원문: A New Era of Databases: Lakebase
참고 요약
- 수십 년 동안 거의 변하지 않은 전통적인 데이터베이스 아키텍처는 취약하고 비용이 많이 드는 운영, 투박한 개발 경험, 극단적인 벤더 종속이라는 세 가지 구조적 한계를 가지고 있습니다.
- Lakebase는 컴퓨팅과 스토리지를 분리하고 데이터를 클라우드 오브젝트 스토리지(“레이크”)에 오픈 포맷으로 저장하는 근본적으로 새로운 아키텍처를 기반으로 합니다.
- Lakebase는 데이터베이스 진화의 다음 단계를 대표하며, 클라우드와 개발자와 AI 시대를 위해 재설계된 트랜잭션 시스템입니다.
수십 년 동안 데이터베이스는 소프트웨어의 근간이었습니다. 전자상거래 결제 흐름부터 전사적 자원 관리(Enterprise Resource Planning)에 이르기까지 모든 것을 조용히 지탱해 왔습니다. 세상에 존재하는 모든 소프트웨어, 모든 애플리케이션, 모든 워크플로우, 그리고 AI가 생성한 모든 코드 한 줄도 결국 그 아래에 데이터베이스가 있어야 동작합니다. 그 과정에서 우리는 애플리케이션을 만드는 방식을 완전히 재발명했지만, 정작 그 아래를 떠받치는 데이터베이스는 1980년대 이후 거의 변하지 않았습니다. 데이터베이스는 현대 클라우드보다 앞선 아키텍처 위에 세워져 있으며, 다음과 같은 문제를 안고 있습니다.
- 취약하고 비용이 많이 드는 운영 (Fragile & costly operations): 전통적인 데이터베이스는 가장 다루기 어려운 인프라 중 하나로 꼽히며, 안정적으로 운영하려면 흔히 “달걀 위를 걷듯” 신중하게 관리하는 전문가 집단이 필요합니다. 컴퓨팅과 스토리지를 하나의 경직된 모놀리식 단위로 묶어놓기 때문에, 팀은 최대 부하를 기준으로 용량을 미리 프로비저닝해야 하고, 그 결과 비용만 낭비되는 유휴 리소스가 생겨납니다. 부하가 프로비저닝된 용량을 초과하면 데이터베이스는 응답 불능에 빠질 수 있습니다. 더 나쁜 것은, 데이터베이스 스냅샷 생성이나 GDPR 정리 쿼리 실행 같은 단순한 유지보수 작업조차 전체 데이터베이스를 중단시킬 수도 있다는 점입니다.
- 투박한 개발 경험 (Clunky development experience): 전통적인 데이터베이스는 현대의 애자일(agile) 개발 워크플로우와 충돌합니다. 코드의 경우, 코드베이스의 완전히 격리된 클론인 개발용 git 브랜치를 1초도 안 되어 생성할 수 있습니다. 반면 데이터베이스는 프로비저닝에만 수 분에서 수 시간이 걸리며, 운영 데이터베이스의 높은 정합성(high fidelity) 클론을 가져오는 것은 비용이 엄청나게 들고 운영 데이터베이스를 중단시킬 위험도 있습니다. AI 기반 개발의 부상은 이 압박을 더욱 심화시켰습니다. AI 에이전트는 실험을 위해 임시 격리 환경을 즉시 구동해야 합니다.
- 극단적인 벤더 종속 (Extreme Vendor Lock-in): 데이터베이스 마이그레이션은 어떤 조직에서든 가장 두려운 기술 프로젝트 중 하나입니다. 모놀리식 아키텍처에서는 데이터를 넣고 꺼내는 유일한 방법이 데이터베이스 엔진 자체를 통하는 것뿐이기 때문입니다. 이는 심각한 벤더 종속을 만들어, 조직이 특정 벤더에 깊이 의존하게 합니다.
Lakebase란 무엇인가?
기존 데이터베이스의 한계를 해결하는 새로운 시스템들이 등장하기 시작했습니다. Lakebase 는 트랜잭션 데이터베이스의 장점과 데이터 레이크의 유연성 및 경제성을 결합한 새로운 오픈 아키텍처입니다. Lakebase는 근본적으로 새로운 설계 원칙에 의해 구현됩니다. 컴퓨팅과 스토리지를 분리하고, 데이터베이스의 데이터를 오픈 포맷으로 저렴한 클라우드 스토리지(“레이크”)에 직접 저장하면서, 트랜잭션 컴퓨팅 레이어는 그 위에서 독립적으로 실행될 수 있도록 합니다. 이 분리야말로 핵심적인 돌파구입니다. 전통적인 데이터베이스는 CPU와 스토리지를 하나의 모놀리식 시스템으로 묶어, 단일 대형 머신 단위로 프로비저닝하고 관리하며 비용을 지불해야 했습니다. Lakebase는 이 두 레이어를 분리합니다. 데이터는 레이크에 공개적으로 저장되고, 데이터베이스 엔진은 즉시 확장 가능한 완전 관리형 서버리스(serverless) 컴퓨팅 레이어(예: Postgres)가 됩니다. 이 아키텍처는 수십 년 동안 데이터베이스를 규정해 온 비용, 복잡성, 종속을 대부분 제거하며, 개발자들이 많은 인스턴스를 구동하고 자유롭게 실험하며 사용한 만큼만 비용을 지불하고자 하는 현대 AI 및 에이전트 기반 워크로드에 특히 강력한 힘을 발휘합니다. Lakebase는 다음과 같은 핵심 특징을 갖습니다. 스토리지와 컴퓨팅의 분리 (Storage is separated from compute): 데이터는 클라우드 오브젝트 스토리지(“레이크”)에 저렴하게 저장되고, 컴퓨팅은 독립적으로 탄력적으로 실행됩니다. 이를 통해 대규모 확장, 높은 동시성, 그리고 1초도 안 되어 제로(zero)까지 축소(레거시 데이터베이스 시스템에서는 불가능한 일)하는 능력이 가능해지며, 고비용의 데이터베이스 머신을 유휴 상태로 계속 가동할 필요가 없어집니다. 무제한적이고 저렴하며 내구성 높은 스토리지 (Unlimited, low-cost, durable storage): 데이터가 레이크에 저장됨으로써 스토리지는 사실상 무한해지며, 고정 용량 인프라를 필요로 하는 전통적인 데이터베이스 시스템보다 비용이 극적으로 저렴해집니다. 또한 클라우드 오브젝트 스토리지(예: S3)의 내구성에 의해 보호되어, 기본적으로 99.999999999%의 내구성을 제공합니다. 이는 스토리지 이중화를 위해 레플리카를 구성하는 전통적인 데이터베이스 방식보다 훨씬 우수한 것으로, 레플리카는 대부분 비동기식으로 업데이트되기 때문에 이중 장애 상황에서 데이터 손실 가능성이 있습니다. 탄력적인 서버리스 Postgres 컴퓨팅 (Elastic, serverless Postgres compute): Lakebase는 수요에 따라 즉시 확장되고 유휴 시 축소되는 완전 관리형 서버리스 Postgres를 제공합니다. 비용은 사용량과 직접 연동되어, 급격한 부하 변동이 있는 워크로드, 개발 환경, 임시 인스턴스를 구동하는 AI 에이전트에 이상적입니다. 즉시 브랜칭, 클로닝, 복구 (Instant branching, cloning, and recovery): 개발자가 코드를 브랜치하듯 데이터베이스를 브랜치하고 클론할 수 있습니다. 페타바이트 규모의 데이터베이스도 수 초 만에 복사할 수 있어, 빠른 실험, 안전한 롤백, 운영 부담 없는 즉각적인 복구가 가능합니다. 트랜잭션과 분석 워크로드의 통합 (Unified transactional and analytical workloads): Lakebase는 Lakehouse와 원활하게 통합되어, OLTP(Online Transaction Processing)와 OLAP(Online Analytical Processing) 전반에 걸쳐 동일한 스토리지 레이어를 공유합니다. 이를 통해 데이터를 이동하거나 복제하지 않고도 트랜잭션 데이터에서 직접 실시간 분석, 머신러닝, AI 기반 최적화를 실행할 수 있습니다. 오픈 및 멀티클라우드 설계 (Open and multicloud by design): 오픈 포맷으로 저장된 데이터는 독점적 종속을 방지하고 AWS, Azure 등 다양한 클라우드 간 진정한 이식성을 가능하게 합니다. 내장된 멀티클라우드 유연성은 재해 복구(disaster recovery), 장기적인 자유, 시간이 지날수록 더 강화되는 경제적 이점을 지원합니다. 이것들이 Lakebase의 핵심 특징입니다. 엔터프라이즈급 트랜잭션 시스템은 보안, 거버넌스(governance), 감사(auditing), 고가용성(high availability) 등의 추가적인 기능을 필요로 하지만, Lakebase에서는 이러한 기능들을 단 하나의 오픈 기반 위에서 한 번만 구현하고 관리하면 됩니다. Lakebase는 데이터베이스의 다음 진화를 대표합니다. 클라우드를 위해, 개발자를 위해, AI 시대를 위해 재건된 트랜잭션 시스템입니다.데이터베이스 아키텍처의 진화
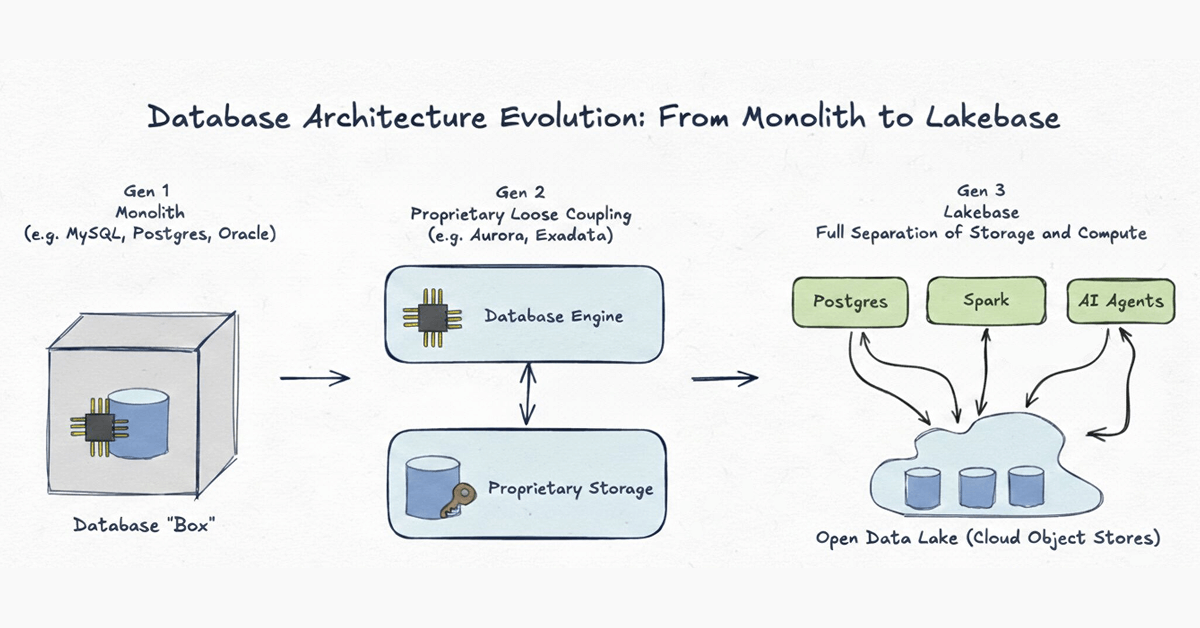
새로운 시대가 왜 필요한지 이해하기 위해, 지난 50년 동안 데이터베이스 아키텍처가 어떻게 발전해왔는지 살펴보는 것이 유용합니다. 우리는 이 진화를 세 가지 뚜렷한 세대로 구분합니다.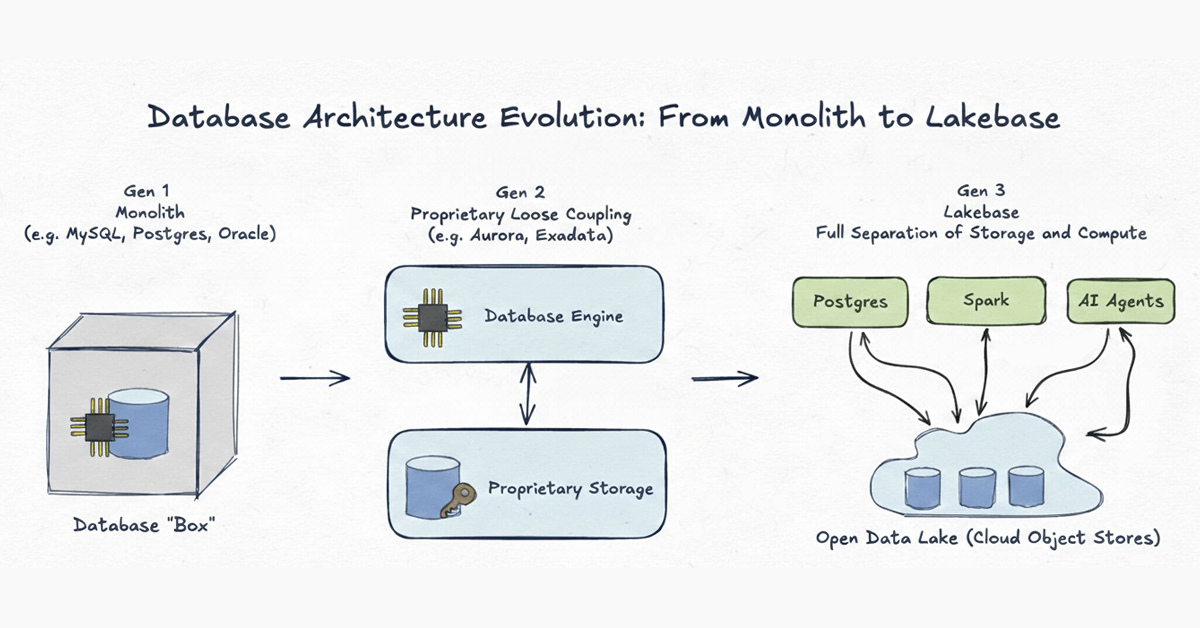
1세대 (Generation 1): 모놀리스 (Monolith)
예시: MySQL, Postgres, 클래식 Oracle 데이터베이스 시스템은 완전한 모놀리스로 시작했습니다. 클라우드 이전 시대에는 네트워크가 모든 시스템에서 가장 느린 부분이었습니다. 고성능 데이터베이스를 설계하는 유일한 방법은 컴퓨팅(CPU/RAM)과 스토리지(디스크)를 하나의 물리적 머신 내에서 긴밀하게 결합하는 것이었습니다. 이는 1980년대의 하드웨어 한계에서는 타당했지만, 데이터가 독점적인 포맷에 갇히고 확장이 더 큰 서버를 구입하는 것을 의미하는 경직된 구조를 만들었습니다.2세대 (Generation 2): 스토리지의 독점적 느슨한 결합 (Proprietary Loose Coupling of Storage)
예시: Aurora, Oracle Exadata 클라우드 인프라가 발전하면서 벤더들은 스토리지를 컴퓨팅에서 물리적으로 분리하여 스토리지를 독점적인 백엔드 계층으로 이동시켰습니다. 이 시스템들은 처리량의 한계를 밀어붙인 엔지니어링의 걸작이었습니다. 그러나 충분히 나아가지 못했습니다. 분리는 순전히 내부적인 최적화에 불과했습니다. 데이터가 단일 엔진만 접근할 수 있는 독점적인 포맷 안에 여전히 잠겨 있기 때문에, 2세대 시스템은 구조적인 막힌 골목으로 이어집니다. 아래 표는 2세대 시스템이 안고 있는 세 가지 구조적 한계를 보여줍니다.| 한계 | 설명 |
|---|---|
| 단일 엔진 병목 (Single engine chokehold) | 데이터는 기본 데이터베이스 엔진을 통해서만 접근 가능하며, 이것이 병목 지점이 됩니다. 대규모로 데이터에 접근하는 AI 에이전트나 분석 엔진에게는 매우 불리합니다. |
| 분석 마찰 (Analytical friction) | 별도의 OLAP 엔진이 대규모로 데이터베이스 파일에 직접 접근할 수 없기 때문에, 분석 쿼리 실행은 여전히 어렵고 일반적으로 데이터를 외부로 이동시키는 복잡한 ETL(Extract-Transform-Load)이 필요합니다. |
| 클라우드 종속 (Cloud lock-in) | 스토리지 레이어는 특정 클라우드 제공업체의 독점 인프라와 긴밀하게 결합되어 있습니다. 이는 멀티클라우드 상호운용성을 어렵게 만들고, 진정한 크로스 클라우드 고가용성 및 재해 복구(HADR, High Availability and Disaster Recovery)를 불가능하게 합니다. 벤더의 리전이 장애를 겪으면, 데이터는 거기에 갇히게 됩니다. |
3세대 (Generation 3): Lakebase - 레이크 위의 오픈 스토리지 (Open Storage on the Lake)
Lakebase는 분리형 아키텍처(decoupled architecture)를 그 궁극적이고 논리적인 결론까지 끌어올립니다. 2세대처럼 컴퓨팅과 스토리지를 분리하지만, 결정적인 차이가 있습니다. 스토리지 인프라와 데이터 포맷 모두가 완전히 오픈(open)입니다. 이 아키텍처를 기반으로, 앞서 언급한 세 가지 과제를 해결할 수 있습니다.- 더 나은 신뢰성과 단순한 운영을 통한 낮은 비용 (Better reliability and lower cost through simpler operations): 프로비저닝, 스케일 업/다운, 브랜칭, 스냅샷 생성, 복구와 같은 일반적인 운영 작업들을 수 초 만에 완료할 수 있습니다. 비용이 많이 드는 쿼리는 운영 트래픽에 영향을 주지 않고 별도의 탄력적인 컴퓨팅 인스턴스에서 실행할 수 있습니다.
- Git과 같은 개발자 경험 (Git-like Developer Experience): 운영 데이터베이스의 고정합성 브랜치를 기반으로 더 빠르게 실험하고 애플리케이션을 개발할 수 있습니다. 개발자와 AI 에이전트에게, 이는 데이터베이스가 코드만큼 빠르게 움직인다는 것을 의미합니다.
- 극단적인 벤더 종속 해결 (Solves Extreme Vendor Lock-in): 클라우드 오브젝트 스토리지에 오픈 포맷으로 저장된 데이터를 통해, 종속이 훨씬 줄어듭니다. 엔진에 상관없이 데이터는 여러분의 것입니다.