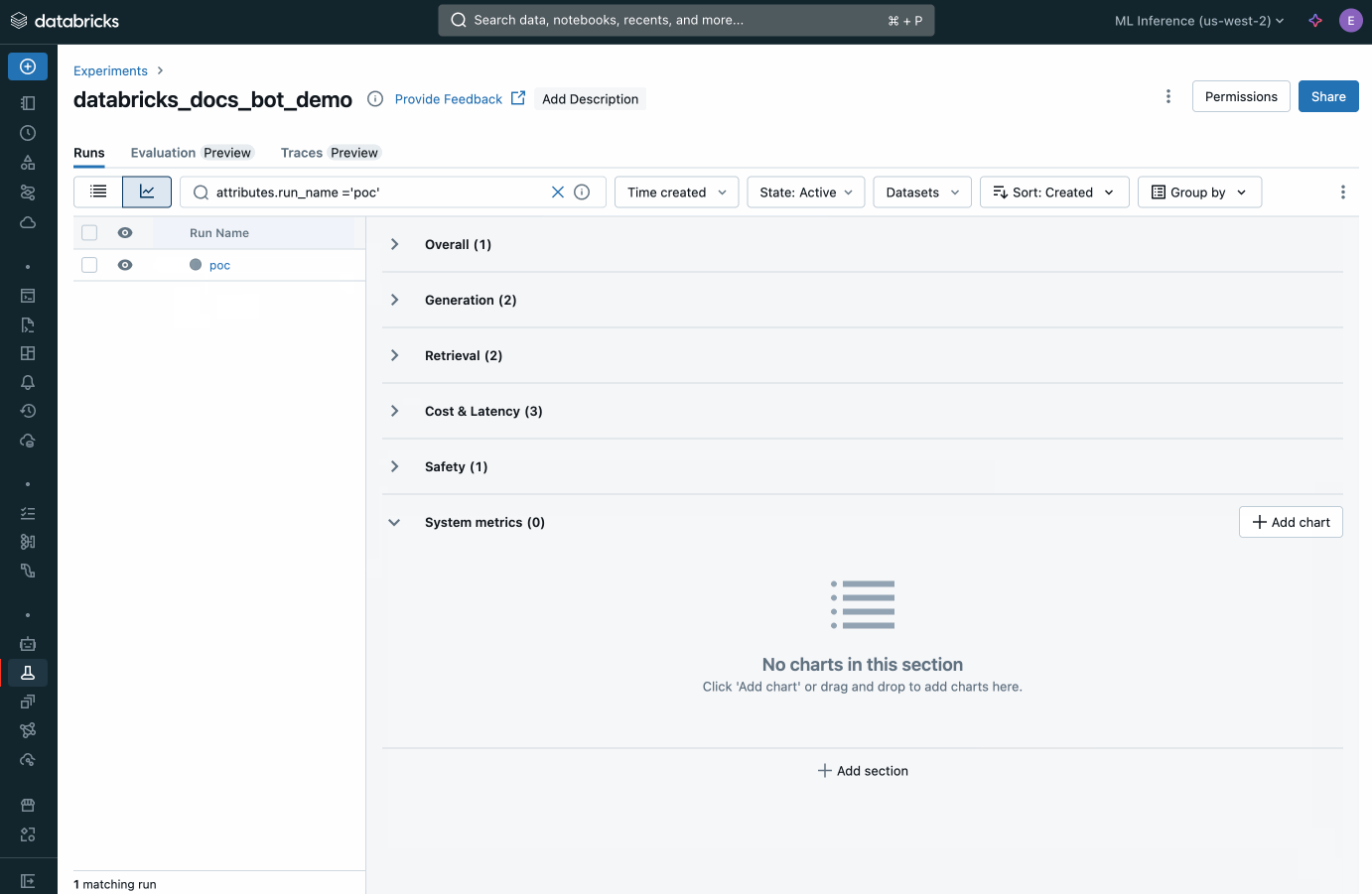 평가 데이터셋의 각 개별 레코드를 검사하여 무슨 일이 일어나고 있는지 더 잘 이해하거나, MLflow 트레이스를 사용하여 잠재적인 품질 문제를 파악할 수도 있습니다.
평가 데이터셋의 각 개별 레코드를 검사하여 무슨 일이 일어나고 있는지 더 잘 이해하거나, MLflow 트레이스를 사용하여 잠재적인 품질 문제를 파악할 수도 있습니다.
고객 사례 — Lippert “글로벌 선도 제조기업인 Lippert는 데이터와 AI를 활용하여 고도로 엔지니어링된 제품, 맞춤형 솔루션, 최고의 경험을 제공합니다. Mosaic AI Agent Framework는 우리에게 결정적인 전환점였습니다. GenAI 애플리케이션의 결과를 평가하고 데이터 소스에 대한 완전한 제어를 유지하면서 출력의 정확도를 입증할 수 있었습니다. Databricks Data Intelligence Platform 덕분에 프로덕션 배포에 자신감을 갖게 되었습니다.” — Kenan Colson, VP Data & AI, Lippert
4단계: 프로덕션 배포
품질을 반복적으로 개선하고 만족스러운 수준에 도달하면, 애플리케이션이 이미 Unity Catalog에 등록되어 있기 때문에 최소한의 노력으로 프로덕션 워크스페이스에 배포할 수 있습니다.고객 사례 — Burberry “Mosaic AI Agent Framework를 통해 모든 개인 데이터가 우리 통제 하에 있다는 확신 속에서 증강된 LLM을 빠르게 실험할 수 있었습니다. MLflow 및 Model Serving과의 원활한 통합으로 ML 엔지니어링 팀이 최소한의 복잡성으로 PoC에서 프로덕션으로 확장할 수 있었습니다.” — Ben Halsall, Analytics Director, Burberry
거버넌스, 추적성, 안전성의 통합
이러한 기능들은 거버넌스를 위해 Unity Catalog와, 계보(lineage) 및 메타데이터 관리를 위해 MLflow와, 안전성을 위해 LLM Guardrails와 긴밀하게 통합되어 있습니다.고객 사례 — FordDirect “FordDirect는 자동차 산업의 디지털 전환을 선도하고 있습니다. 우리는 Ford 및 Lincoln 딜러십의 데이터 허브로서, 딜러들이 실적, 재고, 트렌드, 고객 참여 지표를 평가할 수 있는 통합 챗봇을 만들어야 했습니다. Databricks Mosaic AI Agent Framework를 통해 RAG를 사용하는 생성형 AI 솔루션에 우리의 독자적인 데이터와 문서를 통합할 수 있었습니다. Mosaic AI와 Databricks Delta Tables 및 Unity Catalog의 통합으로 배포된 모델을 건드리지 않고도 소스 데이터가 업데이트될 때 벡터 인덱스를 실시간으로 원활하게 유지할 수 있었습니다.” — Tom Thomas, VP of Analytics, FordDirect
가격 책정
- Agent Evaluation — Judge 요청당 가격 책정
- Databricks Model Serving — Databricks Model Serving 요율에 따라 가격 책정
다음 단계
Agent Framework와 Agent Evaluation은 프로덕션 품질의 에이전틱 및 RAG 애플리케이션을 구축하는 최선의 방법입니다. 시작하려면 다음 리소스를 참조하세요:- Agent Framework 문서 (AWS | Azure)
- Agent Framework 및 Agent Evaluation 데모 노트북
- Generative AI Cookbook
- Data + AI Summit 브레이크아웃 세션 다시보기:
- Data + AI Summit의 GenAI 발표 모음