원문: Zero-Downtime Patching in Lakebase Part 1: Prewarming

참고 요약
- 계획된 유지보수(Planned maintenance)는 하드웨어 장애보다 패치가 훨씬 자주 발생하기 때문에, 대부분의 데이터베이스에서 예기치 않은 장애보다 더 큰 워크로드 중단을 초래합니다. 목표는 버전 업데이트와 보안 패치를 완전히 눈에 띄지 않게 만드는 것입니다.
- 데이터베이스 재시작의 핵심 문제는 인메모리 캐시(in-memory cache)가 소거되어, 스토리지에서 데이터가 다시 로드되는 동안 처리량(throughput)이 최대 70%까지 저하된다는 점입니다. 워크로드가 무거울 경우, 이는 성능 문제를 넘어 가용성 문제로 번질 수 있습니다.
- Lakebase는 예약된 재시작 전에 백그라운드에서 새 컴퓨팅 노드를 구동하고, 현재 프라이머리(primary)의 페이지 목록과 WAL 스트림을 활용하여 캐시를 프리워밍(prewarming)한 뒤, 추가 비용이나 레플리카 부담 없이 해당 노드를 프라이머리로 승격시킵니다.
Lakebase에서 고객 데이터베이스를 항상 사용 가능하게 유지하는 것은 우리가 하는 가장 중요한 일 중 하나입니다. 우리는 모든 계층에 이중화(redundancy)를 설계하여, 하드웨어 또는 소프트웨어 장애 발생 시 자동으로 데이터베이스를 페일오버(failover)하고 복구합니다. 대규모 시스템에서 이러한 예기치 않은 장애는 통계적으로 예상 가능한 일이지만, 개별 데이터베이스 입장에서는 그리 자주 발생하지 않습니다. 개별 데이터베이스에서는 오히려 계획된 유지보수 가 더 많은 워크로드 중단을 유발하는 경향이 있습니다. 결국, 일반적인 데이터베이스는 하드웨어 장애를 겪는 것보다 패치를 더 자주 받기 때문입니다. 오늘날 거의 모든 데이터베이스 제공업체는 유지보수 윈도우(maintenance window) 를 운영합니다. 이 기간 동안 데이터베이스는 활성화된 모든 연결을 끊고, 업데이트 및 재시작 프로세스를 거치는데, 이 과정은 수 초에서 수 분까지 걸릴 수 있습니다. Lakebase는 최적의 시간대에 업데이트를 예약할 수 있도록 지원하지만, 그것이 발생하는 순간에는 여전히 짧은 중단이 생깁니다. 우리는 더 잘 할 수 있다고 생각합니다. 이 블로그 포스트는 계획된 유지보수의 영향을 완전히 제거하기 위해 Lakebase 아키텍처를 어떻게 활용하는지에 대한 시리즈의 첫 번째 편입니다. 우리의 목표는 버전 업데이트와 보안 패치를 완전히 눈에 띄지 않게 만드는 것입니다. 이 포스트에서는 프리워밍(prewarming) 을 다룹니다. 이는 데이터베이스 재시작 이후 발생하는 성능 저하를 방지하는 기법입니다. 향후 포스트에서는 페일오버 프로세스 자체의 개선 사항과, 진정한 무중단 패칭(zero-downtime patching)에 더욱 가까이 다가갈 수 있는 추가적인 최적화 방안을 다룰 예정입니다.
콜드 재시작(Cold Restart)의 문제
PostgreSQL을 재시작할 때의 과제는 인메모리 캐시(구체적으로는 버퍼 캐시와 로컬 파일 캐시)가 손실된다는 점입니다. 데이터베이스가 매우 빠르게(P99 기준 1초 이내) 다시 온라인 상태가 되더라도, 데이터가 스토리지에서 다시 읽혀 캐시가 워밍업되는 동안 워크로드는 재시작 후 수 분간 속도 저하를 경험할 수 있습니다. 우리는 pgbench TPS(초당 트랜잭션 수)가 약 70% 감소하는 것을 확인했습니다. 이는 단순한 성능 문제처럼 보일 수 있지만, 속도 저하가 심각하여 데이터베이스가 워크로드를 따라가지 못하고 타임아웃이 발생할 경우에는 가용성 문제 로 번질 수 있습니다. 이 문제를 해결하기 위한 기법이 Postgres에 존재합니다.pg_prewarm을 사용하면 버퍼 캐시를 워밍업할 수 있습니다. 하지만 이는 재시작 이후에 실행되므로, 워크로드가 이미 영향을 받은 후에야 동작합니다. 스트리밍 레플리케이션(streaming replication)을 이용하여 레플리카를 구성하고, 페일오버(프라이머리 승격)하기 전에 미리 워밍업하는 방법도 있습니다. 그러나 이는 전체 레플리카를 생성하고, 페일오버 전 프리워밍을 신중하게 조율해야 합니다.
Lakebase 아키텍처에서의 프리워밍
Lakebase 아키텍처에서는 상태 비저장(stateless)의 탄력적인 컴퓨팅 노드와 분리된 공유 스토리지(disaggregated, shared storage)를 결합합니다. 컴퓨팅 노드는 로컬 캐시를 활용하여 서버리스(serverless) 특성을 유지하면서도 최대 성능을 제공합니다. 이 캐시도 위에서 설명한 동일한 콜드 스타트(cold-start) 문제에 직면하지만, Lakebase 아키텍처 덕분에 더 많은 선택지가 생깁니다. Lakebase의 Postgres 컴퓨팅 레플리카는 상태 비저장(stateless) 방식이기 때문에, 필요에 따라 자유롭게 구동하고 종료할 수 있습니다. 우리는 이 특성을 활용하여, 계획된 재시작 시 자동 프리워밍과 결합함으로써 워크로드에 미치는 성능 영향을 최소화합니다. 작동 방식은 다음과 같습니다.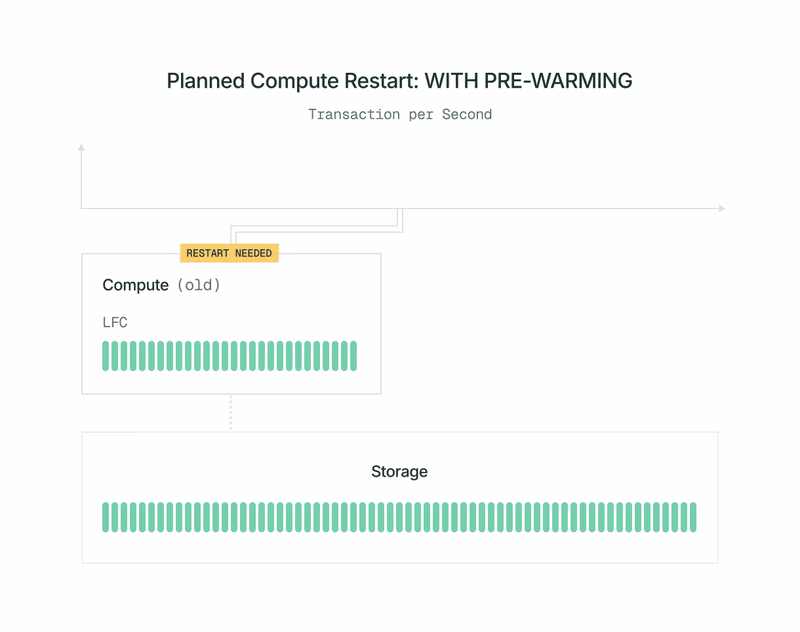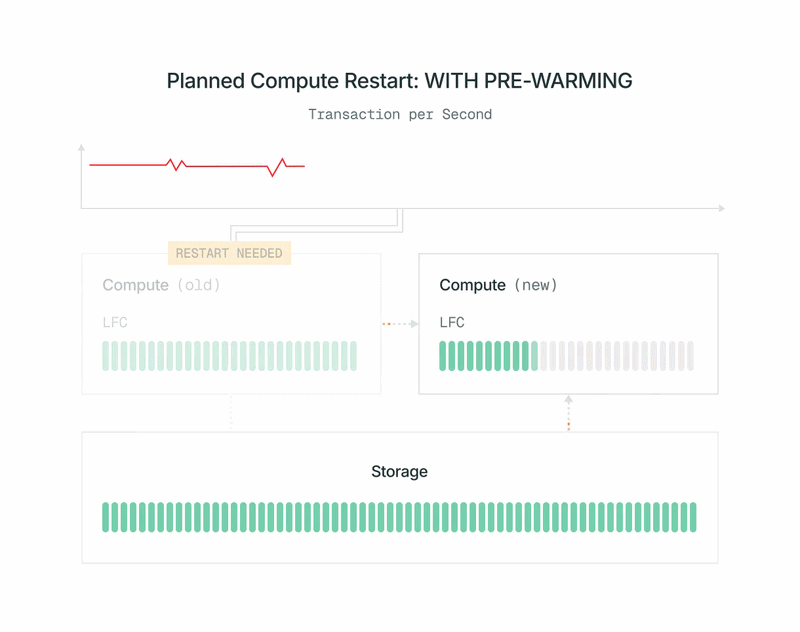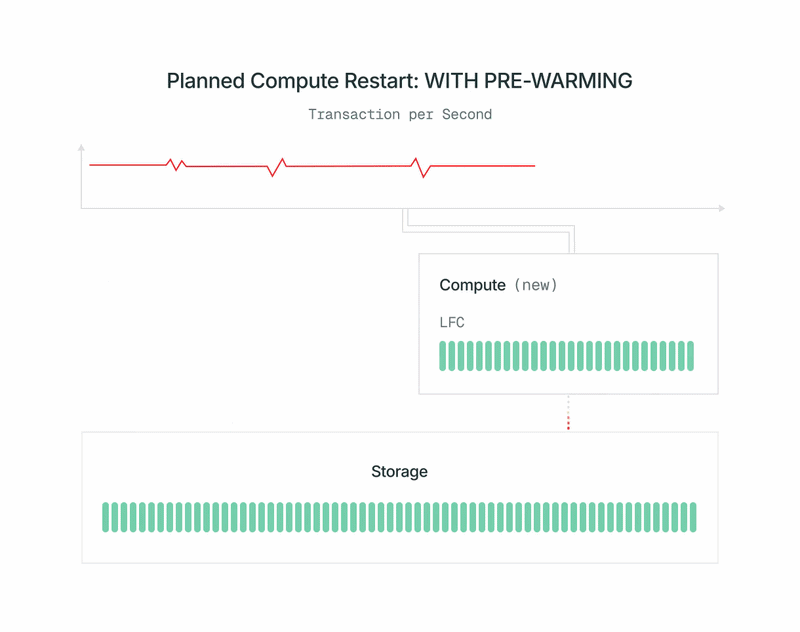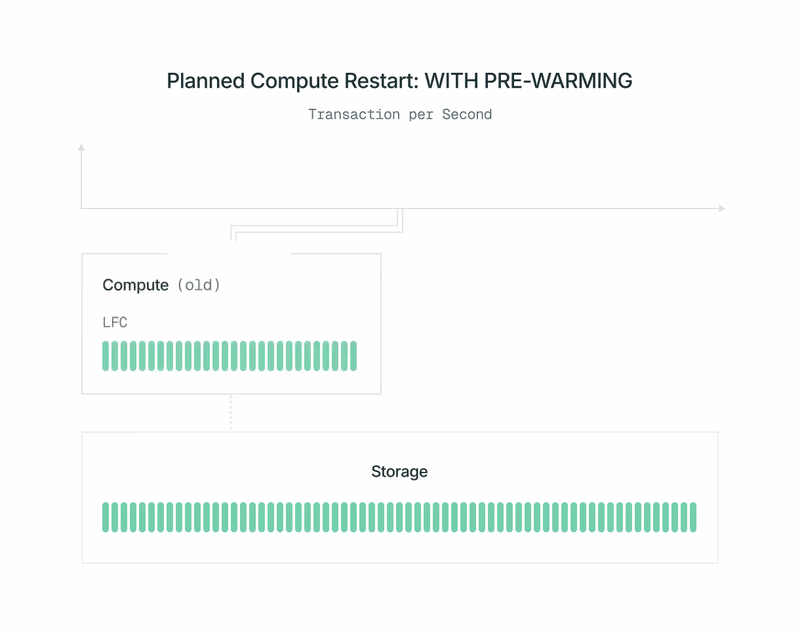
- Lakebase의 Postgres 컴퓨팅 이미지의 새 버전이 출시됩니다. 사용자는 알림을 받고, 자신에게 적합한 시간에 재시작을 예약할 수 있습니다.
- 예약된 시간 직전에, 컨트롤 플레인(control plane)이 백그라운드에서 새 Postgres 컴퓨팅을 구동합니다. 사용자에게는 보이지 않으며, 비용도 청구되지 않습니다. 현재 프라이머리의 워크로드는 영향을 받지 않습니다.
- 현재 프라이머리의 캐시에 있는 페이지 목록이 새 컴퓨팅으로 전송됩니다. 새 컴퓨팅은 프라이머리에 부하를 주지 않고, 공유 스토리지 계층에서 해당 페이지들을 캐시에 로드합니다.
- 새 컴퓨팅이 WAL(write-ahead log)을 구독하여 캐시를 최신 상태로 유지합니다. 일반적인 Postgres 레플리카와 달리, 효율성을 위해 캐시에 영향을 미치지 않는 WAL 레코드는 모두 무시할 수 있습니다. WAL은 Safekeeper로부터 수신되므로, 프라이머리 컴퓨팅에 추가적인 부하를 주지 않습니다.
- 프리워밍이 완료되면, 기존 프라이머리를 신속하게 종료하고, 새 컴퓨팅을 프라이머리로 승격시킨 후 전환합니다. 승격은 OSS Postgres의 표준
pg_promote를 사용하며, 데이터베이스 서버를 재시작하지 않습니다.
결과: 콜드 캐시의 영향 측정
콜드 캐시의 영향을 측정하기 위해, 10 GB pgbench(스케일 팩터 670)를 실행 중인 데이터베이스를 재시작하는 테스트를 진행했습니다. 먼저 프리워밍을 활성화한 상태에서, 그 다음에는 프리워밍 없이 테스트했습니다. 첫 번째 차트는 읽기 전용 워크로드(pgbench “select only”)를, 두 번째는 읽기/쓰기 워크로드(pgbench “simple update”)를 보여줍니다.
 두 경우 모두, 프리워밍을 사용하면 처리량이 거의 즉시 회복되는 것을 확인할 수 있습니다. 프리워밍 없이는 콜드 캐시가 워밍업되는 동안 회복이 훨씬 느립니다. 읽기 전용 워크로드에서 차이가 가장 두드러지는데, 이는 프리워밍이 캐시 히트율(cache hit ratio)을 개선하고, 이것이 쓰기보다 읽기에 더 비례적으로 도움이 되기 때문입니다.
두 경우 모두, 프리워밍을 사용하면 처리량이 거의 즉시 회복되는 것을 확인할 수 있습니다. 프리워밍 없이는 콜드 캐시가 워밍업되는 동안 회복이 훨씬 느립니다. 읽기 전용 워크로드에서 차이가 가장 두드러지는데, 이는 프리워밍이 캐시 히트율(cache hit ratio)을 개선하고, 이것이 쓰기보다 읽기에 더 비례적으로 도움이 되기 때문입니다.