원문: Introducing MLflow Tracing (2024-06-10)작성자: MLflow 메인테이너
MLflow의 강력한 새 기능인 MLflow Tracing의 출시를 발표하게 되어 기쁩니다. 이 기능은 GenAI 애플리케이션에 포괄적인 계측(instrumentation) 기능을 제공하여, 간단한 채팅 인터페이스부터 복잡한 다단계 RAG(Retrieval Augmented Generation) 애플리케이션에 이르기까지 모델과 워크플로우의 실행에 대한 심층적인 인사이트를 얻을 수 있게 합니다.
참고: MLflow Tracing은 버전 2.14.0 이상이 필요합니다.
MLflow Tracing이란?
MLflow Tracing은 애플리케이션에서 트레이싱을 활성화하기 위한 다양한 방법을 제공합니다:- LangChain을 통한 자동 트레이싱:
mlflow.langchain.autolog()을 활성화하는 것만으로 완전히 자동화된 LangChain 통합을 사용할 수 있습니다. - 고수준 Fluent API를 통한 수동 트레이스 계측: 데코레이터, 함수 래퍼, 컨텍스트 매니저를 사용하는 fluent API로 최소한의 코드 수정만으로 트레이싱을 적용할 수 있습니다.
- 저수준 Client API를 통한 트레이싱: MLflow client API는 기록되는 데이터에 대한 스레드 안전(thread-safe)하고 세밀한 제어를 제공합니다.
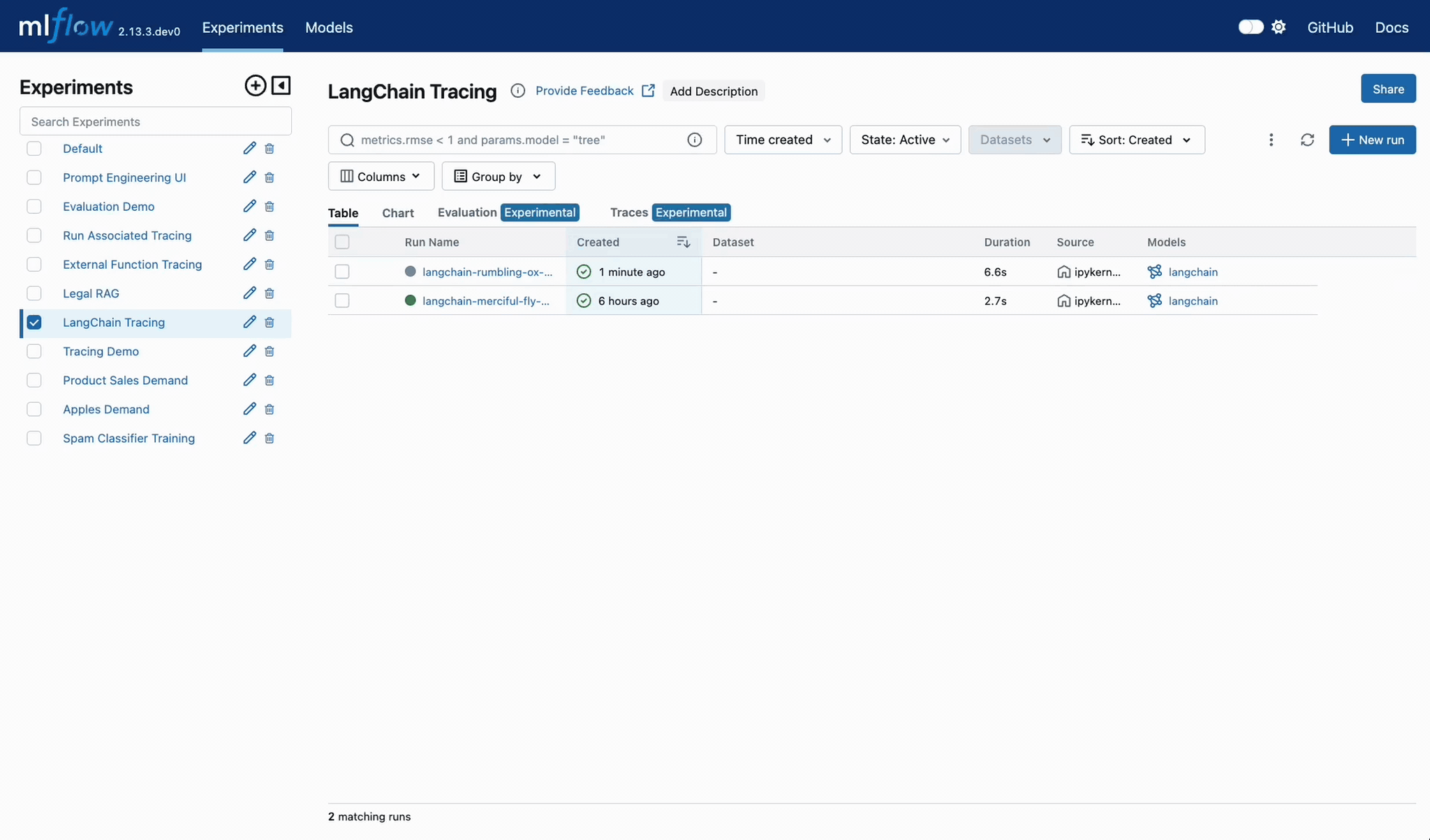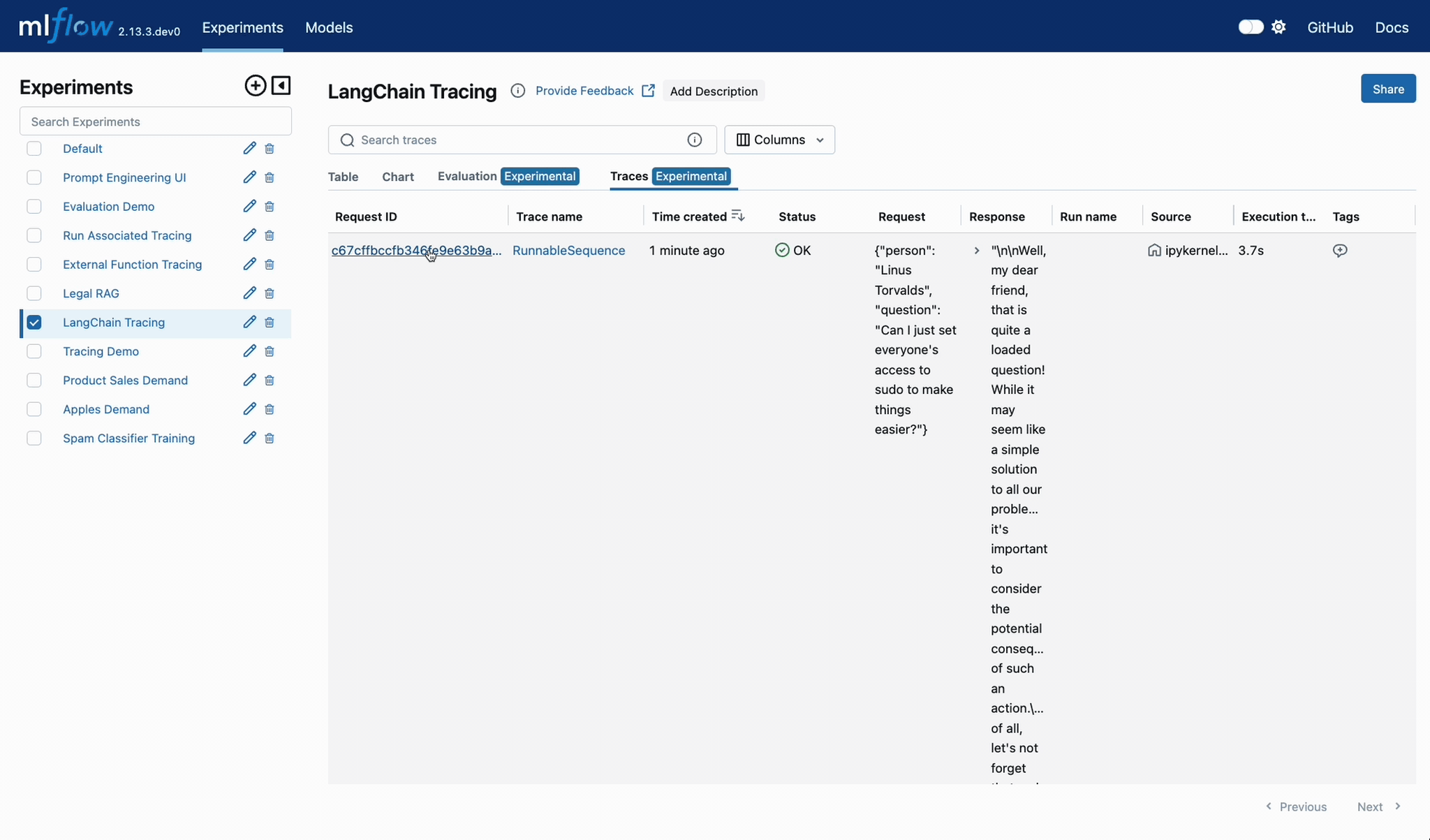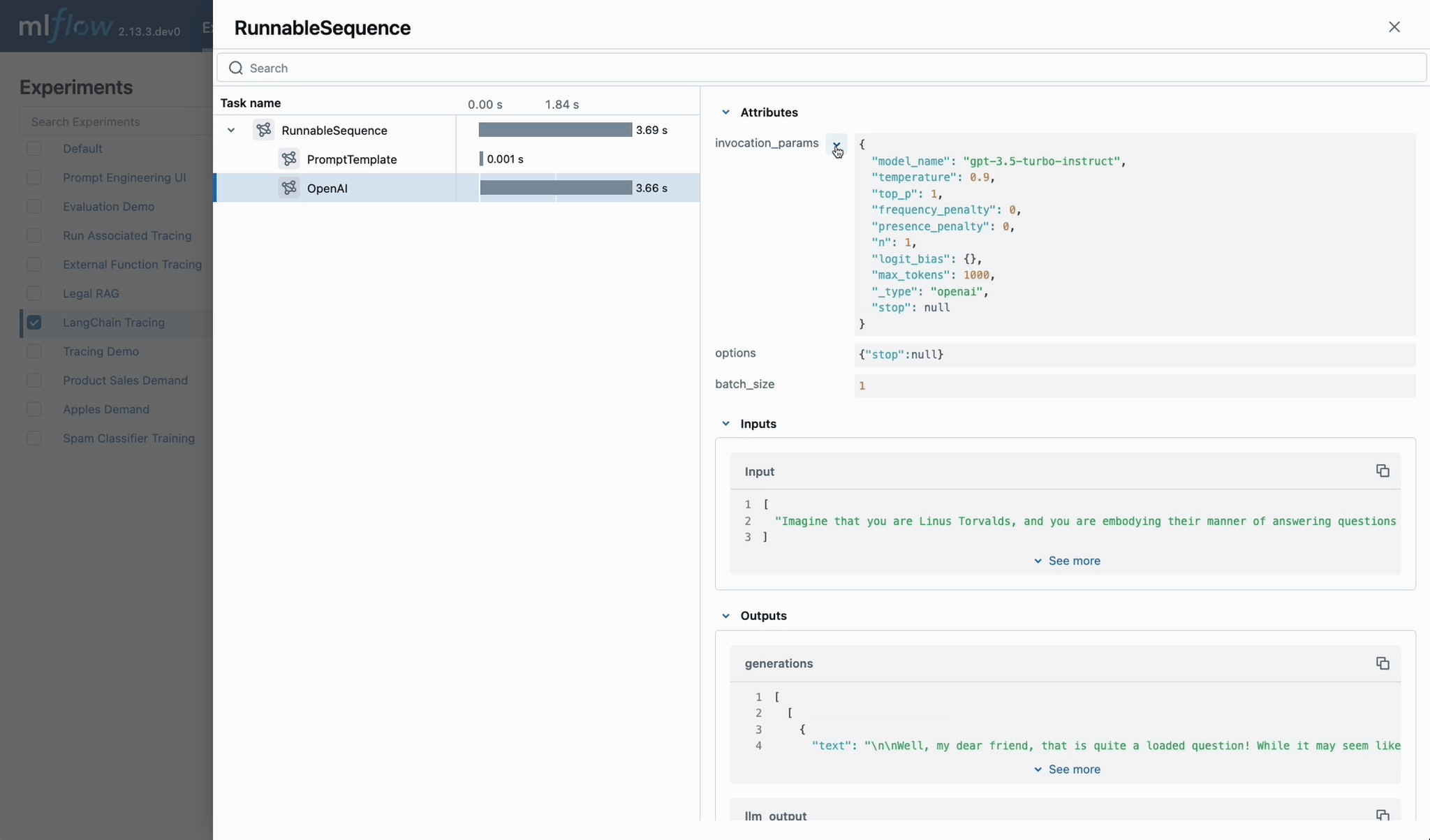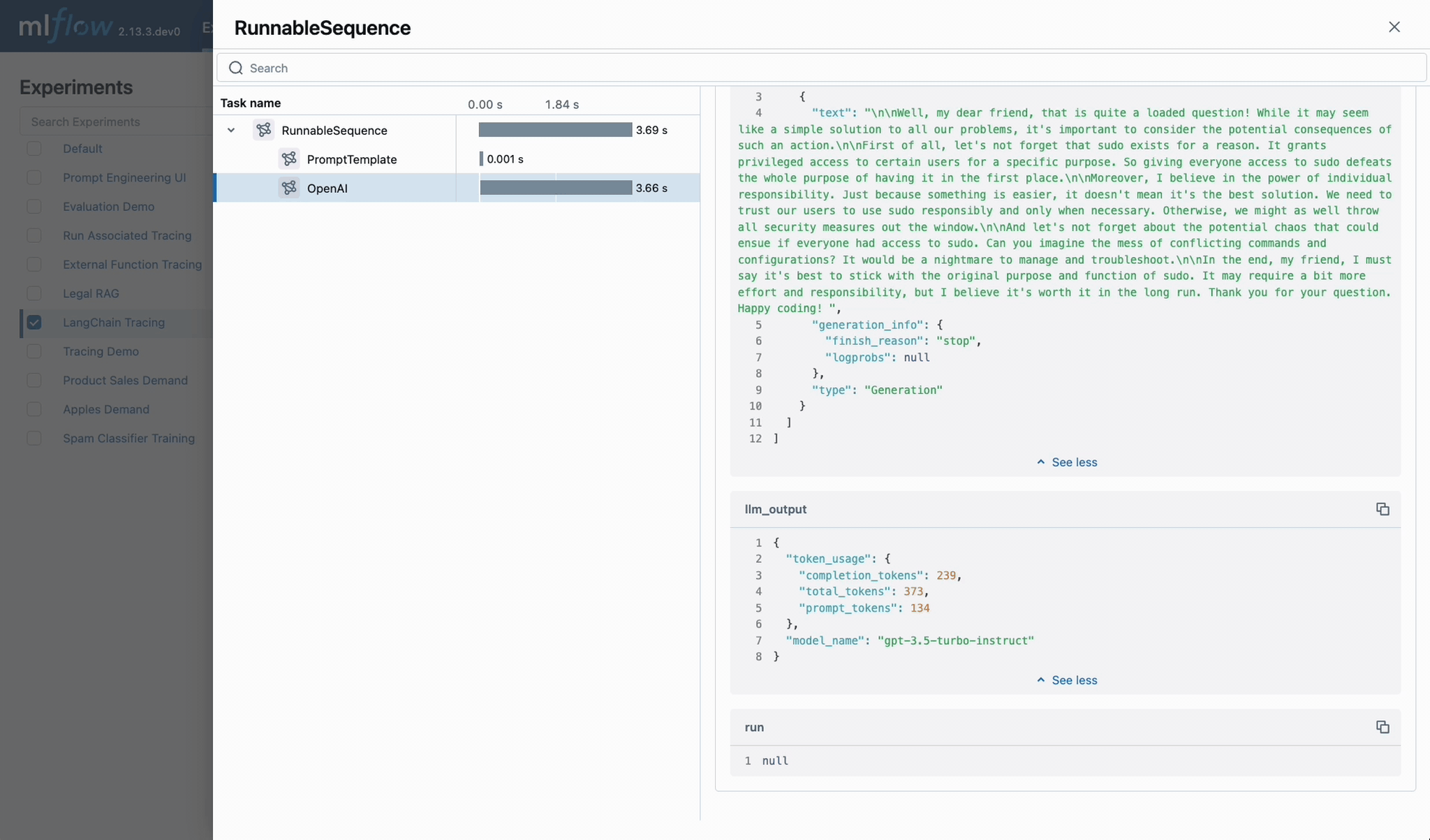
MLflow Tracing 시작하기
LangChain 자동 트레이싱
MLflow Tracing을 시작하는 가장 쉬운 방법은 LangChain과의 기본 제공 통합을 사용하는 것입니다. autologging을 활성화하면, 체인에서 호출 API를 실행할 때 트레이스가 자동으로 활성 MLflow 실험에 기록됩니다.