원문: Stop Hand-Coding Change Data Capture Pipelines
참고 요약
- CDC와 SCD 파이프라인이 코드 생성이 쉬워진 지금도 여전히 취약하고 복잡한 이유
- AutoCDC가 SCD Type 1, SCD Type 2, 스냅샷 기반 CDC 패턴을 선언적으로 자동화하는 방법
- 실제 프로덕션 AutoCDC 워크로드에서 얻은 정확성, 성능, 비용 측면의 실질적 개선 효과
“Python으로 Snapshots AutoCDC를 써봤는데, 기존에 1,500줄로 하던 작업을 4줄의 코드로 대체할 수 있다는 사실에 놀랐습니다.” — 포춘 500대 항공우주·방산 기업의 시니어 데이터 엔지니어Change Data Capture(CDC, 변경 데이터 캡처)와 Slowly Changing Dimensions(SCD, 서서히 변화하는 차원)는 현대 분석 및 AI 워크로드의 핵심 기반입니다. 팀들은 이를 통해 운영 데이터가 변경될 때 다운스트림 테이블을 정확하게 유지합니다. 비즈니스의 현재 상태를 파악하거나, 완전한 과거 이력을 보존하는 목적 모두에서 CDC와 SCD가 활용됩니다. 하지만 실제 현장에서 CDC 파이프라인은 구축과 운영이 가장 고통스러운 파이프라인으로 꼽히는 경우가 많습니다. 팀들은 업데이트, 삭제, 늦게 도착하는 데이터를 처리하기 위해 복잡한 MERGE 로직을 직접 작성하는 일을 반복합니다. 스테이징 테이블, 윈도우 함수, 시퀀싱 가정을 겹겹이 쌓아 올리다 보면, 파이프라인이 발전하면서 논리를 추론하기도, 유지하기도 점점 어려워집니다. LLM(대규모 언어 모델)이 이 코드를 더 빠르게 생성할 수 있게 해주긴 합니다만, 올바르게 만들거나 시간이 지나도 정확성을 유지하는 복잡성 자체는 줄어들지 않습니다. 코드를 생성할 수 있어도, 여러분의 데이터를 이해하지는 못하기 때문입니다. 바로 이 문제를 해결하기 위해 AutoCDC 가 설계되었습니다. 각 파이프라인에 로직을 직접 코딩하는 대신, 팀이 원하는 의미 체계(semantics)를 선언하면 플랫폼이 이를 구현합니다. 그러면 Genie Code 는 이 기반 위에서 설계부터 올바른 파이프라인을 생성할 수 있습니다. 이 포스트에서는 데이터 엔지니어와 SQL 전문가들이 매일 마주치는 CDC·SCD 패턴, 이를 직접 구현하는 것이 왜 고통스러운지, 그리고 Lakeflow Spark Declarative Pipelines의 AutoCDC가 이를 선언적으로 자동화하면서 동시에 가격·성능 면에서도 의미 있는 개선을 이끌어내는 방법을 살펴보겠습니다.
CDC와 SCD는 여전히 데이터 엔지니어에게 어렵다
이 패턴들을 잘 이해하는 팀이라도, 처음부터 올바르게 구현하고 시간이 지나도 정확성을 유지하는 것이 실제로 어렵습니다. 데이터 볼륨이 증가하고 유스케이스가 확장될수록 파이프라인은 취약해지고, 정확성 문제는 뒤늦게 드러나며, 작은 변경 하나도 다운스트림 테이블이 손상되지 않도록 신중하게 다시 작성해야 합니다.SCD Type 1 테이블 유지
SCD Type 1 테이블은 최신 상태를 반영하도록 기존 행을 덮어씁니다. 이 “단순한” 경우조차 금방 다음과 같은 문제에 부딪힙니다.- 업데이트가 순서에 어긋나게 도착
- 중복 이벤트를 일관되게 중복 제거해야 함
- 삭제를 올바르게 적용해야 함
- 재시도 및 재처리 전반에 걸쳐 로직이 멱등성(idempotent)을 유지해야 함
MERGE INTO로 시작했다가, 스테이징 테이블·윈도우 함수·시퀀싱 가정이 복잡하게 중첩된 로직으로 발전합니다. 시간이 지날수록 팀은 이 파이프라인을 아예 건드리기를 꺼리게 됩니다.
SCD Type 2 이력 유지
SCD Type 2는 추가적인 복잡성을 수반합니다.- 행 버전과 유효 구간(validity window) 추적
- 이력을 손상시키지 않으면서 늦게 도착하는 업데이트 처리
- 항상 정확히 하나의 “현재” 버전만 존재하도록 보장
다양한 소스에서 변경 데이터 추출
모든 시스템이 깔끔한 CDC 로그를 제공하지는 않습니다. 일부는 네이티브 변경 데이터 피드를 제공하지만, 그렇지 않은 경우도 있습니다. 데이터를 소비하는 팀이 업스트림 데이터베이스를 제어하지 못하는 경우도 많아, 소스 테이블의 연속 스냅샷을 비교해 변경 사항을 재구성해야 합니다. 두 가지 방식을 모두 지원하려면 일반적으로 별도의 수집·처리 로직, 서로 다른 정확성 가정, 유지하고 디버깅해야 할 더 많은 코드 경로가 필요합니다.시간이 지나도 CDC 파이프라인 운영하기
CDC 파이프라인이 올바르게 작동하게 되더라도, 재처리와 백필(backfill), 스키마 진화, 장애 및 재시작이라는 현실에서 살아남아야 합니다. 직접 작성한 CDC 로직은 이러한 현실이 쌓일수록 점점 취약해져, 운영 위험과 유지 비용이 증가합니다.선언적 데이터 엔지니어링으로 복잡한 CDC 패턴 자동화
AutoCDC는 이러한 일반적인 CDC·SCD 패턴을 선언적 추상화 뒤로 표준화하기 위해 설계되었습니다. 변경 사항을 적용하는 방법을 직접 코딩하는 대신, 팀이 원하는 의미 체계를 선언하면 플랫폼이 순서 지정, 상태 관리, 증분 처리를 담당합니다. 아래 표는 CDC 워크로드별로 AutoCDC와 수동 MERGE / 스냅샷 로직을 비교한 것입니다.| CDC 워크로드 | AutoCDC | 수동 MERGE / 스냅샷 로직 |
|---|---|---|
| 현재 상태 테이블 유지 (SCD Type 1) | 선언적 파이프라인 정의가 시퀀싱, 중복 제거, 삭제를 자동으로 처리 | 윈도우 함수와 시퀀싱 규칙이 포함된 커스텀 MERGE 로직 |
| 이력 테이블 유지 (SCD Type 2) | 내장 이력 추적으로 버전 자동 관리 | 레코드 버전을 닫고 삽입하는 다단계 MERGE 로직 |
| 스냅샷 소스에서 변경 추론 | 내장 스냅샷 CDC 지원 | 조인·비교를 통한 수동 스냅샷 diff 파이프라인 |
| 시간 경과에 따른 안정적 운영 (늦은 데이터, 재시도, 재처리) | 자동 순서 지정 및 멱등성 실행 | 커스텀 안전 장치와 추가 로직 필요 |
| 코드 규모 및 운영 복잡성 | 40~200줄 이상의 커스텀 파이프라인 로직 |
변경 데이터 피드(CDF) 소스 처리
변경 데이터 피드(CDF, Change Data Feed)에서 변경 레코드를 처리할 때, AutoCDC는 선언된 시퀀싱 컬럼을 기반으로 순서가 어긋난 레코드를 자동으로 처리하고 업데이트를 올바르게 적용합니다. 실제 동작 방식을 보여주기 위해, 아래의 샘플 CDC 피드를 살펴보겠습니다.| userId | name | city | operation | sequenceNum |
|---|---|---|---|---|
| 124 | Raul | Oaxaca | INSERT | 1 |
| 123 | Isabel | Monterrey | INSERT | 1 |
| 125 | Mercedes | Tijuana | INSERT | 2 |
| 126 | Lily | Cancun | INSERT | 2 |
| 123 | null | null | DELETE | 6 |
| 125 | Mercedes | Guadalajara | UPDATE | 6 |
| 125 | Mercedes | Mexicali | UPDATE | 5 |
| 123 | Isabel | Chihuahua | UPDATE | 5 |
SCD Type 1 유지 자동화 (변경 데이터 피드 소스)
이 예시에서 변경 데이터 피드에는 사용자 테이블의 삽입·업데이트·삭제가 담겨 있습니다. 목표는 각 레코드의 현재 뷰를 유지하는 것으로, 새로운 업데이트가 이전 값을 덮어씁니다. SCD Type 1 출력 테이블:| id | name | city |
|---|---|---|
| 124 | Raul | Oaxaca |
| 125 | Mercedes | Guadalajara |
| 126 | Lily | Cancun |
SCD Type 2 이력 자동화 (변경 데이터 피드 소스)
많은 분석 시스템에서 최신 상태만 유지하는 것으로는 부족합니다. 레코드가 시간에 따라 어떻게 변경되었는지 완전한 이력이 필요합니다. 이것이 SCD Type 2 패턴으로, 각 레코드의 버전이 언제 활성 상태였는지를 나타내는 유효 구간과 함께 저장됩니다. SCD Type 2 출력 테이블:| id | name | city | __START_AT | __END_AT |
|---|---|---|---|---|
| 123 | Isabel | Monterrey | 1 | 5 |
| 123 | Isabel | Chihuahua | 5 | 6 |
| 124 | Raul | Oaxaca | 1 | NULL |
| 125 | Mercedes | Tijuana | 2 | 5 |
| 125 | Mercedes | Mexicali | 5 | 6 |
| 125 | Mercedes | Guadalajara | 6 | NULL |
| 126 | Lily | Cancun | 2 | NULL |
__END_AT = NULL인 레코드가 현재 활성 상태입니다.
이를 수동으로 구현하려면 이전 레코드를 닫고, 새 버전을 삽입하고, 항상 하나의 버전만 활성 상태로 유지하는 다단계 MERGE 로직이 필요합니다. AutoCDC는 이러한 전환을 선언적으로 자동화하여, 업데이트가 순서에 어긋나게 도착하더라도 올바른 결과를 보장하면서 이력 컬럼과 버전 관리 로직을 자동으로 처리합니다.
(전체 코드 예제는 부록 참조)
스냅샷 소스에서 CDC 추론
모든 소스 시스템이 변경 로그를 제공하지는 않습니다. 많은 경우 팀은 소스 테이블의 주기적인 스냅샷을 받아 실행 간에 무엇이 변경되었는지 추론해야 합니다. 기존에는 스냅샷을 수동으로 비교해 삽입·업데이트·삭제를 감지한 뒤 MERGE 로직으로 변경 사항을 적용해야 했습니다. AutoCDC는 스냅샷 기반 CDC를 일급(first-class) 패턴으로 처리하여, 커스텀 diff 로직이나 상태 관리 없이 스냅샷 간의 행 수준 변경을 자동으로 감지하고 증분 적용합니다. 이를 수동으로 구현하려면 스냅샷 간 행 수준 변경을 감지하고, 이전 활성 레코드를 닫고, 업데이트된 유효 구간으로 새 버전을 삽입해야 합니다. AutoCDC는 이러한 변경을 자동으로 도출하고 SCD Type 2 의미 체계를 적용하여, 다단계 merge 로직이나 커스텀 스냅샷 상태 추적 없이 버전 이력을 유지합니다.순서 지정, 상태, 재처리 관리
Lakeflow Spark Declarative Pipelines는 증분 진행 상황을 자동으로 추적하고 순서에 어긋난 데이터를 처리합니다. 파이프라인은 장애에서 복구하고, 과거 데이터를 재처리하고, 시간이 지남에 따라 발전해도 변경 사항을 이중 적용하거나 유실하지 않습니다. 실질적으로 이는 팀이 시퀀싱 로직, 워터마크 부기(bookkeeping), 재처리 안전성을 직접 관리할 필요가 없다는 것을 의미합니다. 플랫폼이 이 모든 것을 처리합니다.새로운 소식: 대폭적인 가격·성능 개선
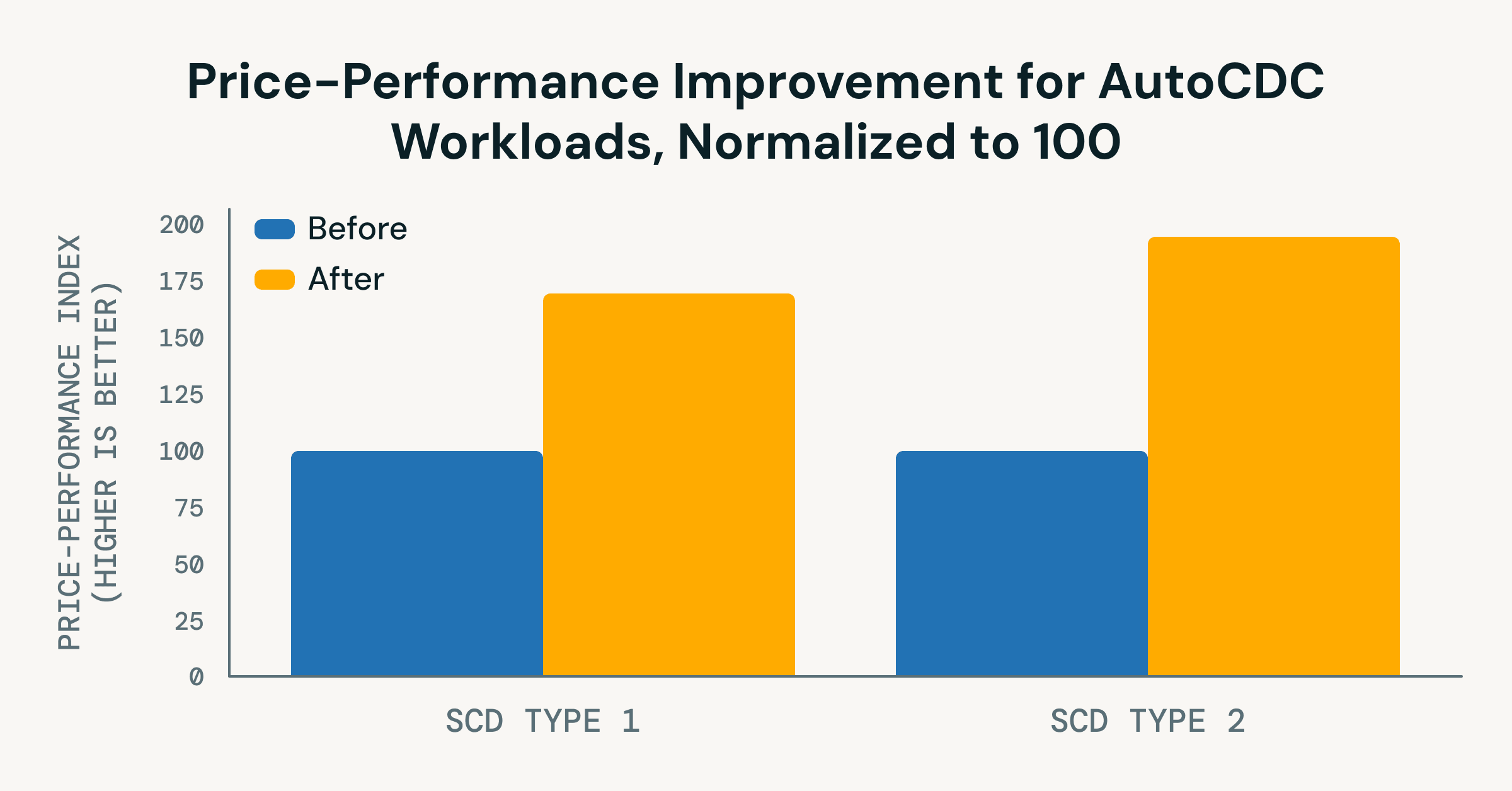
파이프라인 로직을 단순화하는 것 외에도, 최근 Databricks Runtime 개선을 통해 AutoCDC 워크로드의 성능과 비용 효율성 모두에서 실질적인 향상이 이루어졌습니다. 2025년 11월 이후의 개선 사항은 다음과 같습니다. SCD Type 1:- 지연 시간 약 22% 개선
- 비용 약 40% 절감
- 순 가격-성능 71% 향상
- 지연 시간 약 45% 개선
- 증분 업데이트 비용 약 35% 절감
- 순 가격-성능 96% 향상
MERGE INTO는 여전히 Spark의 핵심 프리미티브이지만, AutoCDC는 이를 기반으로 구축하여 데이터 볼륨이 증가할수록 순서에 어긋난 데이터와 증분 처리를 더욱 효율적으로 처리합니다.
AutoCDC 실제 성과
프로덕션에서 CDC·SCD 파이프라인을 운영하는 팀들은 AutoCDC에서 일관된 가치를 보고합니다. Navy Federal Credit Union 은 Lakeflow Spark Declarative Pipelines의 AutoCDC를 활용해 대규모 실시간 이벤트 처리를 구현합니다. 커스텀 CDC 코드와 지속적인 파이프라인 유지 작업을 없애면서, 수십억 건의 애플리케이션 이벤트를 지속적으로 처리합니다.“Spark Declarative Pipelines 프로그래밍 모델의 단순함과 서비스 역량이 결합되어 믿을 수 없을 정도로 빠른 구현 속도를 이끌어냈습니다.” — Jian (Miracle) Zhou, 시니어 엔지니어링 매니저, Navy Federal Credit UnionBlock 은 Lakeflow Spark Declarative Pipelines의 AutoCDC로 Delta Lake 위의 변경 데이터 캡처와 실시간 스트리밍 파이프라인을 단순화했습니다. 직접 작성한 CDC·merge 로직을 구현이 빠르고 운영이 쉬운 선언적 방식으로 대체했습니다.
“Spark Declarative Pipelines를 도입한 이후, 스트리밍 파이프라인을 정의하고 개발하는 데 필요한 시간이 며칠에서 몇 시간으로 줄었습니다.” — Yue Zhang, 스태프 소프트웨어 엔지니어, Data Foundations, BlockValora Group 은 선도적인 스위스 기반 “푸드베니언스(foodvenience)” 기업으로, Lakeflow Spark Declarative Pipelines의 AutoCDC로 마스터 데이터 및 실시간 리테일 분석을 위한 변경 데이터 캡처를 간소화했습니다. 커스텀 CDC 코드를 팀 전반에 걸쳐 구현·반복·확장이 쉬운 선언적 방식으로 대체했습니다.
“SDP(Spark Declarative Pipelines)에서 CDC를 활용함으로써 많은 것을 얻었습니다. 코드를 작성할 필요 없이 모든 것이 백그라운드에서 추상화되기 때문입니다. AutoCDC는 코드 줄 수를 최소화하며… 정말 사용하기 쉽습니다.” — Alexane Rose, 데이터 및 AI 아키텍트, Valora Holding
시작하기
AutoCDC API는 Databricks의 Lakeflow Spark Declarative Pipelines 일부로 제공되며, Databricks Genie Code 를 통해 생성하고 관리할 수도 있습니다. 자세한 내용은 다음을 참고하세요.- AutoCDC 문서 검토 (SQL 및 Python)
- SCD Type 1, SCD Type 2, 스냅샷 기반 CDC 예제 탐색
- 직접 파이프라인에서 AutoCDC를 사용해보고 직접 작성한 CDC 로직을 제거하세요!