원문: Introducing Databricks Model Training for Fine-Tuning GenAI Models
 게시일: 2024년 7월 22일 | 카테고리: Data Science and ML
저자: Daniel King, Nancy Hung, Kasey Uhlenhuth
게시일: 2024년 7월 22일 | 카테고리: Data Science and ML
저자: Daniel King, Nancy Hung, Kasey Uhlenhuth
오늘, Databricks Model Training의 GenAI 모델 파인튜닝(fine-tuning) 지원이 Public Preview로 출시되었음을 발표하게 되어 매우 기쁩니다. Databricks는 범용 LLM(Large Language Model)의 지능을 기업 데이터와 연결하는 것 — 즉 데이터 인텔리전스(Data Intelligence) — 이 고품질 GenAI 시스템을 구축하는 핵심이라고 믿습니다. 파인튜닝은 특정 태스크, 비즈니스 맥락, 또는 도메인 지식에 맞게 모델을 전문화할 수 있으며, RAG(Retrieval Augmented Generation)와 결합하여 더욱 정확한 애플리케이션을 만들 수 있습니다. 이는 기업 데이터를 통해 GenAI를 고유한 비즈니스 요구에 맞게 적응시키는 Data Intelligence Platform 전략의 핵심 축을 이룹니다.
Model Training
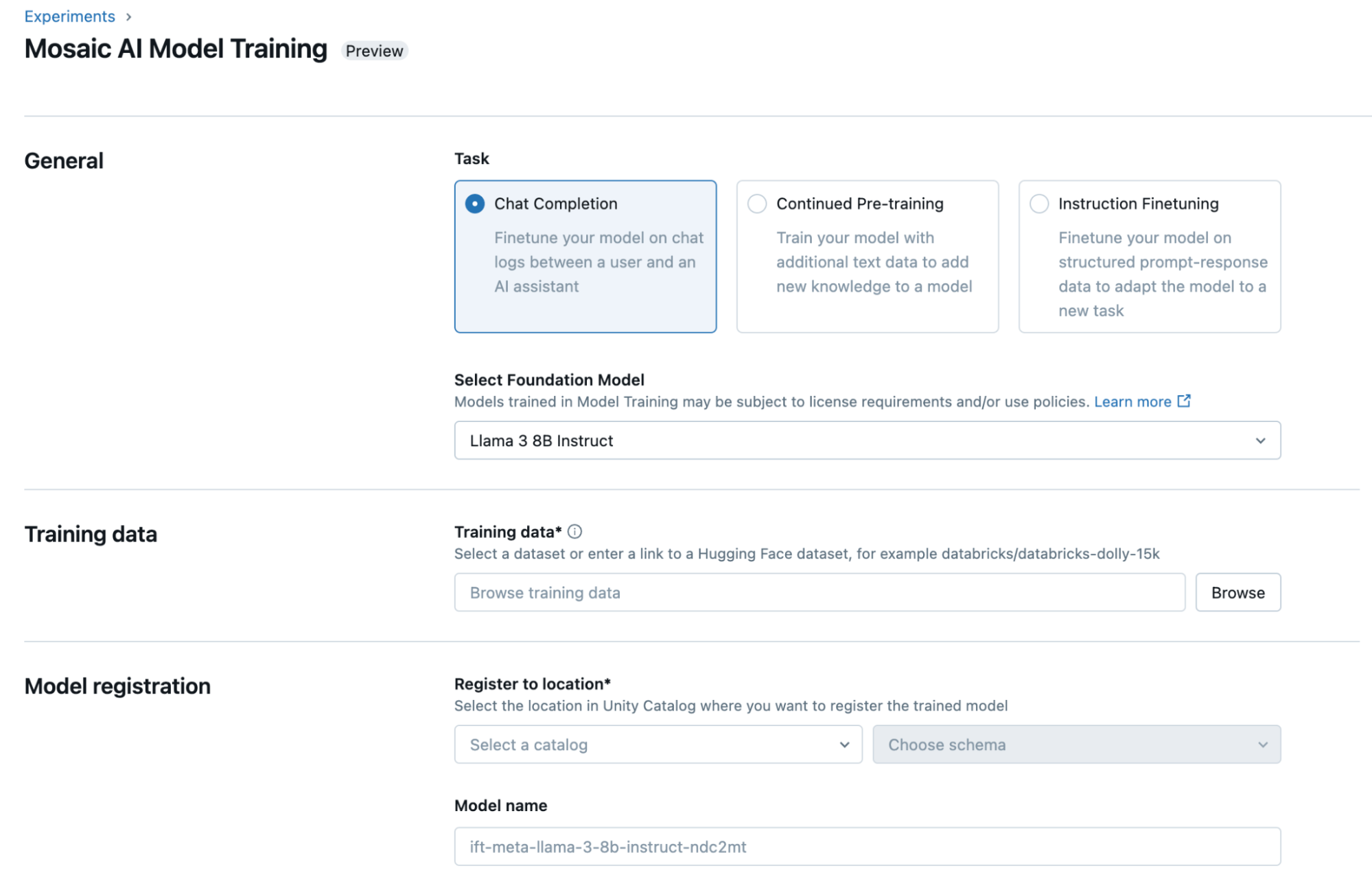 지난 한 해 동안 고객사들은 20만 개 이상의 커스텀 AI 모델을 학습시켰으며, Databricks는 이 경험에서 얻은 교훈들을 완전 관리형 서비스인 Databricks Model Training 으로 집대성했습니다. Llama 3, Mistral, DBRX 등 다양한 모델을 기업 데이터로 파인튜닝하거나 프리트레이닝(pre-training)할 수 있습니다. 학습된 모델은 Unity Catalog에 등록되어 모델과 가중치(weights)에 대한 완전한 소유권 및 제어권을 제공합니다. 또한 Databricks Model Serving을 통해 원클릭으로 손쉽게 모델을 배포할 수 있습니다.
Databricks는 Model Training을 다음과 같은 원칙으로 설계했습니다:
지난 한 해 동안 고객사들은 20만 개 이상의 커스텀 AI 모델을 학습시켰으며, Databricks는 이 경험에서 얻은 교훈들을 완전 관리형 서비스인 Databricks Model Training 으로 집대성했습니다. Llama 3, Mistral, DBRX 등 다양한 모델을 기업 데이터로 파인튜닝하거나 프리트레이닝(pre-training)할 수 있습니다. 학습된 모델은 Unity Catalog에 등록되어 모델과 가중치(weights)에 대한 완전한 소유권 및 제어권을 제공합니다. 또한 Databricks Model Serving을 통해 원클릭으로 손쉽게 모델을 배포할 수 있습니다.
Databricks는 Model Training을 다음과 같은 원칙으로 설계했습니다:
- Simple(단순함): 베이스 모델과 학습 데이터셋을 선택하면 곧바로 학습을 시작할 수 있습니다. GPU 관리와 효율적인 학습의 복잡성은 저희가 처리하므로, 사용자는 모델링에만 집중할 수 있습니다.
- Fast(빠름): 오픈소스 대비 최대 2배 빠른 독자적인 학습 스택이 탑재되어 있어 모델을 신속하게 반복 개발할 수 있습니다. 수천 개의 예시로 파인튜닝하는 것부터 수십억 개의 토큰으로 지속적 프리트레이닝(continued pre-training)을 수행하는 것까지, 학습 스택이 규모에 맞게 확장됩니다.
- Integrated(통합): Databricks 플랫폼에서 데이터를 손쉽게 수집, 변환, 전처리하고 학습에 직접 활용할 수 있습니다.
- Tunable(튜닝 가능): 학습률(learning rate)과 학습 기간(training duration) 등 핵심 하이퍼파라미터(hyperparameter)를 빠르게 조정하여 최고 품질의 모델을 구축할 수 있습니다.
- Sovereign(주권): 모델과 가중치의 완전한 소유권이 사용자에게 있습니다. 학습 데이터셋 및 다운스트림 소비자(downstream consumer)에 대한 권한, 접근 계보(access lineage)를 직접 제어합니다.
참고 고객 사례 — Experian“Experian에서 우리는 오픈소스 LLM 파인튜닝 분야에서 혁신을 이루고 있습니다. Databricks Model Training은 모델의 평균 학습 시간을 크게 단축시켜, 하루에 여러 번 반복 개발하는 GenAI 개발 사이클을 가속화할 수 있었습니다. 최종 결과물은 우리가 정의한 방식으로 동작하며, 우리의 사용 사례에서 상용 모델을 능가하고, 운영 비용도 크게 절감됩니다.” — James Lin, Head of AI/ML Innovation, Experian
참고 고객 사례 — First American“Databricks를 통해, LLM을 이용해 부동산 등기 문서에서 거래 및 법인 데이터를 추출하는 하루 100만 건 이상의 파일 처리 업무를 자동화할 수 있었습니다. Meta Llama3 8b를 파인튜닝하고 Databricks Model Serving을 활용함으로써 정확도 목표를 초과 달성했으며, 대규모 고가의 GPU 클러스터를 직접 관리할 필요 없이 이 작업을 대규모로 확장할 수 있었습니다.” — Prabhu Narsina, VP Data and AI, First American
Benefits (파인튜닝의 이점)
Databricks Model Training을 사용하면 오픈소스 모델을 전문화된 엔터프라이즈 태스크에 맞게 적응시켜 더 높은 품질을 달성할 수 있습니다. 주요 이점은 다음과 같습니다:- Higher quality(고품질): 요약(summarization), 챗봇 행동, 툴 사용(tools use), 다국어 대화 등 특정 태스크와 기능에 맞게 모델 품질을 향상시킵니다.
- Lower latency at lower costs(낮은 레이턴시와 비용): 대형 범용 모델은 프로덕션에서 비용이 많이 들고 속도가 느릴 수 있습니다. 많은 고객이 소규모 모델(13B 파라미터 미만)을 파인튜닝함으로써 품질을 유지하면서 레이턴시와 비용을 크게 절감할 수 있다는 사실을 발견했습니다.
- Consistent, structured formatting or style(일관된 구조화 형식 또는 스타일): 엔터티 추출(entity extraction)이나 컴파운드 AI 시스템에서의 JSON 스키마 생성과 같이, 특정 형식이나 스타일을 따르는 출력을 생성합니다.
- Lightweight, manageable system prompts(가볍고 관리하기 쉬운 시스템 프롬프트): 많은 비즈니스 로직이나 사용자 피드백을 모델 자체에 통합할 수 있습니다. 복잡한 프롬프트에 최종 사용자 피드백을 반영하는 것은 어려울 수 있고, 작은 프롬프트 변경이 다른 질문에서 성능 저하를 유발할 수도 있습니다.
- Expand the knowledge base(지식 기반 확장): Continued Pre-training을 통해 특정 주제, 내부 문서, 언어, 또는 모델의 원래 지식 컷오프(knowledge cut-off) 이후의 최신 이벤트 등 모델의 지식 기반을 확장합니다. Continued Pre-training의 이점에 대한 향후 블로그도 기대해주세요!
RAG와 Fine-Tuning의 결합 — RAFT
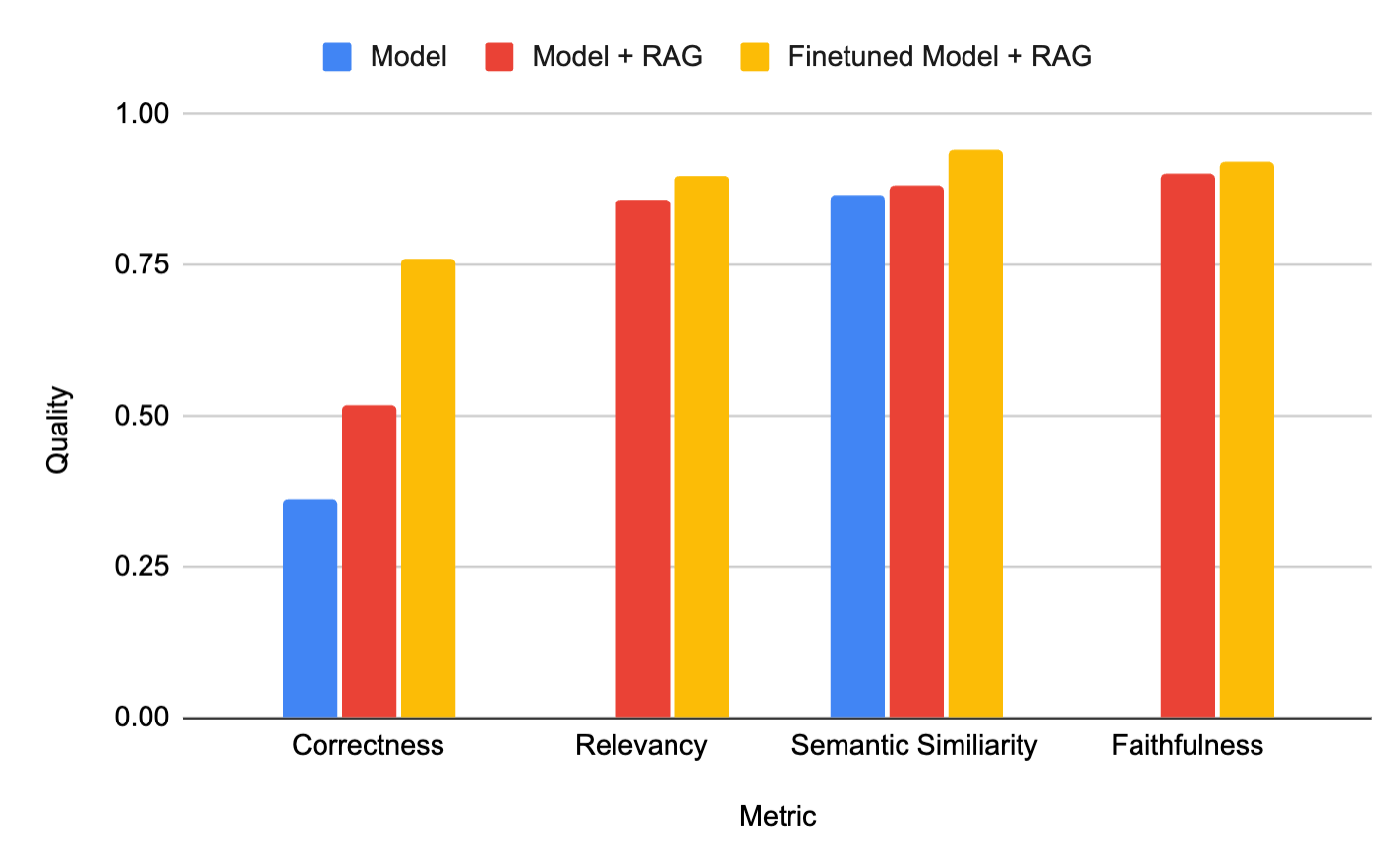 고객들로부터 자주 받는 질문이 있습니다: 기업 데이터를 활용하려면 RAG를 써야 할까요, 아니면 파인튜닝을 해야 할까요? RAFT(Retrieval Augmented Fine-Tuning) 를 사용하면 두 가지를 모두 결합할 수 있습니다. 예를 들어, Celebal Technologies는 생성 모델을 파인튜닝하여 검색된 컨텍스트로부터의 요약 품질을 개선함으로써 환각(hallucination)을 줄이고 전반적인 품질을 향상시킨 고품질 도메인 특화 RAG 시스템을 구축했습니다(아래 그림 참조).
그림 1: 파인튜닝된 모델과 RAG를 결합한 방식(노란색)이 Celebal Technologies 고객에게 가장 높은 품질의 시스템을 제공했습니다. 해당 블로그에서 발췌.
고객들로부터 자주 받는 질문이 있습니다: 기업 데이터를 활용하려면 RAG를 써야 할까요, 아니면 파인튜닝을 해야 할까요? RAFT(Retrieval Augmented Fine-Tuning) 를 사용하면 두 가지를 모두 결합할 수 있습니다. 예를 들어, Celebal Technologies는 생성 모델을 파인튜닝하여 검색된 컨텍스트로부터의 요약 품질을 개선함으로써 환각(hallucination)을 줄이고 전반적인 품질을 향상시킨 고품질 도메인 특화 RAG 시스템을 구축했습니다(아래 그림 참조).
그림 1: 파인튜닝된 모델과 RAG를 결합한 방식(노란색)이 Celebal Technologies 고객에게 가장 높은 품질의 시스템을 제공했습니다. 해당 블로그에서 발췌.
참고 고객 사례 — Celebal Technologies“RAG만으로는 한계에 도달한 것 같았습니다 — 프롬프트와 지시문을 많이 작성해야 했고 번거로웠습니다. 파인튜닝 + RAG로 전환했고 Databricks Model Training 덕분에 정말 쉬워졌습니다! 데이터 언어학(Data Linguistics)과 도메인에 모델을 적응시킬 수 있었을 뿐 아니라, RAG 시스템에서 환각을 줄이고 속도를 높이는 데도 도움이 되었습니다. Databricks로 파인튜닝한 모델과 RAG 시스템을 결합한 후, 더 적은 토큰을 사용하면서도 더 나은 애플리케이션과 정확도를 얻을 수 있었습니다.” — Anurag Sharma, AVP Data Science, Celebal Technologies
Evaluation (모델 평가)
파인튜닝 실험 중 모델 품질과 베이스 모델 선택을 반복적으로 개선하기 위해서는 평가(evaluation) 방법이 매우 중요합니다. 시각적 검사(visual inspection)부터 LLM-as-a-Judge까지, Databricks는 Model Training이 Databricks 내 모든 다른 평가 시스템과 원활하게 연동되도록 설계했습니다:- Prompts(프롬프트 모니터링): 학습 중 모니터링할 프롬프트를 최대 10개까지 추가할 수 있습니다. 학습 진행 상황을 수동으로 확인할 수 있도록 MLflow 대시보드에 모델 출력 결과를 주기적으로 기록합니다.
- Playground(플레이그라운드): 파인튜닝된 모델을 배포하고 플레이그라운드(playground)에서 직접 상호작용하며 수동 프롬프트 테스트 및 비교를 수행할 수 있습니다.
- LLM-as-a-Judge: MLflow Evaluation을 통해 다른 LLM을 사용하여 다양한 기존 또는 커스텀 지표로 파인튜닝된 모델을 평가합니다.
- Notebooks(노트북): 파인튜닝된 모델을 배포한 후, 엔드포인트에서 커스텀 평가 코드를 실행하는 노트북이나 커스텀 스크립트를 작성할 수 있습니다.
Get Started (시작하기)
 Databricks UI 또는 Python을 통해 프로그래밍 방식으로 모델을 파인튜닝할 수 있습니다. 시작하려면 Unity Catalog 또는 공개 Hugging Face 데이터셋에서 학습 데이터셋의 위치를 선택하고, 커스터마이징할 모델과 원클릭 배포를 위해 모델을 등록할 위치를 지정하면 됩니다.
Databricks UI 또는 Python을 통해 프로그래밍 방식으로 모델을 파인튜닝할 수 있습니다. 시작하려면 Unity Catalog 또는 공개 Hugging Face 데이터셋에서 학습 데이터셋의 위치를 선택하고, 커스터마이징할 모델과 원클릭 배포를 위해 모델을 등록할 위치를 지정하면 됩니다.
- Data and AI Summit 발표 영상 — Databricks Model Training 살펴보기
- 공식 문서(AWS) 및 공식 문서(Azure)와 가격 페이지를 참고하세요.
- dbdemo 를 통해 Databricks Model Training으로 고품질 모델을 구축하는 방법을 빠르게 체험해보세요.