이 문서는 레이크하우스 아키텍처 섹션의 일부입니다.
Medallion 아키텍처란?
💡 Medallion(메달리온) 아키텍처 는 데이터를 품질과 가공 수준에 따라 Bronze(원본), Silver(정제), Gold(집계) 세 계층으로 나누어 관리하는 데이터 설계 패턴입니다.동메달(Bronze)부터 금메달(Gold)로 갈수록 데이터의 품질과 비즈니스 가치가 높아집니다.
출처: Databricks 공식 문서 — Medallion Architecture
왜 Medallion 아키텍처가 필요한가요?
단일 테이블로 원본 수집과 정제, 집계를 한 번에 처리하면 간단해 보이지만, 프로덕션 환경에서는 반드시 문제가 발생합니다. Medallion 아키텍처는 이러한 현실적 문제들을 해결하기 위해 설계된 패턴입니다.1. 장애 격리와 역추적 (Fault Isolation & Traceability)
데이터 파이프라인에서 문제가 발생하면, 어느 단계에서 무엇이 잘못되었는지 를 빠르게 파악해야 합니다. 단일 테이블 구조에서는 원본과 변환 결과가 뒤섞여 있어 원인 추적이 거의 불가능합니다.| 상황 | 단일 테이블 | Medallion (Bronze → Silver → Gold) |
|---|---|---|
| Gold 테이블의 매출 수치가 이상함 | 원본이 없어서 소스 DB에 재확인 요청 → 이미 로그 만료 | Bronze(원본)와 Silver(정제)를 비교하여 어느 단계에서 이상이 발생했는지 즉시 확인 |
| ETL 변환 로직에 버그 발견 | 데이터를 복구할 방법 없음 → 소스 시스템에서 재추출 (가능하다면) | Bronze에서 다시 Silver를 재생성하면 끝. Gold는 Silver에서 자동 갱신 |
| 소스 시스템이 잘못된 데이터를 보냄 | 오염된 데이터가 이미 최종 테이블에 반영됨 | Bronze에 원본이 있으므로 시점 비교가 가능. Silver의 Expectations가 품질 위반 데이터를 자동 격리 |
💡 핵심: 각 계층이 독립적이므로, 문제가 발생한 계층만 재처리하면 됩니다. Silver에 버그가 있으면 Silver만 다시 돌리면 Gold가 자동으로 정상화됩니다. Bronze는 건드릴 필요가 없습니다.
2. 테이블 재생성 (Reprocessing & Rebuild)
프로덕션 데이터 파이프라인에서 “처음부터 다시 만들어야 하는 상황” 은 생각보다 자주 발생합니다.| 재생성이 필요한 경우 | 설명 |
|---|---|
| 비즈니스 로직 변경 | ”활성 고객” 기준이 30일 → 60일로 변경 |
| 데이터 품질 규칙 추가 | 새로운 유효성 검증 규칙을 소급 적용 |
| 스키마 리팩토링 | 컬럼 이름 변경, 데이터 타입 수정 |
| 규제 감사 요청 | ”지난 1년간 원본 데이터를 그대로 제출해 주세요” |
| ML 피처 재계산 | 피처 엔지니어링 로직 변경 후 과거 데이터에 소급 적용 |
3. 컴퓨트 비용 최적화 (Compute Cost Reduction)
클라우드에서 스토리지는 싸고, 컴퓨트는 비쌉니다. 데이터를 미리 가공해두면 조회할 때마다 복잡한 변환을 반복하지 않아도 됩니다.| 비용 항목 | Medallion 없이 (매번 변환) | Medallion 사용 (사전 가공) |
|---|---|---|
| 스토리지 | 100GB × 1벌 = $2.3/월 | 100GB × 3벌 = $6.9/월 |
| 대시보드 쿼리 (일 100회) | 매번 원본 스캔+정제+집계 = $50/일 | Gold에서 사전 집계된 결과 읽기 = $2/일 |
| 월간 총 비용 | $1,502/월 | $67/월(95% 절감) |
💡 스토리지 추가 비용(1,435/월 절감합니다. 대시보드 사용자가 늘어날수록 이 차이는 더 벌어집니다. Gold 테이블은 이미 집계가 완료되어 있으므로, 100명이 동시에 조회해도 비용이 거의 동일합니다.
4. 관심사의 분리 (Separation of Concerns)
각 계층이 명확한 책임 을 가지므로, 팀 간 역할 분리가 자연스럽게 이루어집니다.| 계층 | 책임 | 담당 | 변경 빈도 |
|---|---|---|---|
| Bronze | 원본 수집, 보존 | 데이터 엔지니어 | 거의 안 바뀜 (소스가 바뀔 때만) |
| Silver | 정제, 품질 검증, 표준화 | 데이터 엔지니어 | 품질 규칙 추가/변경 시 |
| Gold | 비즈니스 집계, KPI | 분석가, ML 엔지니어 | 비즈니스 요구 변경 시 자주 |
5. 다목적 재사용 (Multi-Purpose Reuse)
하나의 Silver 테이블에서 목적이 다른 여러 Gold 테이블 을 생성할 수 있습니다.| 소스 | Gold 테이블 | 소비자 |
|---|---|---|
| silver_orders (정제된 주문 데이터) | gold_daily_revenue | 경영진 대시보드 |
| gold_customer_lifetime_value | 마케팅 CRM | |
| gold_product_performance | 상품팀 분석 | |
| ml_features_purchase_history | ML 추천 모델 | |
| gold_regional_sales | 영업팀 리포트 |
6. 감사 및 규정 준수 (Audit & Compliance)
금융, 의료, 공공 분야에서는 “원본 데이터를 변경 없이 보관하라” 는 규제 요건이 있습니다.| 규제 요건 | Medallion의 대응 |
|---|---|
| 데이터 원본 보존(GDPR, HIPAA) | Bronze 계층이 원본을 변경 없이 보존합니다 |
| 데이터 변환 이력(SOX, SOC 2) | 각 계층 간 변환 로직이 코드로 정의되어 있어 추적 가능합니다 |
| 데이터 삭제 요청(GDPR Right to Erasure) | Bronze에서 해당 레코드를 삭제하면, Silver/Gold에 자동 전파됩니다 |
| 감사 시 데이터 원본 제출 | Bronze의 특정 시점 데이터를 Time Travel로 즉시 제출할 수 있습니다 |
각 계층의 역할
🥉 Bronze Layer (원본 데이터 계층)
| 항목 | 설명 |
|---|---|
| 목적 | 소스 데이터를 있는 그대로 보존합니다 |
| 데이터 상태 | 원본 그대로 (오류, 중복, 불완전한 데이터 포함 가능) |
| 저장 방식 | 소스의 스키마를 최대한 유지하되, 메타데이터(수집 시간, 소스 파일명 등)를 추가합니다 |
| 주요 도구 | Auto Loader, Lakeflow Connect |
| 핵심 원칙 | ”아무것도 변경하지 않는다. 원본을 그대로 보존한다” |
💡 왜 원본을 보존해야 하나요? 나중에 변환 로직에 오류가 발견되더라도, 원본이 있으면 처음부터 다시 정제할 수 있습니다. 원본 없이 변환된 데이터만 있으면, 소스 시스템에 다시 요청해야 하는데 이미 삭제되었거나 변경되었을 수 있습니다.
🥈 Silver Layer (정제된 데이터 계층)
| 항목 | 설명 |
|---|---|
| 목적 | Bronze 데이터를 정제하고 표준화 하여 분석 가능한 형태로 만듭니다 |
| 데이터 상태 | 중복 제거, 타입 변환, 유효성 검증이 완료된 깨끗한 데이터입니다 |
| 저장 방식 | 정규화된 스키마, 적절한 데이터 타입, 일관된 명명 규칙을 적용합니다 |
| 주요 작업 | 데이터 정제, 중복 제거, 조인, 스키마 표준화 |
| 핵심 원칙 | ”기업 전체에서 공통으로 사용할 수 있는 깨끗한 데이터를 만든다” |
💡 정규화(Normalization)란? 데이터를 중복 없이 효율적으로 저장하기 위해 테이블을 분리하고 관계를 정의하는 과정입니다. 예를 들어, 주문 테이블에 고객 이름을 직접 넣는 대신, 고객 ID만 저장하고 고객 테이블을 별도로 만드는 것입니다. 이렇게 하면 고객 이름이 변경되어도 한 곳만 수정하면 됩니다.
🥇 Gold Layer (비즈니스 집계 계층)
| 항목 | 설명 |
|---|---|
| 목적 | 특정 비즈니스 요구에 맞게 집계, 요약, 결합 된 최종 데이터를 제공합니다 |
| 데이터 상태 | 비즈니스 메트릭, KPI, 리포트용 데이터입니다 |
| 저장 방식 | 비정규화(Denormalized)된 넓은 테이블, 사전 집계된 요약 테이블입니다 |
| 주요 소비자 | BI 대시보드, 경영진 리포트, ML 피처 테이블 |
| 핵심 원칙 | ”특정 비즈니스 질문에 바로 답할 수 있는 데이터를 만든다” |
💡 비정규화(Denormalization)란? 정규화의 반대 개념입니다. 분석 성능을 위해 의도적으로 데이터를 중복 저장합니다. 예를 들어, 고객 360 뷰에서는 고객 정보와 주문 집계를 하나의 넓은 테이블에 미리 합쳐 놓아, 조인 없이 빠르게 조회할 수 있습니다.
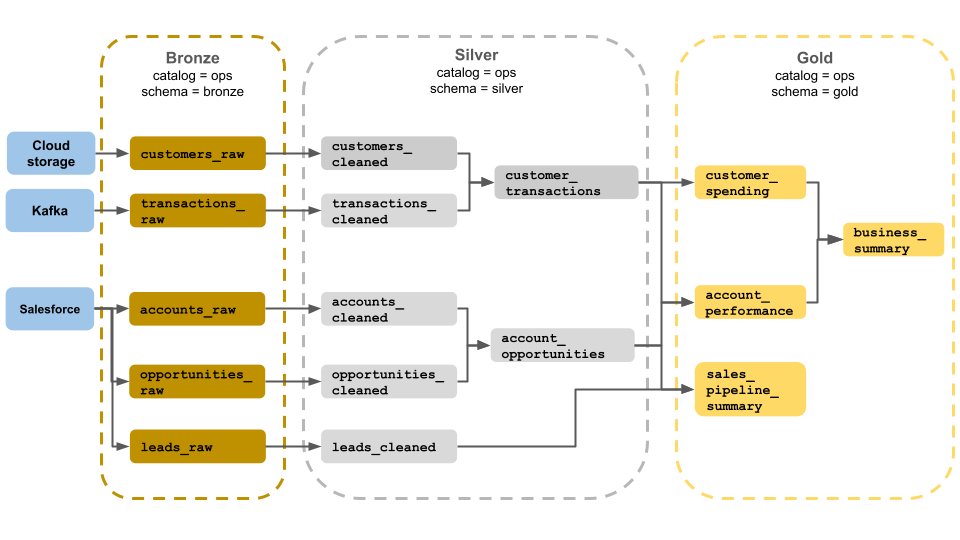
전체 흐름 다이어그램
| 레이어 | 이름 | 데이터 품질 | 용도 |
|---|---|---|---|
| 🥉 Bronze | Raw | 원본 그대로 | 데이터 수집, 감사 추적 |
| 🥈 Silver | Cleansed | 정제, 표준화 | 분석 준비, 조인 |
| 🥇 Gold | Aggregated | 비즈니스 레벨 집계 | 리포팅, ML, BI |
| 단계 | 소스 | 대상 | 설명 |
|---|---|---|---|
| 수집 | 주문 DB, 고객 DB, 웹 로그 | Bronze (bronze_orders, bronze_customers, bronze_clickstream) | 원본 데이터 보존 |
| 정제 | Bronze | Silver (silver_orders, silver_customers, silver_page_views) | 데이터 정제 및 표준화 |
| 집계 | Silver | Gold (gold_daily_revenue, gold_customer_360, gold_product_performance) | 비즈니스 메트릭 생성 |
| 소비 | Gold | 경영진 대시보드, 마케팅 분석, ML 추천 모델 | 최종 활용 |
계층 간 비교
| 비교 항목 | Bronze | Silver | Gold |
|---|---|---|---|
| 데이터 품질 | 낮음 (원본 그대로) | 높음 (정제됨) | 최고 (비즈니스 검증) |
| 스키마 | 소스와 동일 | 표준화됨 | 비즈니스 도메인 기준 |
| 갱신 빈도 | 실시간 ~ 분 단위 | 분 ~ 시간 단위 | 시간 ~ 일 단위 |
| 주요 소비자 | 데이터 엔지니어 | 데이터 분석가, DS | BI, 경영진, 앱 |
| 보존 기간 | 장기 (원본 보존) | 중기 | 단기 ~ 중기 |
| 테이블 수 | 소스 수와 비례 | Bronze와 유사 | 비즈니스 요구에 따라 |
모범 사례
네이밍 컨벤션
일관된 이름 규칙을 사용하면 테이블의 계층을 쉽게 식별할 수 있습니다.| 방식 | 예시 |
|---|---|
| 접두어 방식 | bronze_orders, silver_orders, gold_daily_revenue |
| 스키마 분리 방식 | raw.orders, cleaned.orders, analytics.daily_revenue |
| 카탈로그 분리 방식 | bronze.ecommerce.orders, silver.ecommerce.orders, gold.ecommerce.daily_revenue |
권한 관리
| 계층 | 접근 권한 |
|---|---|
| Bronze | 데이터 엔지니어만 쓰기/읽기 가능합니다 |
| Silver | 데이터 엔지니어가 쓰기, 분석가/과학자가 읽기 가능합니다 |
| Gold | 넓은 읽기 권한 (BI 사용자, 경영진 포함) |
정리
| 핵심 개념 | 설명 |
|---|---|
| Bronze | 원본 데이터를 그대로 보존하는 첫 번째 계층입니다. “있는 그대로 저장”합니다 |
| Silver | 정제, 표준화, 중복 제거가 완료된 두 번째 계층입니다. “깨끗하게 정리”합니다 |
| Gold | 비즈니스 목적에 맞게 집계된 세 번째 계층입니다. “바로 분석 가능”합니다 |
| Medallion | Bronze → Silver → Gold 3계층 구조의 데이터 설계 패턴입니다 |