원문: Accelerating LLM Inference with Prompt Caching for Open-Source Models on Databricks 저자: Pei-Lun Liao, Asfandyar Qureshi, Roshan Regula, Bruce Fontaine, James Thomas, Chenyang Yu 게시일: 2026년 5월 22일
요약
- Prompt caching 은 반복되는 프롬프트 접두부(prefix)를 재사용하여 LLM 을 더 빠르게 동작시킵니다. 자동으로 지연(latency)을 줄이고 처리량(throughput)을 끌어올립니다.
- Databricks 는 이제 batch / pay-per-token / provisioned 워크로드 전반에서 오픈소스 모델에 대해 prompt caching 을 지원합니다. 별도 설정이 필요 없습니다.
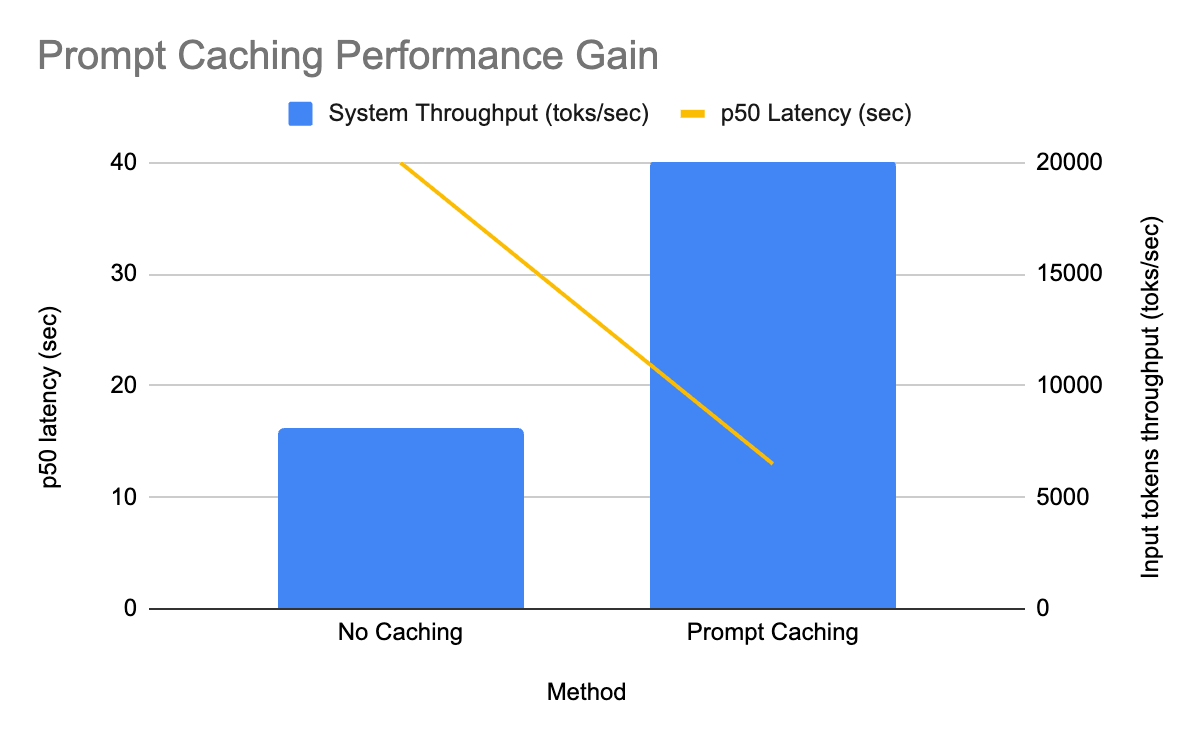
- GPT-OSS 운영 환경에서 prompt caching 을 적용했을 때 처리량 2.5배 증가, P50 지연 3배 단축.
Prompt Caching 이 왜 중요한가
대형 언어 모델(LLM) 추론에서는 반복되는 프롬프트가 자주 발생합니다 — 동일한 시스템/지시 프롬프트가 수천 건의 요청에 등장하는 상황을 생각해 보세요. 매 호출마다 그 동일한 접두부를 다시 처리하는 것은 컴퓨트를 낭비하고, 지연을 부풀리고, 비용을 늘립니다. Prompt caching 은 이 중복을 제거합니다 — 다음을 제공합니다.- 더 낮은 지연 — 캐시가 적중하면 prefill 단계를 건너뛸 수 있습니다.
- 더 높은 처리량 — 모델 유닛당 더 많은 토큰을 처리합니다.
기능 가용성
Databricks 는 이미 독점(proprietary) 모델(GPT, Gemini, Claude)에 대한 내장 prompt caching 을 제공해 왔습니다. 이제 그 역량을 Foundation Model APIs (FMAPIs) 를 떠받치는 open-weight 모델로 확장하여, batch 추론, pay-per-token, provisioned throughput 워크로드에 모두 적용합니다. 또한 foundation model 위에서 동작하는 모든 상위 서비스 — 예: Agent Bricks, Genie, AI Functions — 에도 적용됩니다. Databricks 에서 호스팅되는 다음 OSS 모델에 대해 prompt caching 이 지원됩니다.- GPT-OSS 20B / 120B
- Gemma 3 12B
- Fine-tuned Llama 3.1 8B (PEFT 서빙 경유)
- Llama 3.1 8B / 3.3 70B
실측 효과 — GPT-OSS 배치 추론
GPT-OSS 모델에 prompt caching 을 가장 먼저 롤아웃했고, 대규모 운영 배치 추론 파이프라인 중 하나에서 즉시 측정 가능한 이득을 확인했습니다.- 복제본당 입력 토큰 처리량 2.5배 증가
- P50 지연 3배 감소
- 위 효과는 30% 라는 비교적 낮은 캐시 히트율에서 달성