이 문서는 AI 에이전트 섹션의 일부입니다.
왜 Vector Search가 필요한가요?
전통적인 키워드 검색(SQL의LIKE 또는 CONTAINS)은 정확히 일치하는 단어 만 찾을 수 있습니다. “환불 규정”을 검색하면 “반품 정책”은 찾지 못합니다. 그러나 이 둘은 의미적으로 매우 유사합니다.
Vector Search 는 텍스트의 의미(Semantic) 를 이해하여, 키워드가 다르더라도 의미가 유사한 항목을 찾아줍니다. RAG(검색 증강 생성) 기반 AI 에이전트의 핵심 구성 요소입니다.
| 검색 유형 | 방식 | 장점 | 한계 |
|---|---|---|---|
| 키워드 검색 | 정확한 단어 매칭 | 빠르고 예측 가능 | 동의어, 의미 유사성 처리 불가 |
| Vector Search | 임베딩 벡터 유사도 | 의미적 유사성 검색 가능 | 임베딩 모델에 의존 |
| 하이브리드 검색 | 키워드 + 벡터 결합 | 두 방식의 장점 결합 | 구성이 복잡 |
핵심 개념: 임베딩 (Embedding)
💡 임베딩(Embedding) 이란 텍스트를 수백~수천 차원의 숫자 벡터(배열) 로 변환하는 것입니다. 의미가 유사한 텍스트는 벡터 공간에서 가까운 위치 에 놓이게 됩니다.
💡 코사인 유사도(Cosine Similarity)란? 두 벡터 간의 각도를 기반으로 유사도를 측정하는 방법입니다. 값은 -1에서 1 사이이며, 1에 가까울수록 유사합니다.
Databricks Vector Search 아키텍처
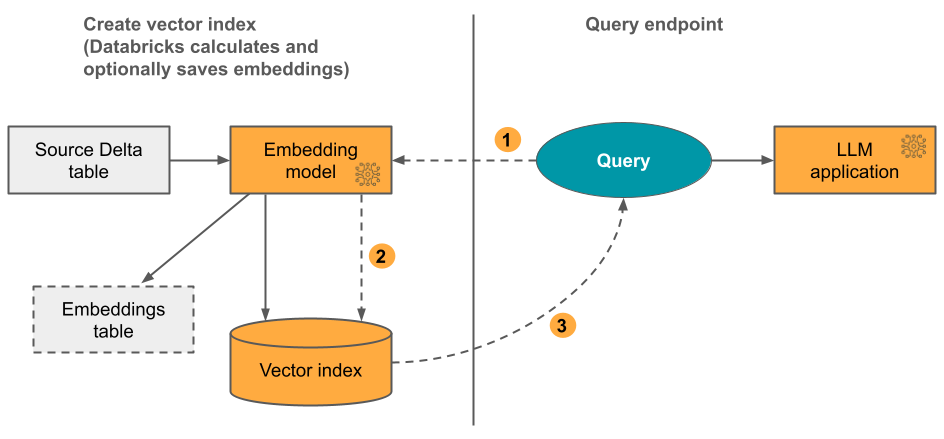 출처: Databricks 공식 문서
출처: Databricks 공식 문서
| 단계 | 구성 요소 | 설명 |
|---|---|---|
| 1. 데이터 준비 | Delta 테이블 | 원본 텍스트가 저장된 소스 테이블입니다 |
| 2. 인덱스 생성 | Vector Search Endpoint | 인덱스를 호스팅하는 컴퓨팅 리소스입니다 |
| 임베딩 모델 | 텍스트를 벡터로 자동 변환합니다 | |
| Vector Search Index | Delta Sync로 소스 테이블과 동기화되어 임베딩 벡터를 저장합니다 | |
| 3. 검색 | 질문 텍스트 | 질문이 임베딩으로 변환되어 유사도 검색이 수행됩니다 |
| 유사 문서 결과 | 인덱스에서 가장 유사한 문서가 반환됩니다 |
| 구성 요소 | 역할 |
|---|---|
| Vector Search Endpoint | 인덱스를 호스팅하고 검색 쿼리를 처리하는 컴퓨팅 리소스입니다 |
| Vector Search Index | 임베딩 벡터가 저장된 검색 인덱스입니다 |
| Delta Sync | 소스 Delta 테이블이 변경되면 인덱스를 자동으로 갱신합니다 |
Endpoint 생성
| 유형 | 설명 | 적합한 사용 |
|---|---|---|
| STANDARD | 범용. 빠른 검색 성능 | 대부분의 RAG 애플리케이션 |
| STORAGE_OPTIMIZED | 대용량에 최적화, 비용 효율적 | 수천만 건 이상의 대규모 인덱스 |
Index 유형 (3가지)
1. Delta Sync + Managed Embeddings (권장)
가장 간편한 방식입니다. 소스 Delta 테이블의 텍스트 컬럼 을 지정하면, Databricks가 임베딩 변환부터 인덱스 동기화까지 모든 과정을 자동으로 관리합니다. 사용자는 임베딩 모델을 선택하기만 하면 됩니다. 동작 원리:- 소스 Delta 테이블에서
embedding_source_column(텍스트 컬럼)을 읽습니다 - 지정된 임베딩 모델(
embedding_model_endpoint_name)로 텍스트를 벡터로 변환합니다 - 변환된 벡터를 Vector Search 인덱스에 저장합니다
TRIGGERED모드는 수동/스케줄 갱신,CONTINUOUS모드는 소스 변경 시 실시간 반영합니다
| 파라미터 | 설명 |
|---|---|
embedding_source_column | 임베딩으로 변환할 텍스트 컬럼입니다 |
embedding_model_endpoint_name | 사용할 임베딩 모델의 서빙 엔드포인트입니다 |
pipeline_type | TRIGGERED: 수동 트리거 시 동기화 / CONTINUOUS: 변경 즉시 동기화 |
columns_to_sync | 검색 결과에 포함할 추가 컬럼들입니다 (메타데이터) |
2. Delta Sync + Self-Managed Embeddings
임베딩을 직접 사전 계산 하여 Delta 테이블에 벡터 컬럼으로 저장한 경우 사용합니다. 커스텀 임베딩 모델(예: 한국어 전용 모델, 도메인 특화 모델)을 사용하거나, 임베딩 생성 과정을 세밀하게 제어하고 싶을 때 적합합니다. 동작 원리:- 사용자가 직접 임베딩을 계산하여 Delta 테이블의
embedding컬럼에 저장합니다 - Vector Search는 이미 계산된 벡터를 그대로 인덱싱합니다
- Delta 테이블이 업데이트되면 인덱스도 자동 동기화됩니다
- 한국어 전용 임베딩 모델(KoSimCSE, multilingual-e5 등)을 사용할 때
- 이미지 임베딩 등 텍스트가 아닌 벡터를 인덱싱할 때
- 임베딩 전처리(청킹, 필터링)를 세밀하게 제어할 때
3. Direct Access Index
Delta 테이블 없이 API로 직접 벡터를 삽입/삭제 하는 방식입니다.⚠️ Direct Access의 한계: Delta 테이블과 동기화되지 않으므로, 데이터 일관성 관리를 직접 해야 합니다. 대부분의 경우 Delta Sync 방식을 권장 하며, Direct Access는 특수한 실시간 요구사항이 있을 때만 사용하세요.
인덱스 유형 비교
| 비교 항목 | Delta Sync (Managed) | Delta Sync (Self-Managed) | Direct Access |
|---|---|---|---|
| 임베딩 생성 | Databricks 자동 | 사용자 직접 계산 | 사용자 직접 계산 |
| Delta 동기화 | ✅ 자동 | ✅ 자동 | ❌ 수동 (API) |
| 설정 복잡도 | 낮음 (가장 간편) | 중간 | 높음 |
| 임베딩 모델 선택 | Databricks 내장 모델 | 자유 선택 | 자유 선택 |
| 적합한 경우 | 대부분의 RAG ✅ | 커스텀/다국어 모델 | 실시간 삽입, 외부 소스 |
| 권장 여부 | ⭐ 1순위 권장 | 커스텀 모델 필요 시 | 특수 요구 시에만 |
유사도 검색
텍스트 검색
필터 결합 검색
Vector Search Reranker
🆕 Reranker(GA): 초기 검색 결과를 LLM 기반으로 재순위화 하여 정확도를 높이는 기능입니다.
| 단계 | 구성 요소 | 설명 |
|---|---|---|
| 1 | 질문 | 사용자의 검색 질문입니다 |
| 2 | Vector Search | 20개 후보 문서를 넓게 검색합니다 |
| 3 | Reranker | LLM 기반으로 재순위화하여 상위 5개를 선별합니다 |
| 4 | 최종 결과 | 가장 관련성 높은 5개 문서가 반환됩니다 |
임베딩 모델 선택
| 모델 | 차원 | 언어 | 비고 |
|---|---|---|---|
databricks-gte-large-en | 1024 | 영어 | Databricks 내장 |
databricks-bge-large-en | 1024 | 영어 | Databricks 내장 |
| multilingual-e5-large | 1024 | 다국어 | 한국어 성능 우수 (커스텀 배포 필요) |
| BGE-M3 | 1024 | 다국어 | 한국어 포함 100+ 언어 지원 |
💡 한국어 임베딩: 한국어 검색 품질을 높이려면, 다국어 임베딩 모델(multilingual-e5-large, BGE-M3)을 Model Serving에 배포하여 사용하는 것을 권장합니다.