이 문서는 Databricks 아키텍처 의 기초 편입니다.
왜 아키텍처를 이해해야 하나요?
Databricks를 사용하다 보면 “내 데이터는 어디에 저장되는 거지?”, “클러스터는 누가 관리하지?”, “보안은 어떻게 되는 거지?” 같은 질문이 생깁니다. 이 질문들에 답하려면 Databricks의 아키텍처를 이해해야 합니다. Databricks 아키텍처의 핵심은 Control Plane(제어 평면) 과 Compute Plane(컴퓨트 평면) 의 분리입니다.Control Plane vs Compute Plane
💡 Control Plane(제어 평면) 이란 Databricks가 직접 관리하는 영역으로, 사용자 인터페이스, 작업 스케줄링, 노트북 관리 등 “관리 기능”을 담당합니다. Compute Plane(컴퓨트 평면) 이란 고객의 클라우드 계정에서 실행되는 영역으로, 실제 데이터 처리와 저장이 이루어지는 곳입니다.이 분리가 중요한 이유를 실무 관점에서 설명드리겠습니다. 데이터 주권(Data Sovereignty): 고객의 데이터는 항상 고객의 클라우드 계정(S3, ADLS, GCS)에 저장 됩니다. Databricks Control Plane은 메타데이터와 실행 명령만 관리하고, 실제 데이터는 절대 Databricks 측으로 이동하지 않습니다. 이것은 GDPR, HIPAA, 금융 규제에서 요구하는 데이터 레지던시 요건을 충족하는 핵심 설계입니다. 경쟁사와의 차이: Snowflake는 데이터를 자체 관리 스토리지에 저장하므로, 데이터 이동(egress) 비용과 데이터 이식성이 제한됩니다. Databricks는 오픈 포맷(Delta Lake/Parquet)으로 고객 스토리지에 저장하므로, 언제든 다른 도구에서 직접 읽을 수 있습니다. 실전에서의 의미: Control Plane 장애가 발생해도 데이터는 안전합니다. 고객의 S3 버킷에 그대로 있으므로, 다른 Spark 클러스터나 Trino, Snowflake에서도 Delta/Parquet 파일을 직접 읽을 수 있습니다. 이런 아키텍처 덕분에 특정 벤더에 완전히 종속되는 리스크가 크게 줄어듭니다.
아키텍처 다이어그램
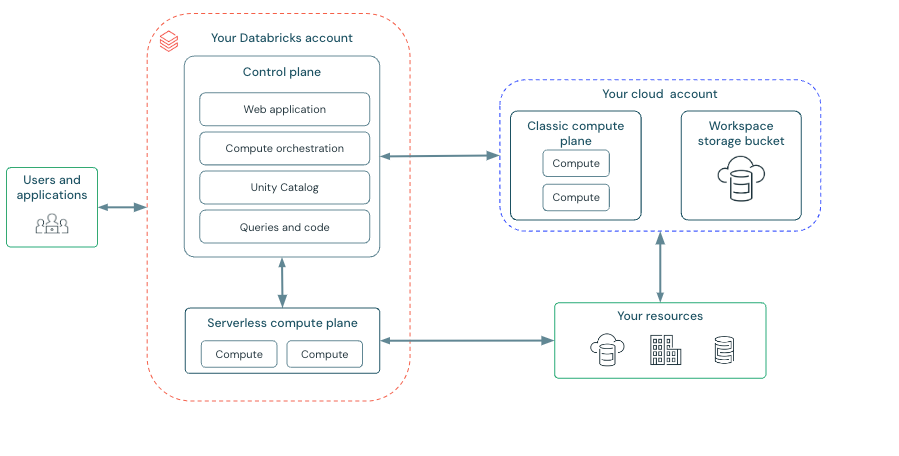
출처: Databricks 공식 문서 — Architecture overview
각 영역의 상세 구성
Control Plane (Databricks 관리 영역) — 메타데이터만 저장
중요: Control Plane에는 고객의 실제 데이터가 저장되지 않습니다. 테이블 이름, 스키마 정의, 권한 정보 같은 메타데이터와 실행 명령만 관리합니다. 고객 데이터는 항상 고객의 클라우드 스토리지(S3/ADLS/GCS)에 있습니다.
| 구성 요소 | 역할 |
|---|---|
| Web Application | 브라우저에서 접속하는 Workspace UI |
| Job Scheduler | 작업 스케줄링과 실행 명령 — 실제 실행은 Compute Plane에서 수행 |
| Notebook Service | 노트북 코드와 설정의 버전 관리 — 실행 결과 데이터는 Compute Plane에 저장 |
| Cluster Manager | 클러스터 생성/스케일링/종료 제어 — 실제 VM은 Compute Plane에 생성 |
| Unity Catalog Metastore | 테이블 이름, 스키마, 권한 등 메타데이터만 저장 — 실제 데이터 파일은 고객 스토리지 |
| IAM (Identity & Access) | 사용자 인증과 권한 관리 |
Compute Plane (고객 클라우드 영역) — 실제 데이터가 있는 곳
핵심: 고객의 실제 데이터와 컴퓨트 리소스가 위치합니다. 데이터는 고객의 클라우드 계정을 절대 벗어나지 않습니다.
| 구성 요소 | 역할 |
|---|---|
| Compute Clusters | Spark 작업을 실행하는 VM 클러스터 — 고객의 클라우드 계정에서 실행 |
| Cloud Storage | Delta Lake 테이블, 파일 등 실제 데이터 저장 (S3/ADLS/GCS) |
| Network (VPC/VNet) | 고객의 가상 네트워크 안에서 안전하게 통신 |
💡 VPC(Virtual Private Cloud)란? 클라우드 안에서 논리적으로 격리된 네트워크 공간입니다. 마치 큰 건물(클라우드) 안에 전용 사무실(VPC)을 빌리는 것과 같습니다. 외부에서 함부로 접근할 수 없고, 허용된 경로로만 통신할 수 있습니다. AWS에서는 VPC, Azure에서는 VNet(Virtual Network)이라고 부릅니다.
Serverless Compute Plane
최근 Databricks는 Serverless 옵션을 통해 Compute Plane의 관리 부담을 더욱 줄이고 있습니다.💡 서버리스(Serverless)란? 사용자가 서버(컴퓨팅 리소스)를 직접 생성하거나 관리할 필요 없이, 작업을 실행하면 시스템이 알아서 적절한 리소스를 할당해 주는 방식입니다. “서버가 없다”는 뜻이 아니라, “서버 관리를 신경 쓰지 않아도 된다”는 의미입니다.
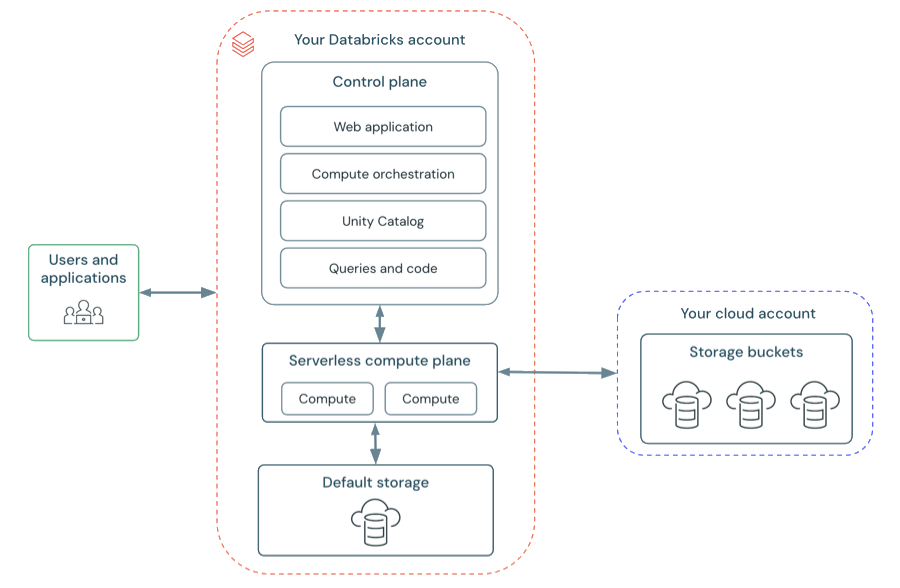 출처: Databricks Docs
출처: Databricks Docs
| 비교 항목 | 클래식 (Customer-Managed) | 서버리스 (Serverless) |
|---|---|---|
| 리소스 관리 | 고객이 직접 클러스터 설정 | Databricks가 자동 관리 |
| 시작 시간 | 수 분 (클러스터 시작) | 수 초 (즉시 시작) |
| 비용 모델 | 클러스터 실행 시간 기준 | 실제 처리량 기준 |
| 네트워크 격리 | 고객 VPC 안에서 실행 | Databricks 관리 환경에서 고객별 완전 격리 |
| 데이터 격리 | 고객 스토리지 직접 관리 | 고객 스토리지에 접근하되, 컴퓨트는 고객 간 완전 분리 |
| 적합한 경우 | 세밀한 네트워크 제어가 필요할 때 | 빠른 시작, 간편 운영 |
서버리스 격리 보장: 서버리스 Compute Plane은 고객의 워크로드를 다른 고객과 완전히 격리된 환경에서 실행합니다. 각 고객의 컴퓨트 리소스는 전용 컨테이너에서 실행되고, 네트워크도 분리되며, 작업 완료 후 환경이 즉시 폐기됩니다. 다른 고객의 데이터나 네트워크에 접근할 수 없으며, 이는 클래식 Compute Plane에서 고객이 자체 VPC로 격리하는 것과 동등한 수준의 보안입니다.
🆕 최신 동향: Databricks는 SQL Warehouse, Notebooks, Jobs, SDP, Apps 등 대부분의 워크로드에서 Serverless를 지원하며, 점차 기본(default) 모드로 전환하고 있습니다.
클라우드별 아키텍처
세 클라우드에서의 기본 구조는 동일하지만, 사용되는 클라우드 서비스 이름이 다릅니다.| 구성 요소 | AWS | Azure | GCP |
|---|---|---|---|
| 오브젝트 스토리지 | S3 | ADLS Gen2 | GCS |
| 네트워크 | VPC | VNet | VPC |
| 컴퓨트 VM | EC2 | Azure VM | Compute Engine |
| IAM | AWS IAM | Azure AD (Entra ID) | Cloud IAM |
| 네트워크 격리 | PrivateLink | Private Endpoint | Private Service Connect |
Workspace의 개념
💡 Workspace(워크스페이스) 란 Databricks에서 작업을 수행하는 독립적인 작업 환경 입니다. 하나의 조직에서 여러 개의 Workspace를 만들 수 있으며, 각 Workspace는 고유한 URL을 가집니다.Workspace는 다음과 같은 구성 요소를 포함합니다.
| 구성 요소 | 설명 |
|---|---|
| Notebooks | 코드 작성 및 실행 |
| Repos | Git 저장소 연동 |
| Clusters | 컴퓨팅 리소스 |
| Jobs | 스케줄된 작업 |
| SQL Editor | SQL 쿼리 편집기 |
| Dashboards | 시각화 대시보드 |
Workspace 구성 모범 사례
| 전략 | 설명 | 적합한 경우 |
|---|---|---|
| 환경별 분리 | 개발(Dev), 스테이징(Staging), 프로덕션(Prod) 별도 Workspace | 대부분의 기업에 권장됩니다 |
| 팀별 분리 | 데이터 엔지니어링 팀, 분석 팀, ML 팀 별도 Workspace | 팀 간 격리가 필요할 때 |
| 단일 Workspace | 모든 팀이 하나의 Workspace 사용 | 소규모 조직 |
💡 Unity Catalog 는 여러 Workspace에 걸쳐 공유될 수 있습니다. 따라서 Workspace를 분리하더라도 데이터에 대한 통합 거버넌스를 유지할 수 있습니다.
다음 단계
| 주제 | 문서 |
|---|---|
| 아키텍처 심화 | Classic vs Serverless 비교 |
| 내부 구성 요소 | Control Plane 심화와 데이터 흐름 |
| 네트워크와 DR | 네트워크 트래픽, 고가용성, 재해 복구 |