이 문서는 Databricks 플랫폼 섹션의 일부입니다.
왜 Databricks가 필요한가요?
데이터 엔지니어링, 데이터 웨어하우스, 데이터 레이크, ETL/ELT 패턴 등 다양한 개념을 접하고 나면 자연스럽게 한 가지 질문이 떠오릅니다. “그러면 이 모든 것을 실제로 어떤 도구로 구현하나요?” 전통적으로는 각 역할을 위해 서로 다른 도구를 따로 사용해야 했습니다.| 역할 | 전통적 도구 (별도로) |
|---|---|
| 데이터 수집 | Apache NiFi, Informatica |
| 데이터 저장 | Hadoop HDFS, Amazon S3 |
| 데이터 변환 | Apache Spark (별도 클러스터) |
| SQL 분석 | 별도의 데이터 웨어하우스 |
| ML 모델 학습 | Jupyter Notebook + 로컬 서버 |
| 모델 배포 | 별도의 서빙 인프라 |
| 데이터 거버넌스 | 또 다른 별도 도구 |
💡 현업의 현실: 위 표의 7가지 도구를 각각 도입하면, 최소 3~5명의 전문 인력이 도구별 유지보수에만 투입됩니다. 도구 A에서 도구 B로 데이터를 넘기는 “연동 파이프라인”까지 합치면, 실제 비즈니스 가치를 만드는 작업보다 인프라 관리에 더 많은 시간을 쓰게 됩니다. 한 금융사 고객은 “데이터 엔지니어의 업무 시간 중 60%가 도구 간 연동 이슈 해결이었다”고 말한 적이 있습니다.Databricks 는 이 모든 것을 하나의 통합 플랫폼 에서 제공합니다.
Databricks란 무엇인가요?
💡 Databricks 는 데이터 엔지니어링, 데이터 웨어하우징, 데이터 과학, 머신러닝을 하나의 플랫폼 에서 수행할 수 있는 클라우드 기반 데이터 인텔리전스 플랫폼(Data Intelligence Platform) 입니다.
탄생 배경 — Spark를 만든 사람들이 직접 회사를 세운 이유
Databricks는 Apache Spark 를 만든 UC Berkeley AMPLab 연구팀이 2013년에 설립한 회사입니다. 공동 창업자 7명 중 Ali Ghodsi(CEO), Matei Zaharia(Spark 원저자), Ion Stoica, Patrick Wendell 등은 지금도 회사를 이끌고 있습니다.💡 Apache Spark란? 대용량 데이터를 여러 대의 컴퓨터에 나누어 동시에 처리하는 분산 컴퓨팅 엔진 입니다. 예를 들어, 10억 건의 데이터를 분석할 때 한 대의 컴퓨터로는 수 시간이 걸리지만, Spark를 사용하면 100대의 컴퓨터가 동시에 처리하여 수 분 만에 완료할 수 있습니다.왜 논문만 쓰지 않고 회사를 만들었을까요? Spark를 오픈소스로 공개한 후, 전 세계에서 사용자가 폭발적으로 늘어났지만, 기업들이 Spark를 실제 운영 환경에서 안정적으로 사용하기 위해서는 클러스터 관리, 모니터링, 보안, 워크플로우 오케스트레이션 등 오픈소스만으로는 해결하기 어려운 문제들이 있었습니다. 현업에서는 Spark 클러스터를 직접 구축하면 Hadoop YARN 설정, 라이브러리 충돌, 메모리 튜닝 등에 수 주를 소비하는 경우가 흔했습니다. Databricks 팀은 “Spark를 가장 잘 아는 사람들이, Spark를 가장 쉽게 쓸 수 있는 플랫폼을 만들자”는 목표로 회사를 설립했습니다. Databricks 팀은 Spark뿐만 아니라 Delta Lake(데이터 저장), MLflow(ML 관리), Unity Catalog(데이터 거버넌스) 등 핵심 오픈소스 프로젝트를 주도하며, 이를 하나의 통합 플랫폼으로 제공하고 있습니다. 2024년 기준 Databricks의 기업 가치는 약 620억 달러(약 80조 원)로, 비상장 AI/데이터 기업 중 세계 최대 규모입니다.
Databricks의 성장 — 숫자로 보는 플랫폼
| 항목 | 수치 (2024~2025 기준) |
|---|---|
| 고객 수 | 전 세계 10,000+ 기업 |
| ARR (연간 반복 매출) | $2.4B+ (약 3조 원 이상) |
| 일일 데이터 처리량 | 고객 전체 합산 엑사바이트(EB) 이상 |
| 직원 수 | 7,000명 이상 |
| 주요 고객 | Shell, HSBC, T-Mobile, Rivian, Block 등 |
핵심 가치: “데이터 인텔리전스 플랫폼”
Databricks는 스스로를 **“Data Intelligence Platform”**이라고 정의합니다. 이는 단순히 데이터를 저장하고 처리하는 것을 넘어, 데이터에서 지능(Intelligence) 을 추출하는 전체 과정을 지원한다는 의미입니다.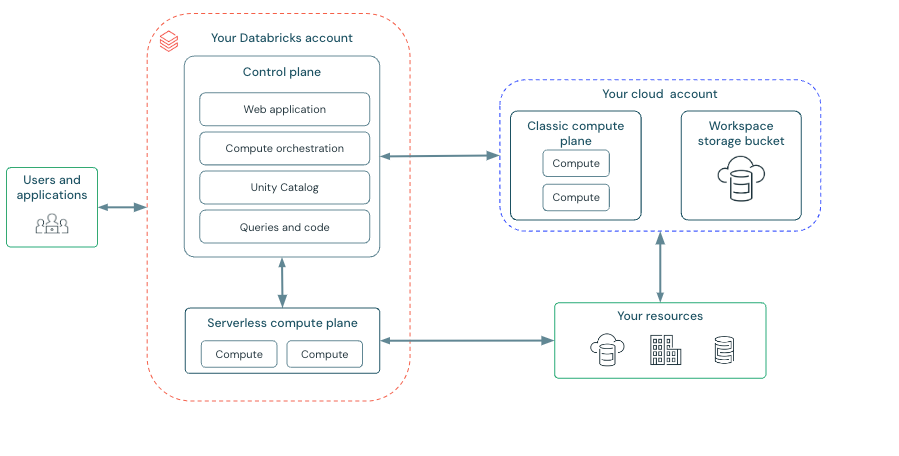 출처: Databricks Docs
출처: Databricks Docs
Databricks의 주요 구성 요소
Databricks 플랫폼은 여러 핵심 구성 요소로 이루어져 있습니다. 각 구성 요소가 어떤 역할을 하는지 살펴보겠습니다.1. 레이크하우스 (Lakehouse) — 데이터 저장
| 구성 요소 | 역할 |
|---|---|
| Delta Lake | 데이터 레이크 위에 ACID 트랜잭션, 스키마 관리, 타임 트래블 등을 제공하는 오픈소스 스토리지 레이어입니다 |
| Unity Catalog | 모든 데이터 자산(테이블, 파일, ML 모델, 함수)을 통합 관리하는 거버넌스 솔루션입니다 |
| Delta Sharing | 조직 간에 데이터를 안전하게 공유할 수 있는 오픈 프로토콜입니다 |
2. 데이터 엔지니어링 (Data Engineering) — 데이터 파이프라인
| 구성 요소 | 역할 |
|---|---|
| Lakeflow Connect | 외부 데이터 소스(DB, SaaS)에서 데이터를 자동으로 수집하는 관리형 커넥터입니다 |
| Auto Loader | 클라우드 스토리지에 도착하는 새 파일을 자동으로 감지하고 수집합니다 |
| Spark Declarative Pipelines (SDP) | 선언적 방식으로 데이터 변환 파이프라인을 정의합니다 (이전 명칭: Delta Live Tables) |
| Lakeflow Jobs | 워크플로우를 스케줄링하고 오케스트레이션합니다 |
3. 데이터 분석 (Data Analytics) — SQL과 BI
| 구성 요소 | 역할 |
|---|---|
| Databricks SQL (DBSQL) | SQL을 사용하여 Delta Lake 데이터를 직접 조회하고 분석합니다 |
| SQL Warehouse | SQL 쿼리를 실행하기 위한 전용 컴퓨팅 리소스입니다 |
| AI/BI Dashboard | 데이터를 시각화하고 대시보드를 생성하는 도구입니다 |
| Genie | 자연어로 데이터에 질문하면 SQL 쿼리를 자동 생성하여 답변을 제공합니다 |
4. AI & 머신러닝 (AI & ML) — 모델 개발과 배포
| 구성 요소 | 역할 |
|---|---|
| MLflow | ML 실험을 추적하고, 모델을 등록·관리하며, GenAI 앱의 실행 흐름을 트레이싱합니다 |
| Model Serving | 학습된 모델을 실시간 추론 엔드포인트로 배포합니다 |
| Foundation Model API | 주요 LLM(GPT, Claude, Llama 등)을 API로 제공합니다 |
| Vector Search | 임베딩 기반 유사도 검색을 제공하여 RAG(검색 증강 생성)를 지원합니다 |
| Mosaic AI Agent Framework | AI 에이전트를 개발, 평가, 배포할 수 있는 프레임워크입니다 |
💡 AI/ML 영역이 왜 중요한가요? Databricks와 Snowflake의 가장 큰 차이가 여기에 있습니다. Snowflake는 SQL 분석이 강점이지만, ML 모델 학습과 배포는 최근에야 지원하기 시작했습니다. Databricks는 처음부터 Spark + ML을 통합 설계하여, 데이터 준비 → 모델 학습 → 모델 배포 → 모니터링까지 하나의 플랫폼에서 수행할 수 있습니다. 특히 LLM과 AI 에이전트 시대에 이 통합 능력이 더욱 중요해지고 있습니다.
5. 인프라 (Infrastructure) — 컴퓨팅과 관리
| 구성 요소 | 역할 |
|---|---|
| Workspace | 모든 작업이 이루어지는 웹 기반 협업 환경입니다 |
| Clusters | Spark 작업을 실행하는 컴퓨팅 리소스(가상 머신 클러스터)입니다 |
| Notebooks | 코드를 작성하고 실행하며, 결과를 바로 확인할 수 있는 대화형 문서입니다 |
| Repos (Git 연동) | Git 저장소와 연동하여 코드 버전 관리를 할 수 있습니다 |
Databricks의 핵심 오픈소스 프로젝트
Databricks의 독특한 점 중 하나는 플랫폼의 핵심 기술들이 오픈소스 라는 것입니다. 이는 특정 벤더에 종속(Vendor Lock-in)되는 것을 우려하는 고객들에게 큰 장점입니다.| 오픈소스 프로젝트 | 역할 | GitHub Stars |
|---|---|---|
| Apache Spark | 분산 데이터 처리 엔진 | 40,000+ ⭐ |
| Delta Lake | 트랜잭션 지원 스토리지 레이어 | 7,500+ ⭐ |
| MLflow | ML 라이프사이클 관리 | 19,000+ ⭐ |
| Delta Sharing | 오픈 데이터 공유 프로토콜 | 700+ ⭐ |
| Unity Catalog (OSS) | 오픈소스 데이터 카탈로그 | 2,500+ ⭐ |
💡 플랫폼 의존도(Vendor Lock-in)이란? 특정 회사의 제품이나 서비스에 의존하게 되어, 다른 제품으로 전환하기 어려운 상태를 말합니다. 오픈소스 기반이라는 것은, 이론적으로 Databricks 없이도 동일한 기술을 직접 운영할 수 있다는 의미입니다. 다만 Databricks는 이 오픈소스 위에 관리형 서비스, 성능 최적화, 보안 기능 등을 추가하여 편리하게 제공합니다.
💡 현업에서는 이렇게 합니다: “오픈소스이니까 우리가 직접 운영하면 공짜 아닌가요?”라는 질문을 자주 받습니다. 이론적으로는 맞지만, Spark 클러스터를 직접 운영하면 전담 인력 2~3명의 인건비, 클라우드 인프라 비용(VM이 Serverless보다 비용이 높은), 장애 대응 비용을 합치면 Databricks 라이선스 비용보다 오히려 더 비싸지는 경우가 많습니다. 특히 데이터 팀이 10명 미만인 조직에서는 관리형 서비스가 거의 항상 더 경제적입니다.
정리
| 핵심 개념 | 설명 |
|---|---|
| Databricks | 데이터 수집부터 AI까지 전체 라이프사이클을 지원하는 통합 데이터 인텔리전스 플랫폼입니다 |
| 레이크하우스 | Databricks의 핵심 아키텍처로, 데이터 레이크 + 웨어하우스의 장점을 결합합니다 |
| Apache Spark | Databricks의 기반이 되는 오픈소스 분산 처리 엔진입니다 |
| Delta Lake | 데이터 레이크에 트랜잭션과 스키마 관리를 추가하는 오픈소스 스토리지 레이어입니다 |
| Unity Catalog | 모든 데이터 자산을 통합 관리하는 거버넌스 솔루션입니다 |
직접 체험해보세요: Databricks가 어떤 플랫폼인지 이해했다면, 무료 체험에서 직접 사용해보세요. 14일간 모든 기능을 무료로 체험할 수 있습니다.
더 알아보기
| 주제 | 문서 |
|---|---|
| 경쟁사 비교 | Databricks vs 경쟁사 |
| 가격 모델 | DBU와 가격 이해 |