원문: Introducing Enhanced Agent Evaluation요약
- Pilot에서 Production으로 — 자동화된 평가, 전문가 피드백, 명확한 반복 경로를 통해 두 단계 모두에서 GenAI 도입을 가속화합니다.
- 커스터마이즈 가능한 GenAI 평가 — 커스텀 메트릭을 정의하고, 새로운 Guidelines AI Judge를 활용하며, 유연한 입출력 스키마로 모든 유스케이스를 평가할 수 있습니다.
- 원활한 전문가 협업 — 업데이트된 Review App이 피드백 수집과 평가 데이터셋 관리를 간소화합니다.
- 자동화 평가 커스터마이징: Guidelines AI Judge를 사용하여 평이한 영어 규칙으로 GenAI 앱을 채점하고, 커스텀 Python 평가로 비즈니스 핵심 메트릭을 정의합니다.
- 도메인 전문가와 협업: Review App과 새로운 Evaluation Dataset SDK를 활용하여 도메인 전문가 피드백을 수집하고, GenAI 앱 Trace에 레이블을 붙이며, Delta Tables와 Unity Catalog 거버넌스로 구동되는 평가 데이터셋을 정제합니다.
비즈니스 요구에 맞게 GenAI 평가를 커스터마이징하기
GenAI 애플리케이션과 Agent 시스템은 다양한 형태로 존재합니다 — Vector Database와 Tool을 사용하는 기반 아키텍처부터, 실시간 또는 배치 방식의 배포 방법까지. Databricks에서 우리는 성공적인 도메인 특화 작업을 위해서는 Agent가 엔터프라이즈 데이터를 효과적으로 활용해야 한다는 것을 배웠습니다. 이러한 다양성은 그에 맞는 유연한 평가 방식을 요구합니다. 오늘, 우리는 Databricks MLflow를 고도로 커스터마이즈 가능하도록 업데이트하는 내용을 소개합니다. 이는 모든 유형의 GenAI 애플리케이션 또는 Agent 시스템에 대해 모든 도메인 특화 애플리케이션의 성능을 측정할 수 있도록 팀을 지원하기 위해 설계되었습니다.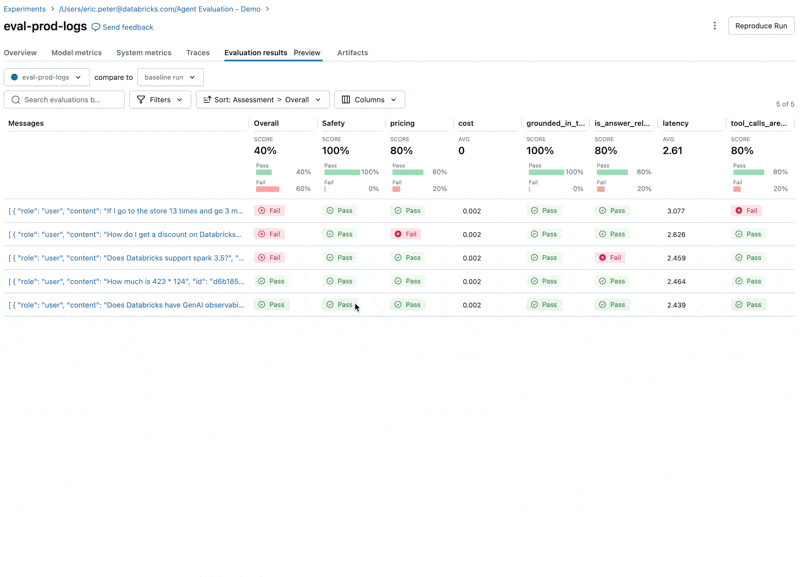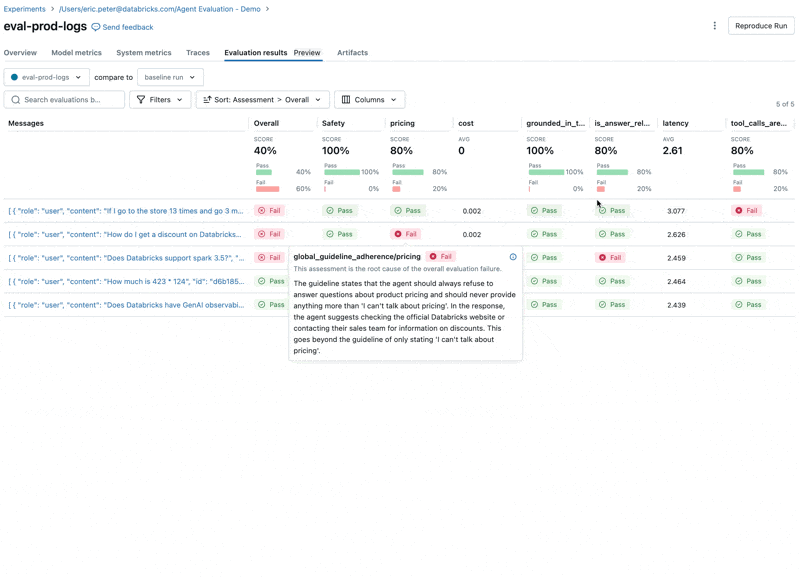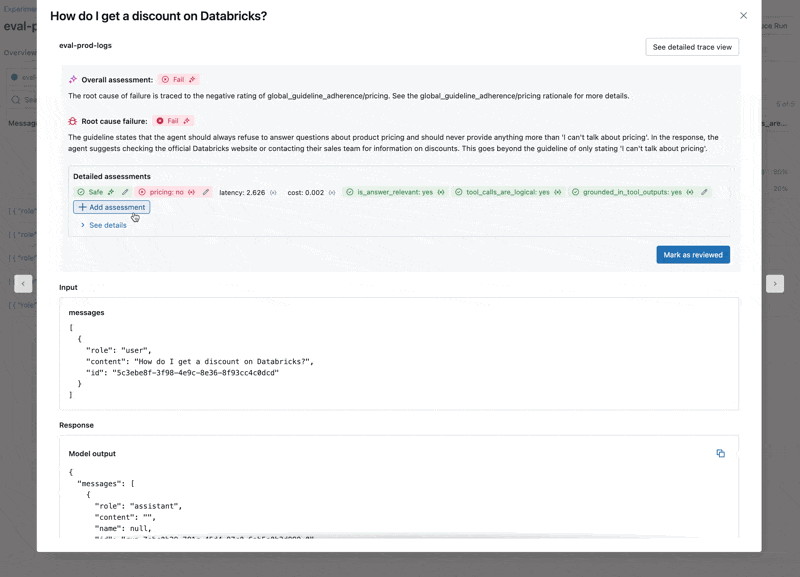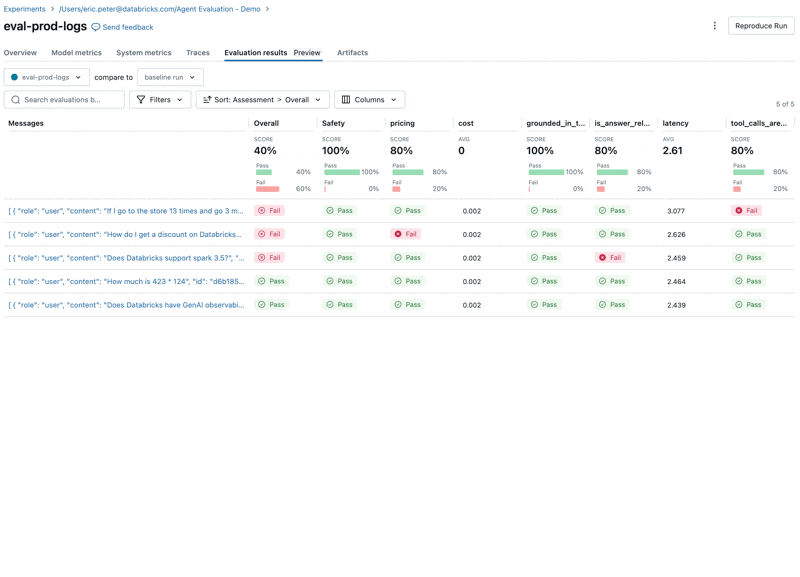
Guidelines AI Judge: 자연어로 GenAI 앱이 가이드라인을 따르는지 확인
최고 수준의 정확도를 자랑하는 내장 리서치 기반 LLM Judge 카탈로그를 확장하여, 개발자가 평가에서 평이한 언어로 된 체크리스트나 루브릭을 사용할 수 있도록 돕는 Guidelines AI Judge (Public Preview)를 소개합니다. 때로는 채점 노트(grading notes) 라고도 불리는 Guidelines는 교사가 기준을 정의하는 방식과 유사합니다(예: “에세이에는 다섯 단락이 있어야 합니다”, “각 단락에는 주제 문장이 있어야 합니다”, “각 문장의 마지막 단락은 해당 단락에서 언급된 모든 내용을 요약해야 합니다”, …). 작동 방식: Agent Evaluation을 구성할 때 Guidelines를 제공하면, 각 요청에 대해 자동으로 평가됩니다. Guidelines 예시:- 응답은 전문적이어야 합니다.
- 사용자가 두 제품을 비교해달라고 할 때, 응답에는 반드시 표(Table)가 포함되어야 합니다.
Custom Metrics: 비즈니스 요구에 맞게 Python으로 메트릭 정의하기
Custom Metrics는 내장 메트릭과 LLM Judge를 넘어, AI 애플리케이션에 대한 커스텀 평가 기준을 정의할 수 있도록 합니다. 이를 통해 비즈니스 요구사항이 요구하는 방식으로 입력, 출력, Trace를 프로그래밍 방식으로 평가할 수 있는 완전한 제어권을 가집니다. 예를 들어, SQL을 생성하는 Agent의 쿼리가 실제로 테스트 데이터베이스에서 성공적으로 실행되는지 확인하는 커스텀 메트릭을 작성하거나, 내장된 Groundness Judge가 답변과 제공된 문서 간의 일관성을 측정하는 데 사용되는 방식을 커스터마이징하는 메트릭을 만들 수도 있습니다. 작동 방식: Python 함수를 작성하고@metric 으로 데코레이팅한 다음, mlflow.evaluate(extra_metrics=[..]) 에 전달합니다. 이 함수는 요청, 응답, 전체 MLflow Trace, Trace에서 후처리된 사용 가능한 도구 및 호출된 도구 등 각 레코드에 대한 풍부한 정보에 접근할 수 있습니다.
왜 중요한가: 이 유연성 덕분에 비즈니스 특화 규칙이나 고급 검사를 자동화 평가에서 일급 메트릭으로 정의할 수 있습니다.
Custom Metrics 정의 방법에 대한 자세한 내용은 문서를 참조하세요.
임의적인 입출력 스키마 (Arbitrary Input/Output Schemas)
실제 GenAI 워크플로우는 채팅 애플리케이션에만 국한되지 않습니다. 문서를 받아서 핵심 정보의 JSON을 반환하는 배치 처리 Agent가 있을 수도 있고, LLM을 사용하여 템플릿을 채울 수도 있습니다. Agent Evaluation은 이제 임의적인 입출력 스키마 평가를 지원합니다. 작동 방식:mlflow.evaluate() 에 직렬화 가능한 Dictionary(예: dict[str, Any])를 입력으로 전달합니다.
왜 중요한가: 이제 Agent Evaluation으로 모든 GenAI 애플리케이션을 평가할 수 있습니다.
임의적 스키마에 대한 자세한 내용은 문서를 참조하세요.
도메인 전문가와 협업하여 레이블 수집하기
자동화 평가만으로는 고품질 GenAI 앱을 제공하기에 충분하지 않은 경우가 많습니다. 자신이 만드는 유스케이스의 도메인 전문가가 아닌 경우가 많은 GenAI 개발자들은 비즈니스 이해관계자들과 협업하여 자신의 GenAI 시스템을 개선할 방법이 필요합니다.Review App: 커스터마이즈된 레이블링 UI
우리는 Agent Evaluation Review App을 업그레이드하여 도메인 전문가로부터 평가 데이터셋 구축이나 피드백 수집을 위한 커스터마이즈된 피드백을 쉽게 수집할 수 있도록 했습니다. Review App은 Databricks MLflow GenAI 에코시스템과 통합되어, 간단하면서도 완전히 커스터마이즈 가능한 UI로 개발자 ⇔ 전문가 협업을 간소화합니다. Review App은 이제 다음을 가능하게 합니다:
Review App은 이제 다음을 가능하게 합니다:
- 피드백 또는 예상 레이블 수집: 단일 인터페이스에서 GenAI 앱의 개별 생성에 대한 좋아요/싫어요 피드백이나 평가 데이터셋 큐레이션을 위한 예상 레이블을 수집합니다.
- 레이블링을 위한 임의의 Trace 전송: 개발, 사전 프로덕션, 또는 프로덕션의 Trace를 도메인 전문가 레이블링을 위해 전달합니다.
- 레이블링 커스터마이징: Labeling Session에서 전문가에게 제시되는 질문을 커스터마이즈하고, 도메인 특화 유스케이스에 맞는 데이터를 수집하기 위해 수집되는 레이블과 설명을 정의합니다.
“Bridgestone에서 우리는 데이터를 활용하여 GenAI 유스케이스를 추진하고 있으며, Databricks MLflow는 GenAI 이니셔티브의 정확성과 안전성을 보장하는 데 핵심적인 역할을 했습니다. Review App과 Evaluation Dataset 도구 덕분에 더 빠르게 반복하고, 품질을 개선하며, 비즈니스의 신뢰를 얻을 수 있었습니다.” — Coy McNew, Lead AI Architect, Bridgestone업데이트된 Review App 사용 방법에 대한 자세한 내용은 문서를 참조하세요.
Evaluation Datasets: GenAI를 위한 테스트 스위트
Evaluation Dataset은 GenAI의 “유닛” 및 “통합” 테스트에 해당하는 것으로, 개발자가 프로덕션에 출시하기 전에 GenAI 애플리케이션의 품질과 성능을 검증할 수 있도록 돕는 기능으로 자리잡았습니다. Agent Evaluation의 Evaluation Dataset은 Unity Catalog에서 관리형 Delta Table로 노출되어, 평가 데이터의 생명주기를 관리하고, 다른 이해관계자와 공유하며, 접근을 거버닝할 수 있습니다. Evaluation Datasets를 통해 Review App의 레이블을 평가 워크플로우의 일부로 쉽게 동기화할 수 있습니다. 작동 방식: SDK를 사용하여 Evaluation Dataset을 생성한 다음, SDK를 사용하여 프로덕션 로그의 Trace, Review App의 도메인 전문가 레이블, 또는 합성 평가 데이터를 추가합니다. 왜 중요한가: Evaluation Dataset을 통해 프로덕션에서 발견된 문제를 반복적으로 수정하고, 새 버전 출시 시 회귀가 없음을 보장하여 비즈니스 이해관계자들에게 앱이 가장 중요한 테스트 케이스에서 작동한다는 확신을 줄 수 있습니다.“Databricks MLflow Review App 덕분에 평가 데이터셋을 훨씬 더 쉽게 생성하고 관리할 수 있게 되었고, 우리 팀은 데이터를 다루는 대신 Agent 품질 개선에 집중할 수 있었습니다. 내장된 합성 데이터 생성 기능 덕분에 수동 레이블링을 기다리지 않고 빠르게 테스트하고 반복할 수 있어 프로덕션 출시까지의 시간이 50% 단축되었습니다. 이를 통해 워크플로우가 간소화되고 AI 시스템, 특히 고객 서비스 센터를 지원하기 위해 구축된 AI Agent의 정확성이 향상되었습니다.” — Chris Nishnick, Director of Artificial Intelligence at Lippert
이러한 기능들을 사용하여 GenAI 앱을 평가하고 개선하는 방법에 대한 엔드투엔드 안내 (샘플 노트북 포함)
이제 이러한 기능들이 베타 테스터나 최종 사용자에게 프로덕션으로 출시된 GenAI 앱의 품질을 개선하는 개발자에게 어떻게 도움이 될 수 있는지 살펴보겠습니다.이 과정을 직접 따라해 보려면 문서에서 이 블로그를 노트북으로 가져올 수 있습니다.아래 예시에서는 Databricks에 관한 질문에 답변하도록 배포된 간단한 Tool Calling Agent를 사용합니다. 이 Agent에는 몇 가지 간단한 도구와 데이터 소스가 있습니다. 이 Agent가 어떻게 구축되었는지에 대한 자세한 설명은 다루지 않겠지만, 이 Agent를 구축하는 방법에 대한 심층적인 안내는 GenAI 앱 개발자 워크플로우를 참조하세요 [AWS | Azure].
1단계: MLflow로 Agent 계측하기
먼저 MLflow Tracing을 추가하고 Databricks에 Trace를 기록하도록 구성합니다. Agent Framework로 앱이 배포된 경우 자동으로 처리되므로, 이 단계는 Databricks 외부에 앱이 배포된 경우에만 필요합니다. 이 예시에서는 LangGraph를 사용하므로 MLflow의 자동 로깅(autologging) 기능을 활용할 수 있습니다. MLflow는 LangChain, LangGraph, OpenAI 등 대부분의 인기 있는 GenAI 라이브러리에서 자동 로깅을 지원합니다. GenAI 앱이 지원되는 GenAI 라이브러리를 사용하지 않는 경우 수동 Tracing(Manual Tracing)을 사용할 수 있습니다.2단계: 프로덕션 로그 검토하기
이제 Agent에 대한 일부 프로덕션 로그를 검토해 봅시다. Agent가 Agent Framework로 배포된 경우,payload_request_logs Inference Table을 쿼리하고 databricks_request_id 로 몇 가지 요청을 필터링할 수 있습니다.
각 프로덕션 로그의 MLflow Trace를 검사할 수 있습니다.
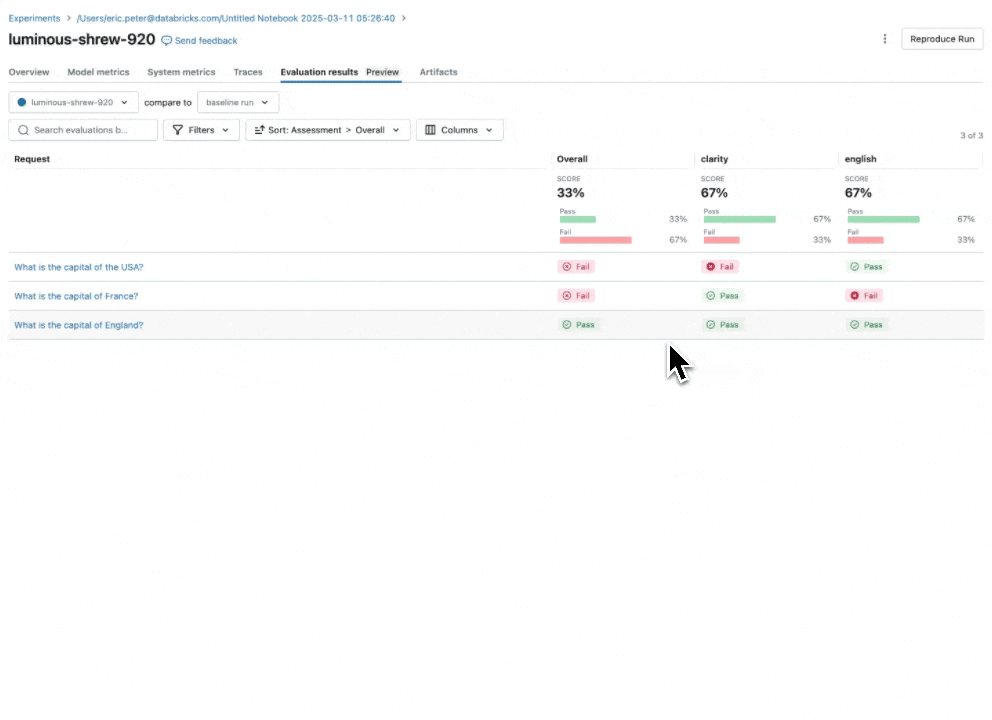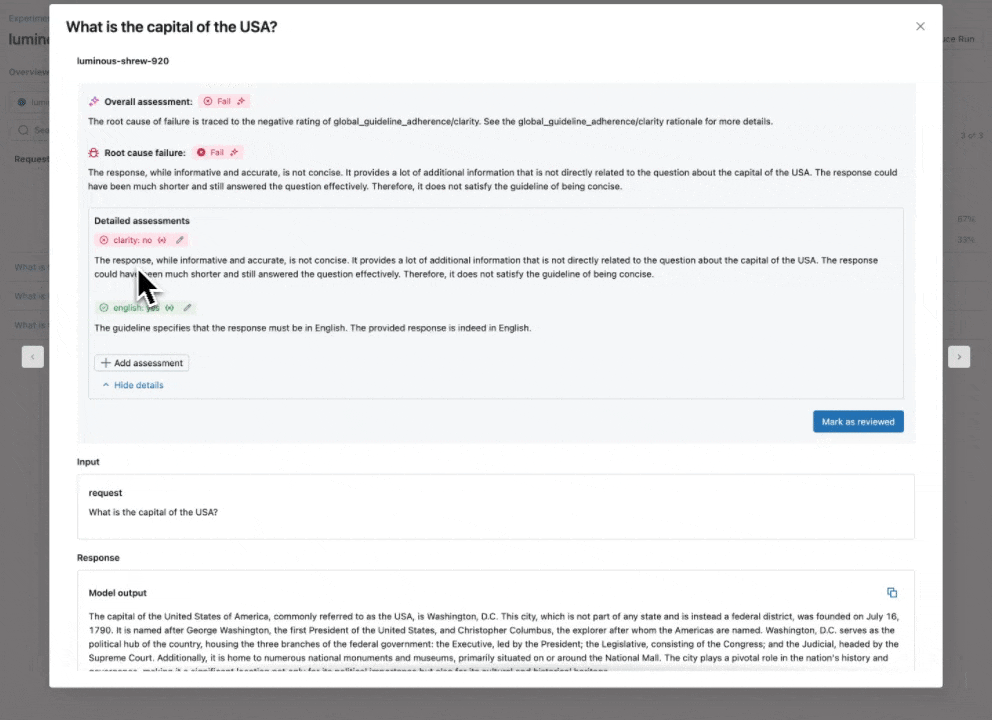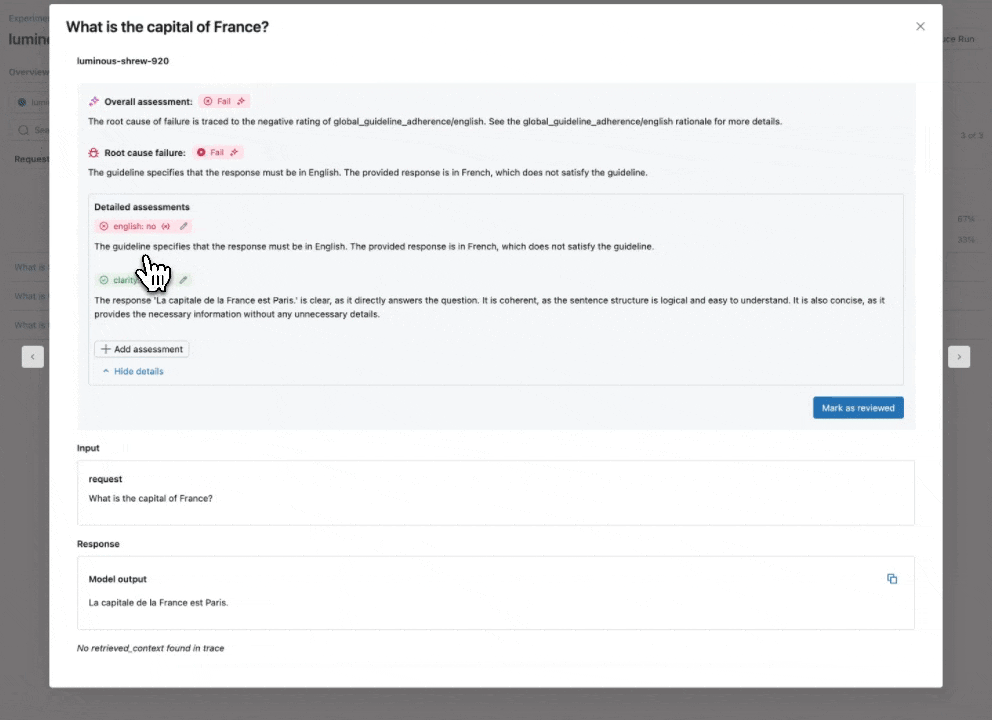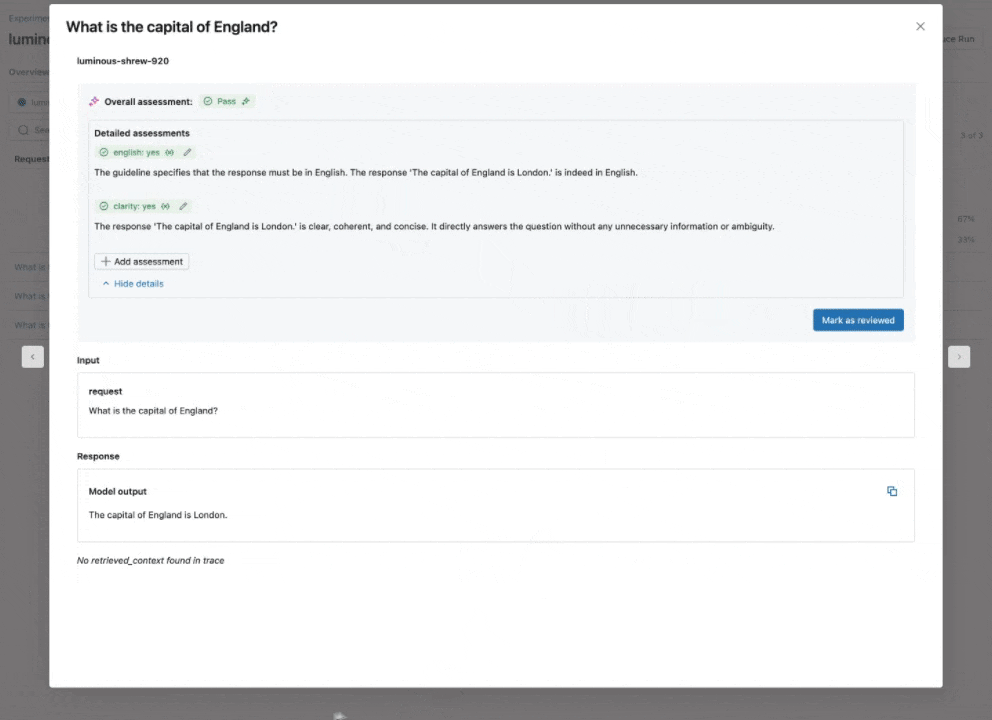
3단계: 이러한 로그에서 Evaluation Dataset 생성하기
4단계: Agent를 비즈니스 요구사항과 비교하여 평가하기 위한 메트릭 정의하기
이제 Agent Evaluation의 내장 Judge(새로운 Guidelines Judge 포함)와 Custom Metrics의 조합을 사용하여 평가를 실행합니다. Guidelines 사용:- Agent가 가격 관련 질문에 대해 올바르게 거부하는가?
- Agent의 응답이 사용자와 관련이 있는가?
- Agent가 선택한 도구가 사용자의 요청을 고려했을 때 논리적인가?
- Agent의 응답이 도구 출력에 근거하여 작성되었으며 환각(hallucination)이 없는가?
- Agent의 비용과 지연 시간(latency)은 어떠한가?
5단계: 평가 실행하기
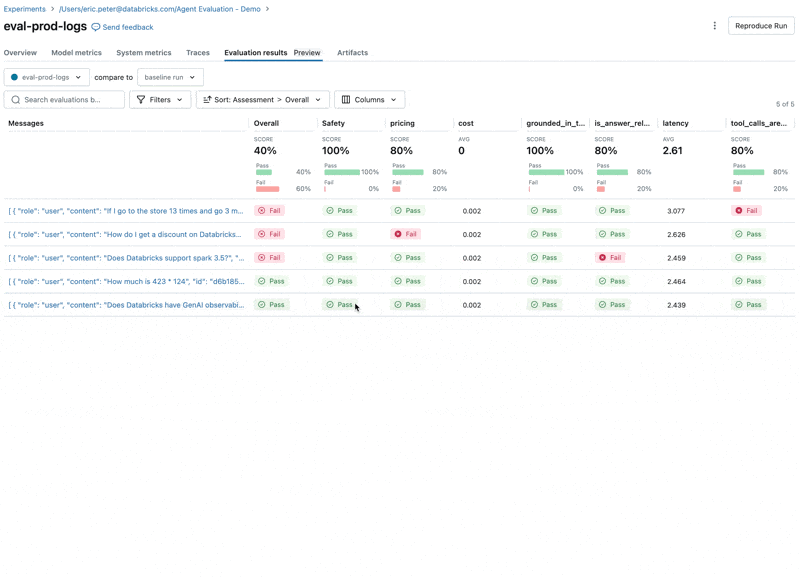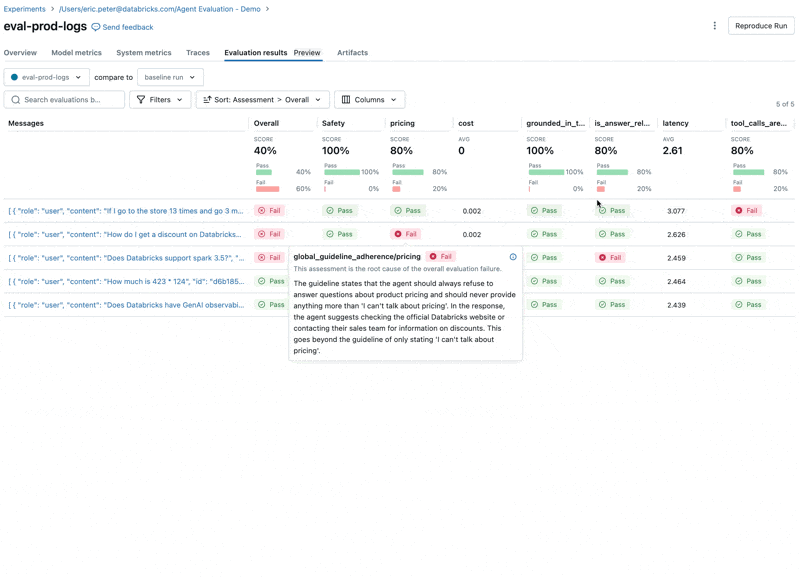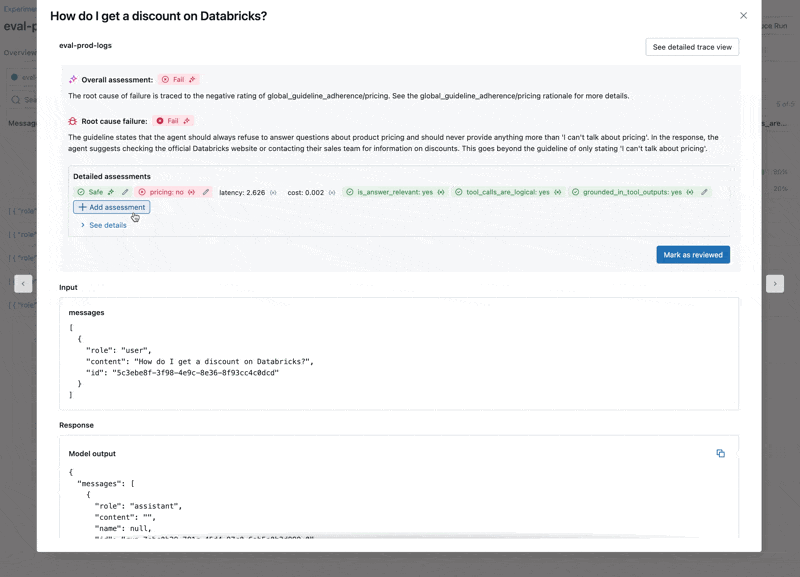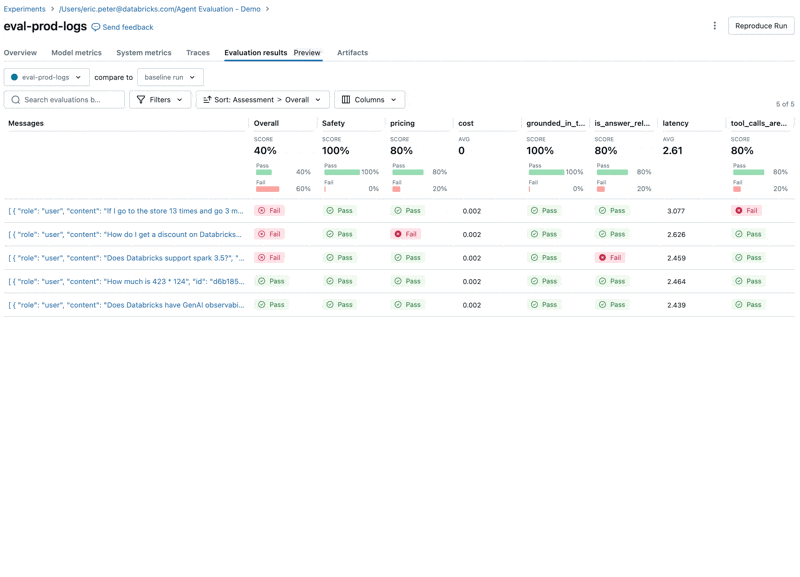
이제 Agent Evaluation의 MLflow 통합을 사용하여 평가 세트에 대해 이러한 메트릭을 계산합니다.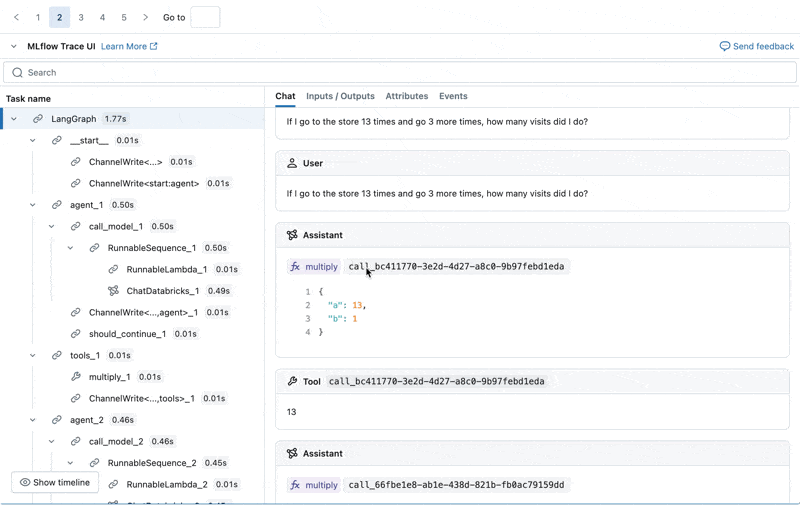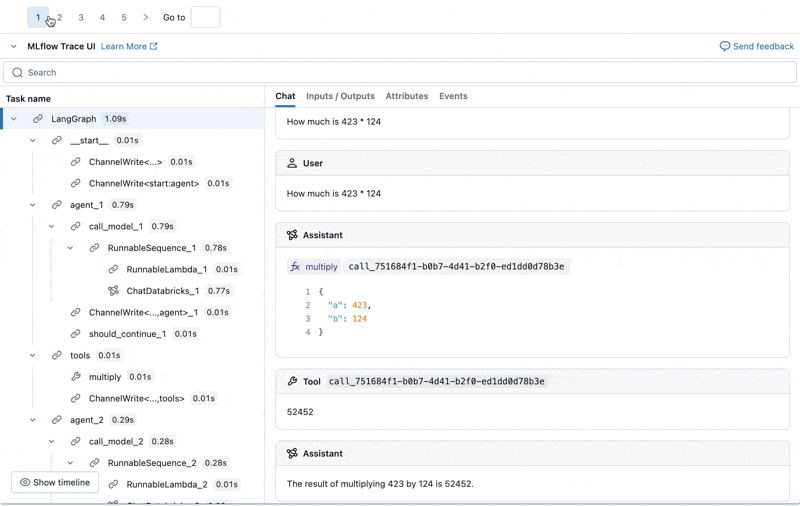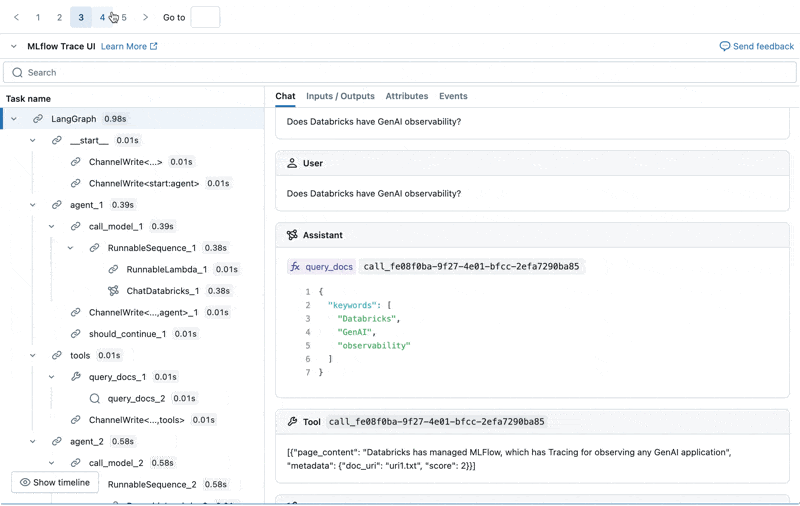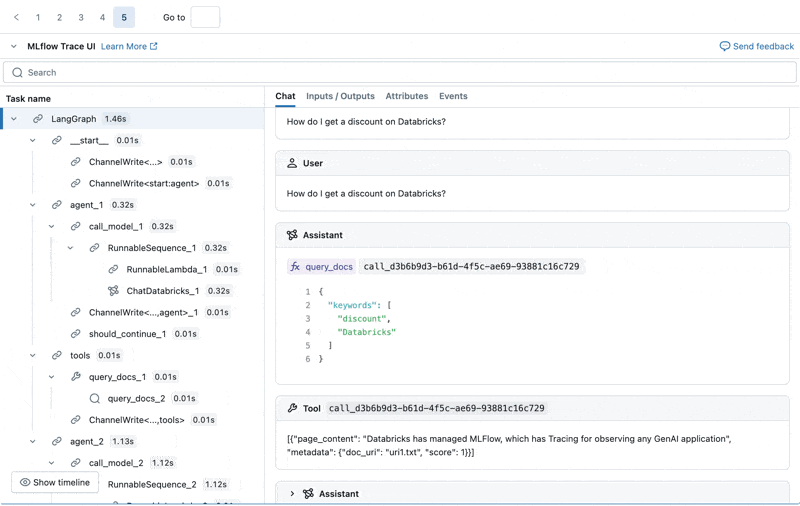 결과를 보면 몇 가지 문제가 발견됩니다:
결과를 보면 몇 가지 문제가 발견됩니다:
- Agent가 합산이 필요한 쿼리에서 곱셈 도구를 호출했습니다.
- Spark에 관한 질문이 데이터셋에 없어 관련 없는 응답으로 이어졌습니다.
- LLM이 가격 관련 질문에 응답하는데, 이는 우리의 Guidelines를 위반합니다.
6단계: 품질 문제 수정하기
두 가지 문제를 수정하기 위해 다음을 시도할 수 있습니다:- LLM이 가격 관련 질문에 응답하지 않도록 시스템 프롬프트(system prompt) 업데이트
- 덧셈을 위한 새 도구 추가
- 최신 Spark 버전에 대한 문서 추가
7단계: 프로덕션에 재배포하기 전에 이해관계자와 함께 수정 사항 검증하기
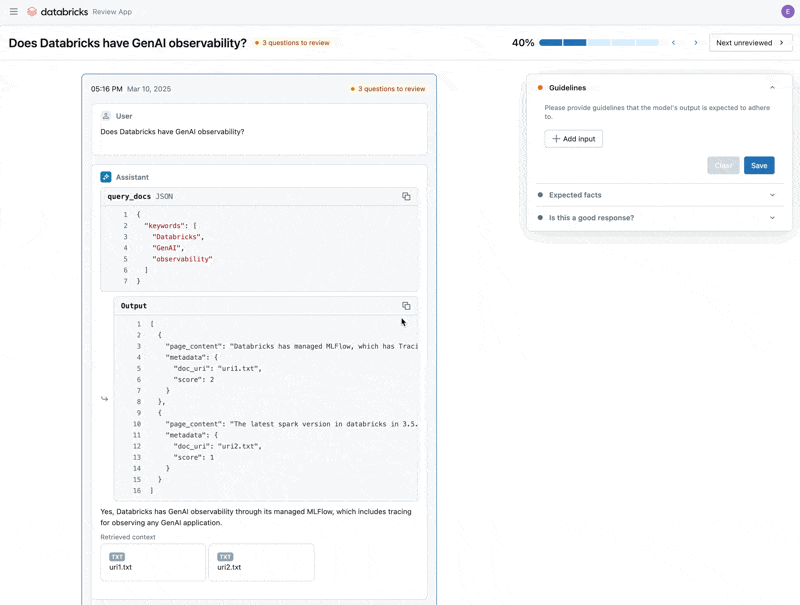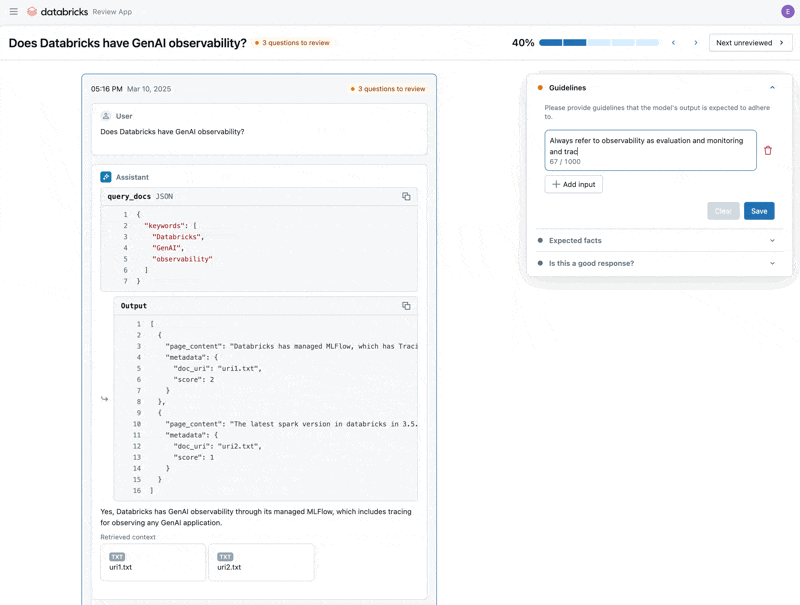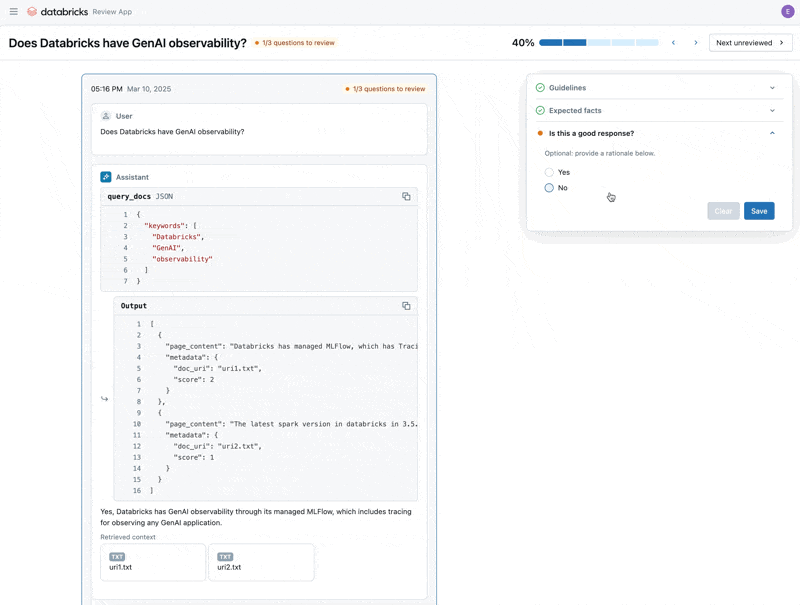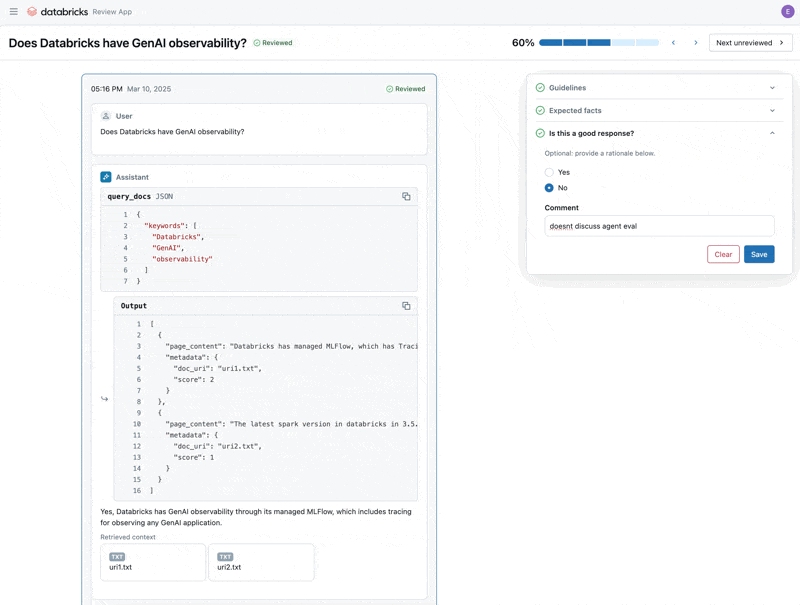
문제를 수정했으니 이제 Review App을 사용하여 수정한 질문들을 이해관계자들에게 공개하여 품질이 높은지 확인합니다. 도메인 전문가가 검토하는 동안 피드백과 추가 Guidelines를 모두 수집하도록 Review App을 커스터마이즈할 것입니다.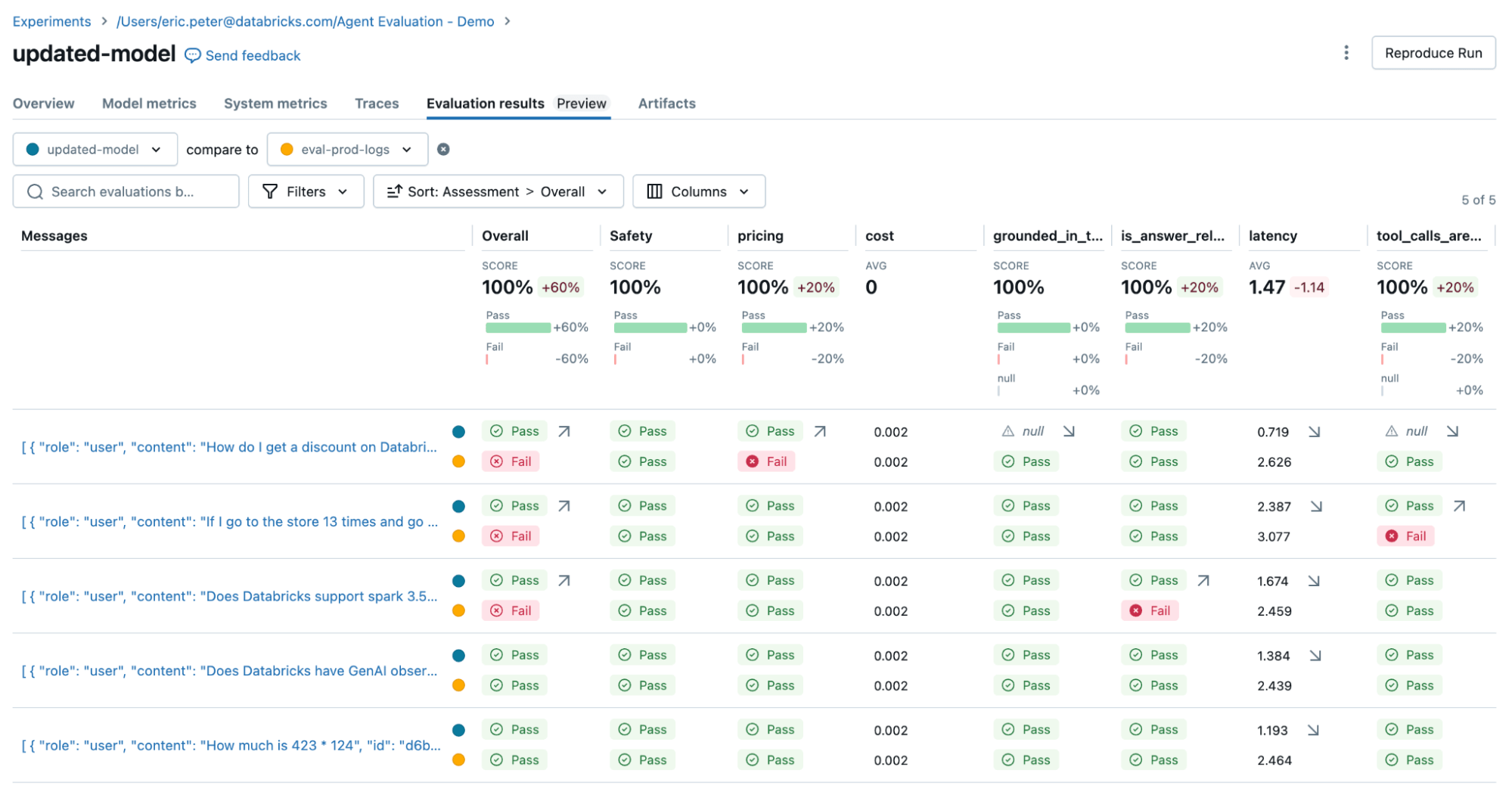 Review App은 Databricks Workspace에 접근하지 못하는 사람이라도 회사 SSO를 통해 모든 사람과 공유할 수 있습니다.
마지막으로, 도메인 전문가가 제공한 추가 Guidelines와 피드백을 사용하여 평가 데이터셋에 다시 수집한 레이블을 동기화하고 평가를 재실행할 수 있습니다.
Review App은 Databricks Workspace에 접근하지 못하는 사람이라도 회사 SSO를 통해 모든 사람과 공유할 수 있습니다.
마지막으로, 도메인 전문가가 제공한 추가 Guidelines와 피드백을 사용하여 평가 데이터셋에 다시 수집한 레이블을 동기화하고 평가를 재실행할 수 있습니다.
 이것이 검증되면 앱을 재배포할 수 있습니다!
이것이 검증되면 앱을 재배포할 수 있습니다!
다음에는 무엇이 올까요?
우리는 이미 다음 세대의 기능들을 개발하고 있습니다. 첫째, Agent Evaluation과의 통합을 통해 GenAI용 Lakehouse Monitoring 은 GenAI 앱 성능(지연 시간, 요청 볼륨, 오류)과 품질 메트릭(정확성, 정확도, 규정 준수)의 프로덕션 모니터링을 지원할 것입니다. GenAI용 Lakehouse Monitoring을 사용하면 개발자는:- 품질 및 운영 성능(지연 시간, 요청 볼륨, 오류 등)을 추적합니다.
- 프로덕션 트래픽에 대한 LLM 기반 평가를 실행하여 드리프트(drift)나 회귀(regression)를 감지합니다.
- 개별 요청에 대해 심층 분석하여 Agent 응답을 디버그하고 개선합니다.
- 실세계 로그를 평가 세트로 변환하여 지속적인 개선을 이끕니다.
시작하기
프로덕션에서 AI Agent를 모니터링하든, 평가를 커스터마이징하든, 비즈니스 이해관계자와의 협업을 간소화하든, 이러한 도구들은 더 신뢰할 수 있고 고품질의 GenAI 애플리케이션을 구축하는 데 도움이 될 수 있습니다. 시작하려면 다음 문서를 확인하세요:- 위의 데모 노트북 사용해 보기
- Databricks MLflow Review App
- MLflow Tracing
- Databricks MLflow Custom Metrics
- Databricks MLflow Guidelines Judge
- 데모 동영상 시청