원문: Introducing Databricks Lakeflow: A unified, intelligent solution for data engineering게시일: 2024년 6월 12일 | 저자: Michael Armbrust, Bilal Aslam
오늘 우리는 Databricks Lakeflow 를 발표합니다. Lakeflow는 데이터 수집 (Ingestion) 에서 변환 (Transformation) 과 오케스트레이션 (Orchestration) 에 이르기까지 데이터 엔지니어링의 모든 측면을 단순화하고 통합하는 새로운 솔루션입니다. Lakeflow를 통해 데이터 팀은 MySQL, Postgres, Oracle 같은 데이터베이스와 Salesforce, Dynamics, SharePoint, Workday, NetSuite, Google Analytics 같은 엔터프라이즈 애플리케이션으로부터 데이터를 대규모로 손쉽게 수집할 수 있습니다. 또한 Databricks는 Apache Spark™를 위한 Real Time Mode 를 도입합니다. 이 기능은 마이크로배치 방식보다 훨씬 낮은 지연 시간으로 스트림 처리를 가능하게 합니다. Lakeflow는 내장된 CI/CD 지원과 트리거링, 분기 (Branching), 조건부 실행을 지원하는 고급 워크플로우를 통해 프로덕션 환경에서의 파이프라인 배포, 운영, 모니터링을 자동화합니다. 데이터 품질 검사 및 상태 모니터링 기능이 내장되어 있으며 PagerDuty 같은 알림 시스템과도 통합됩니다. Lakeflow는 프로덕션 수준의 데이터 파이프라인을 구축하고 운영하는 과정을 단순하고 효율적으로 만들면서도 가장 복잡한 데이터 엔지니어링 요구사항까지 처리할 수 있어, 바쁜 데이터 팀도 신뢰할 수 있는 데이터와 AI에 대한 증가하는 수요를 충족할 수 있게 합니다.

신뢰할 수 있는 데이터 파이프라인 구축과 운영의 어려움
데이터 엔지니어링은 기업 내 데이터와 AI 민주화에 필수적이지만, 여전히 복잡하고 어려운 분야로 남아 있습니다. 데이터 팀은 사일로화되어 있고 독점적인 데이터베이스와 엔터프라이즈 애플리케이션 등 다양한 시스템에서 데이터를 수집해야 하며, 이를 위해 복잡하고 취약한 커넥터를 직접 개발해야 하는 경우가 많습니다. 데이터 준비 단계에서는 복잡한 로직을 유지 관리해야 하고, 장애와 지연 시간 급증은 운영 중단과 고객 불만으로 이어집니다. 파이프라인 배포 및 데이터 품질 모니터링에는 별도의 분산된 도구가 필요해 프로세스가 더욱 복잡해집니다. 기존 솔루션들은 단편화되어 있고 불완전하여 낮은 데이터 품질, 신뢰성 문제, 높은 비용, 그리고 끊임없이 증가하는 작업 백로그를 초래하고 있습니다. Lakeflow는 Databricks Data Intelligence Platform 위에 구축된 단일 통합 경험을 통해 데이터 엔지니어링의 모든 측면을 단순화함으로써 이러한 문제를 해결합니다. Unity Catalog와의 깊은 통합을 통해 엔드-투-엔드 (End-to-End) 거버넌스 (Governance) 를 제공하며, 서버리스 (Serverless) 컴퓨팅을 통해 효율적이고 확장 가능한 실행 환경을 제공합니다.Lakeflow Connect: 간편하고 확장 가능한 데이터 수집
Lakeflow Connect 는 MySQL, Postgres, SQL Server, Oracle 같은 데이터베이스와 Salesforce, Dynamics, SharePoint, Workday, NetSuite 같은 엔터프라이즈 애플리케이션을 위한 광범위한 네이티브 (Native) 고확장 커넥터 (Connector) 를 제공합니다. 이 커넥터들은 Unity Catalog와 완전히 통합되어 강력한 데이터 거버넌스를 지원합니다. Lakeflow Connect는 Databricks가 2023년 11월에 인수한 Arcion 의 저지연 고효율 기술을 내재화하고 있습니다. 변경 데이터 캡처 (CDC, Change Data Capture) 기술을 활용하여 레이크하우스 (Lakehouse) 로의 데이터 이전을 단순하고 신뢰할 수 있으며 운영 효율적으로 만듭니다. Lakeflow Connect는 크기, 형식, 위치에 관계없이 모든 데이터를 배치 및 실시간 분석에 활용할 수 있도록 지원합니다.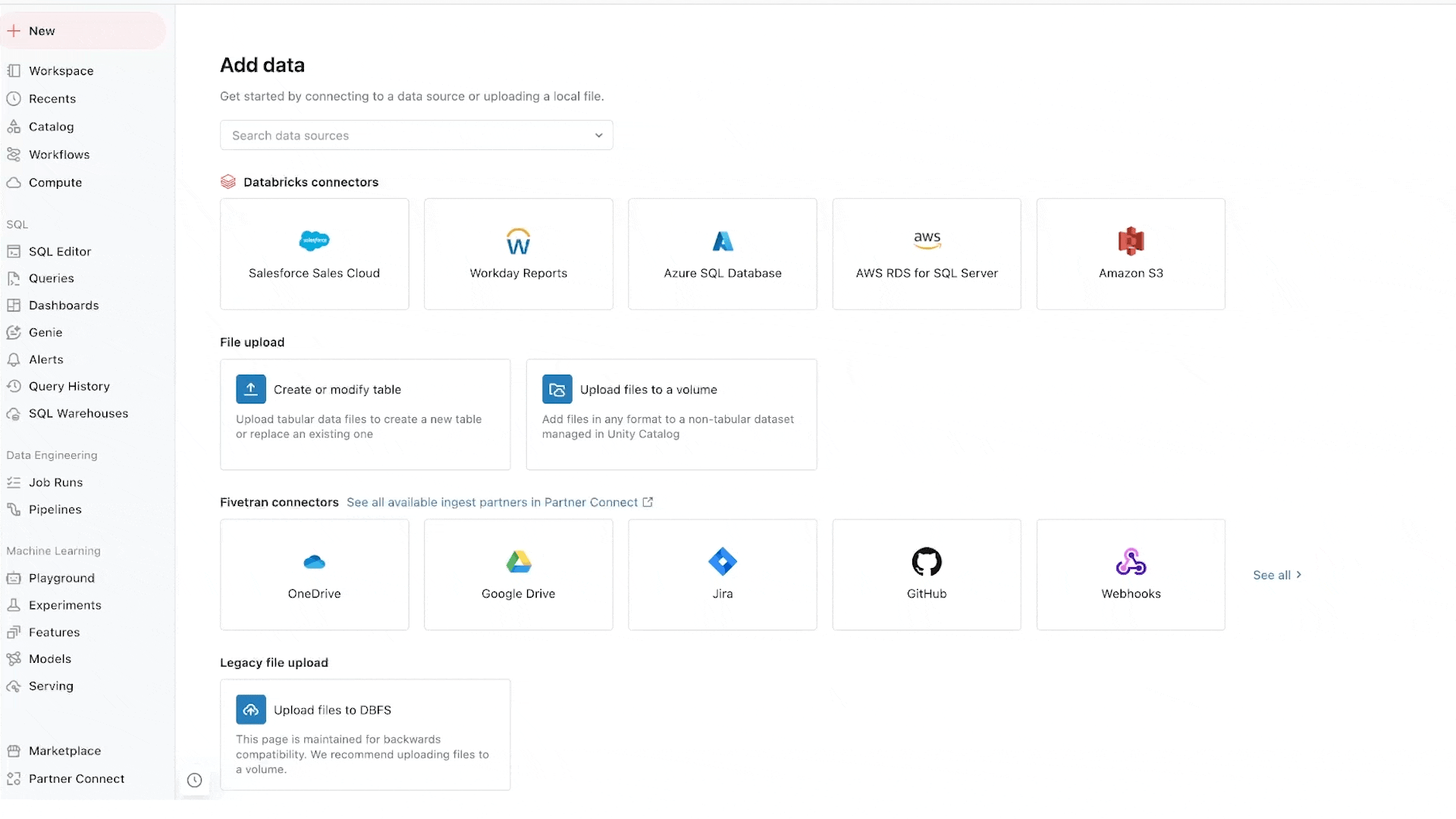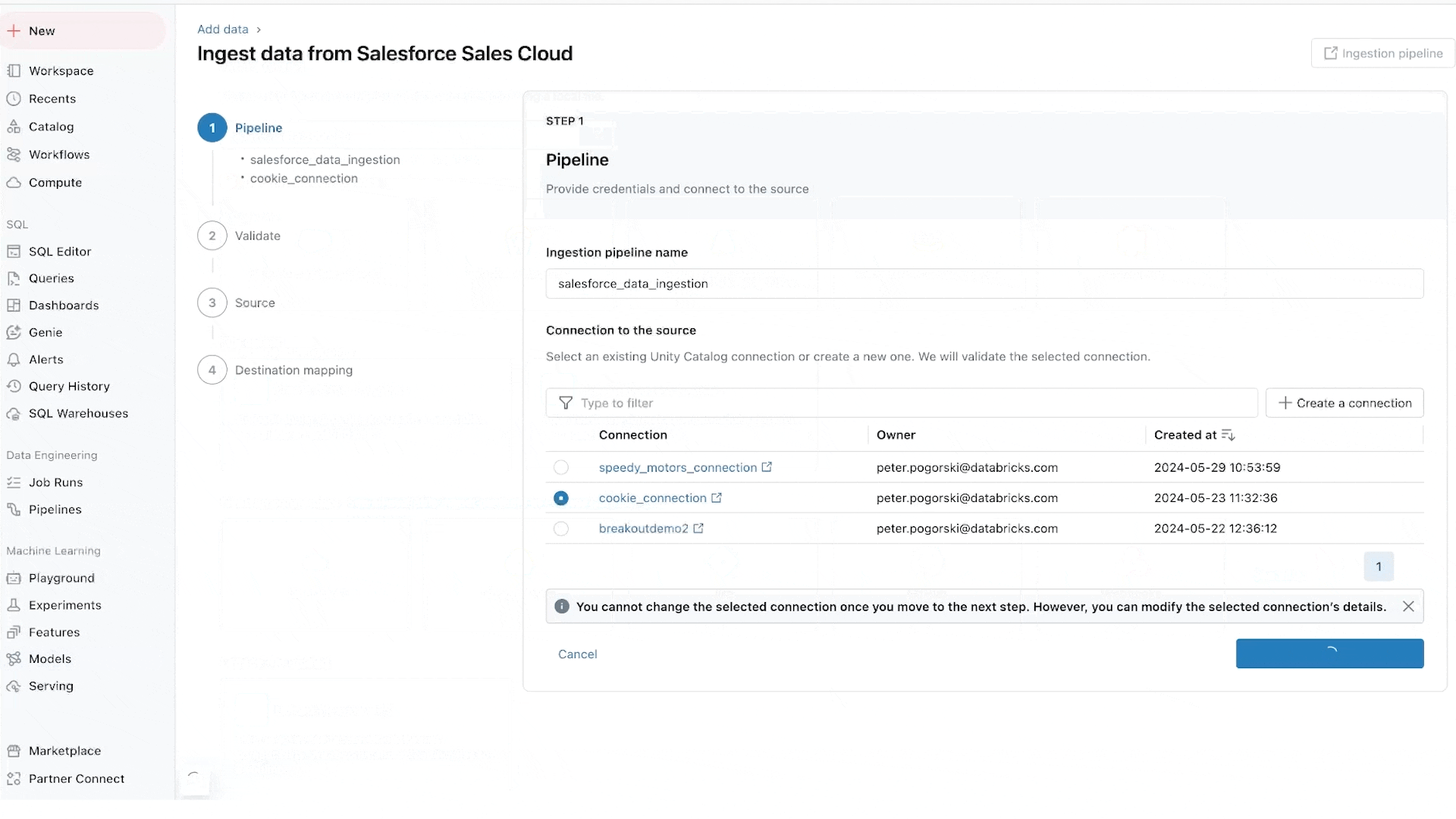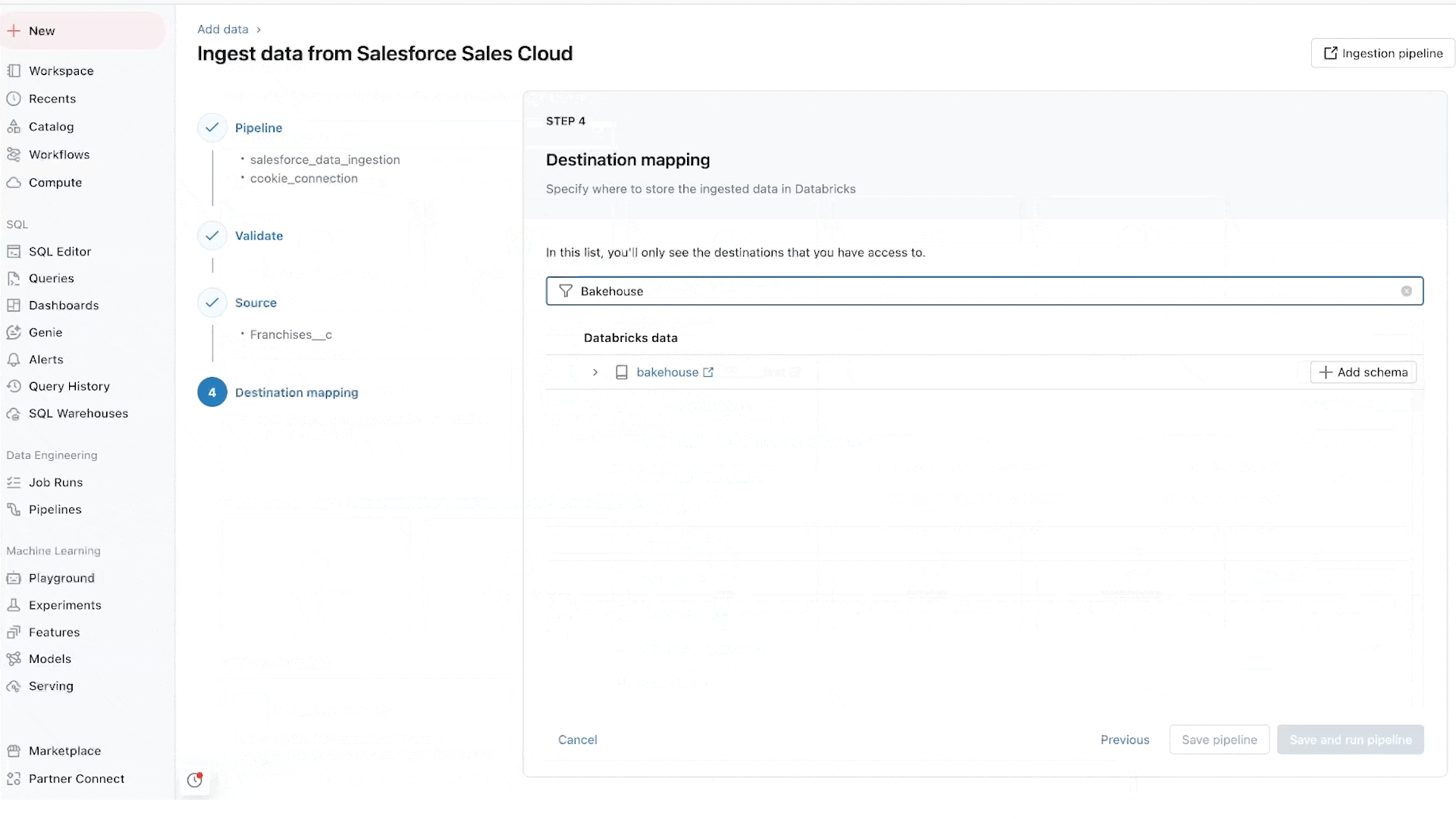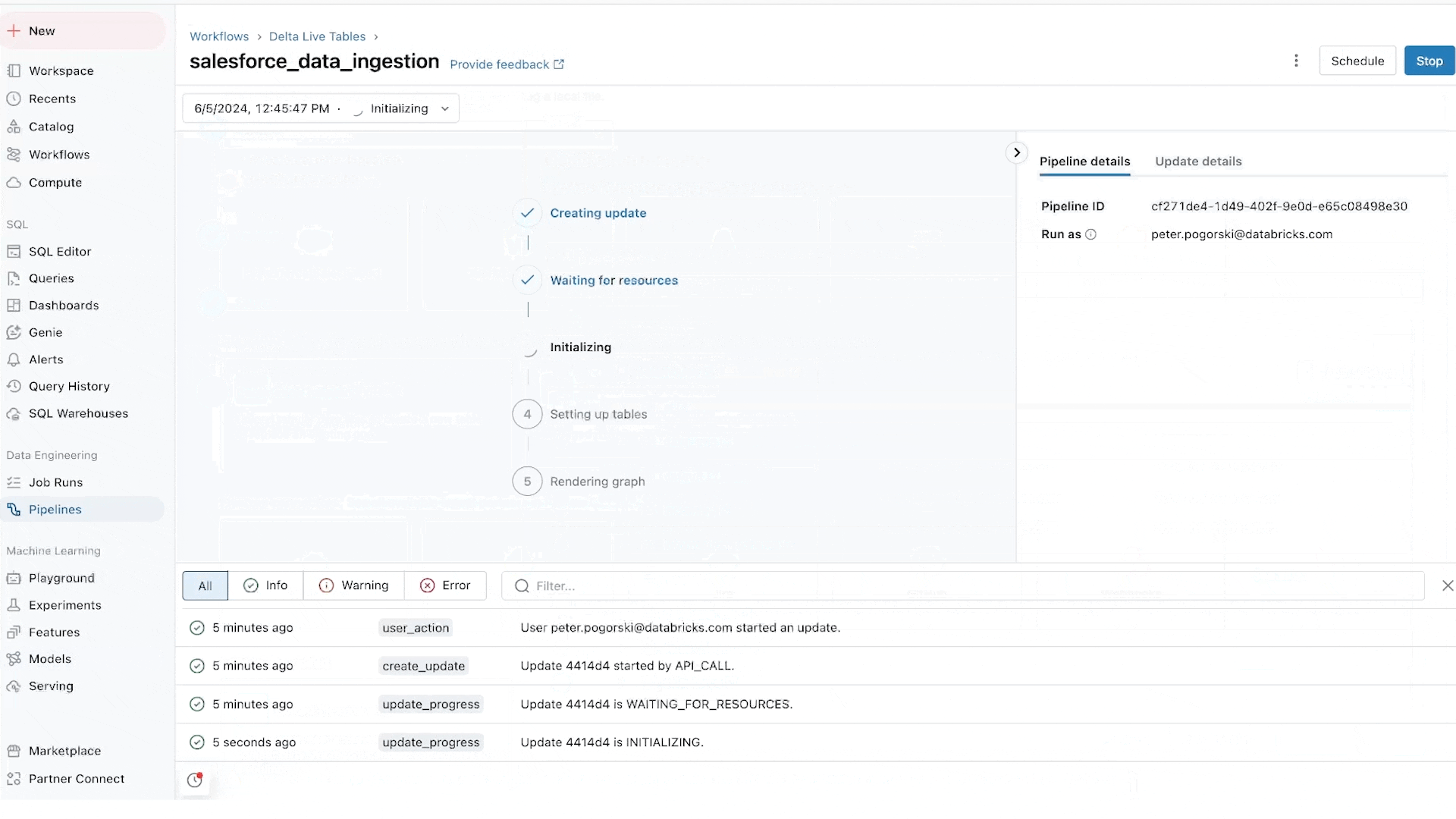
참고 고객 사례 — Insulet: 웨어러블 인슐린 관리 시스템인 Omnipod의 제조사 Insulet은 Lakeflow Connect의 Salesforce 수집 커넥터를 활용하여 고객 피드백 관련 데이터를 Databricks 기반 데이터 솔루션으로 수집합니다. 분산된 시스템을 중앙화된 확장 가능한 아키텍처로 대체함으로써, Insulet은 모든 팀이 실시간 데이터에 원활하게 접근하여 제조 워크플로우 모니터링, Omnipod 성능 최적화, 그리고 모든 AI 애플리케이션 지원을 가능하게 했습니다.
Lakeflow Pipelines: 효율적인 선언형 데이터 파이프라인
Databricks의 고확장성 Delta Live Tables (DLT) 기술을 기반으로 구축된 Lakeflow Pipelines 는 데이터 팀이 SQL 또는 Python으로 데이터 변환과 ETL (Extract, Transform, Load) 을 구현할 수 있게 합니다. 이제 고객은 코드 변경 없이 Real Time Mode 를 활성화하여 저지연 스트리밍을 구현할 수 있습니다. Lakeflow는 수동 오케스트레이션의 필요성을 없애고 배치 (Batch) 와 스트림 (Stream) 처리를 통합합니다. 최적의 가격 대비 성능을 위한 증분 데이터 처리 (Incremental Processing) 를 제공하며, 가장 복잡한 스트리밍 및 배치 데이터 변환도 쉽게 구축하고 운영할 수 있게 합니다. Real Time Mode for Apache Spark 는 이번 발표의 핵심 혁신 중 하나입니다. 기존 마이크로배치 방식 대비 수십 배 더 빠른 지연 시간으로 스트림 처리를 가능하게 합니다. 시간에 민감한 데이터셋을 지속적으로 저지연으로 전달해야 하는 워크로드에서 코드 변경 없이 이 모드를 활성화할 수 있습니다.
Lakeflow Jobs: 모든 워크로드를 위한 안정적인 오케스트레이션
Lakeflow Jobs 는 프로덕션 워크로드를 안정적으로 오케스트레이션하고 모니터링합니다. Databricks Workflows의 고급 기능을 기반으로 구축되어, 수집, 파이프라인, 노트북 (Notebook), SQL 쿼리, 머신러닝 (ML) 학습, 모델 배포 및 추론 등 모든 워크로드를 오케스트레이션합니다. 데이터 팀은 트리거 (Trigger), 분기 (Branching), 루핑 (Looping) 을 활용하여 복잡한 데이터 전달 요구사항을 충족할 수 있습니다. Lakeflow Jobs는 또한 데이터 상태와 전달을 이해하고 추적하는 프로세스를 자동화하고 단순화합니다. 데이터 중심의 상태 관점을 제공하여, 수집, 변환, 테이블, 대시보드 간의 관계를 포함한 전체 계보 (Lineage) 를 데이터 팀에 제공합니다. 또한 데이터 신선도 (Freshness) 와 품질을 추적하여, 데이터 팀이 Lakehouse Monitoring을 통해 버튼 클릭 한 번으로 모니터를 추가할 수 있게 합니다.Data Intelligence Platform 위에 구축
Databricks Lakeflow는 Data Intelligence Platform에 네이티브로 통합되어 다음과 같은 역량을 제공합니다.- 데이터 인텔리전스 (Data Intelligence): AI 기반 인텔리전스는 Lakeflow의 단순한 기능이 아니라, 제품 전반을 관통하는 기반 역량입니다. Databricks Assistant가 데이터 파이프라인의 탐색, 작성, 모니터링을 지원하여 신뢰할 수 있는 데이터 구축에 더 많은 시간을 투자할 수 있습니다.
- 통합 거버넌스 (Unified Governance): Lakeflow는 Unity Catalog와 깊이 통합되어 계보 (Lineage) 추적과 데이터 품질 관리를 지원합니다.
- 서버리스 컴퓨팅 (Serverless Compute): 인프라 걱정 없이 대규모로 파이프라인을 구축하고 오케스트레이션하여, 팀이 본연의 업무에 집중할 수 있게 합니다.