이 문서는 Databricks 플랫폼 섹션의 일부입니다.
Workspace에 접속하기
Databricks Workspace는 웹 브라우저 를 통해 접속합니다. 별도의 소프트웨어 설치가 필요 없으며, Chrome, Edge, Firefox 등 최신 브라우저를 사용하시면 됩니다. 접속 URL은 클라우드 환경에 따라 다음과 같은 형태입니다.| 클라우드 | URL 형태 | 예시 |
|---|---|---|
| AWS | https://<workspace-id>.cloud.databricks.com | https://dbc-abc123.cloud.databricks.com |
| Azure | https://adb-<workspace-id>.azuredatabricks.net | https://adb-123456.azuredatabricks.net |
| GCP | https://<workspace-id>.gcp.databricks.com | https://dbc-xyz789.gcp.databricks.com |
메인 화면 구성
Workspace에 로그인하면 왼쪽 사이드바 + 메인 콘텐츠 영역 으로 구성된 화면이 나타납니다. Databricks Workspace 메인 화면 — 왼쪽 사이드바와 메인 콘텐츠 영역으로 구성됩니다
Databricks Workspace 메인 화면 — 왼쪽 사이드바와 메인 콘텐츠 영역으로 구성됩니다
| 영역 | 위치 | 설명 |
|---|---|---|
| 왼쪽 사이드바 | 화면 좌측 | 주요 메뉴(Home, Workspace, SQL, Compute, Jobs, Dashboards, Catalog, Settings) |
| 상단 바 | 화면 상단 | 글로벌 검색, 사용자 프로필, 도움말 |
| 메인 콘텐츠 | 화면 중앙 | 선택한 메뉴에 따라 변경되는 작업 영역 |
💡 글로벌 검색(Cmd+K / Ctrl+K) 은 가장 유용한 기능입니다. 노트북, 테이블, 쿼리, 클러스터 이름을 입력하면 Workspace 전체에서 즉시 검색됩니다. 메뉴를 일일이 클릭하는 것보다 훨씬 빠릅니다.
처음 로그인하면 뭘 먼저 해야 하나? — 첫날 가이드
Workspace에 처음 로그인하면 화면이 깔끔하지만 어디서부터 시작해야 할지 막막할 수 있습니다. 아래 순서를 따라 하시면 됩니다.일반 사용자의 첫날
| 순서 | 행동 | 왜? |
|---|---|---|
| 1 | Home 화면에서 New Notebook 클릭 | 가장 먼저 노트북이 잘 작동하는지 확인합니다 |
| 2 | Serverless 또는 할당된 클러스터를 연결 | 컴퓨팅 리소스가 없으면 코드를 실행할 수 없습니다 |
| 3 | SELECT 1 (SQL) 또는 print("hello") (Python) 실행 | 환경이 정상인지 확인하는 가장 빠른 방법입니다 |
| 4 | Catalog 메뉴에서 사용 가능한 카탈로그/스키마 탐색 | 어떤 데이터에 접근할 수 있는지 파악합니다 |
| 5 | Workspace > Users > 내 이름 폴더 확인 | 노트북과 파일을 저장할 개인 공간입니다 |
관리자의 첫날 — 반드시 설정해야 할 항목
| 순서 | 설정 항목 | 위치 | 안 하면 어떻게 되나? |
|---|---|---|---|
| 1 | Unity Catalog Metastore 연결 | Settings > Metastore | 데이터 거버넌스를 사용할 수 없습니다. 팀원들이 테이블을 공유할 수 없습니다 |
| 2 | 사용자/그룹 추가 | Settings > Identity and access | 팀원들이 Workspace에 접근할 수 없습니다 |
| 3 | IP 접근 제어 | Settings > Security | 외부에서 무제한 접속이 가능한 상태가 됩니다 |
| 4 | Cluster Policy 생성 | Compute > Policies | 팀원이 불필요하게 큰 클러스터를 생성하여 비용이 폭주할 수 있습니다 |
| 5 | SQL Warehouse 생성 | SQL Warehouses | SQL 분석가들이 작업할 수 없습니다 |
| 6 | Auto-termination 시간 설정 | Compute > 클러스터 설정 | 사용하지 않는 클러스터가 계속 실행되어 비용이 낭비됩니다 |
💡 현업에서는 이렇게 합니다: 가장 흔한 실수는 Cluster Policy를 설정하지 않는 것입니다. 신입 엔지니어가 실수로 i3.16xlarge 32노드 클러스터를 만들면 시간당 수백 달러가 빠져나갑니다. 반드시 max worker 수, 인스턴스 타입, auto-termination을 정책으로 제한하세요.
좌측 사이드바 메뉴 상세
🏠 Home
Workspace에 로그인했을 때 가장 먼저 보이는 화면입니다. 최근 작업한 노트북, 실행한 쿼리, 자주 사용하는 항목 등이 표시됩니다. 새로운 노트북이나 쿼리를 빠르게 만들 수 있는 버튼도 여기에 있습니다. 실무 활용: Home 화면의 Recents 탭을 적극 활용하세요. 노트북, 쿼리, 대시보드 등 최근 작업한 모든 자산이 시간순으로 나열됩니다. “어제 작업하던 노트북이 어디 있더라?” 할 때 여기서 찾는 것이 가장 빠릅니다.💻 Workspace
노트북, 파일, 폴더를 관리하는 공간입니다. 파일 탐색기처럼 폴더 구조를 사용하여 노트북과 파일을 정리할 수 있습니다.| 주요 폴더 | 설명 | 실무 팁 |
|---|---|---|
| Users/ | 각 사용자의 개인 폴더입니다. 다른 사용자가 접근할 수 없습니다 | 개인 실험, 테스트 노트북은 여기에 저장합니다 |
| Shared/ | 모든 사용자가 접근할 수 있는 공유 폴더입니다 | 팀 공용 유틸리티 노트북, 공유 쿼리를 여기에 둡니다 |
| Repos/ | Git 저장소와 연동된 프로젝트 폴더입니다 | 프로덕션 코드는 반드시 Repos를 통해 Git으로 관리합니다 |
💡 현업에서는 이렇게 합니다: 프로덕션 파이프라인 코드를 Workspace의 개인 폴더에 저장하는 것은 위험합니다. 해당 직원이 퇴사하면 코드에 접근할 수 없게 됩니다. 반드시 Repos(Git 연동) 을 통해 코드를 버전 관리하세요.
📊 SQL Editor
SQL 쿼리를 작성하고 실행하는 전용 에디터입니다. 자동 완성, 구문 하이라이팅, 실행 결과 시각화 기능을 제공합니다. SQL Editor — 왼쪽 스키마 브라우저, 중앙 쿼리 편집 영역, 하단 결과 패널로 구성됩니다
실무 활용: SQL Editor는 단순한 쿼리 도구가 아닙니다. 쿼리를 저장하고 이름을 붙여 관리할 수 있고, 팀원과 공유할 수 있습니다. 쿼리 결과를 바로 차트로 변환하거나 대시보드에 추가할 수도 있습니다. 매일 아침 데이터 상태를 확인하는 “헬스 체크 쿼리” 모음을 만들어두면 운영이 편해집니다.
SQL Editor — 왼쪽 스키마 브라우저, 중앙 쿼리 편집 영역, 하단 결과 패널로 구성됩니다
실무 활용: SQL Editor는 단순한 쿼리 도구가 아닙니다. 쿼리를 저장하고 이름을 붙여 관리할 수 있고, 팀원과 공유할 수 있습니다. 쿼리 결과를 바로 차트로 변환하거나 대시보드에 추가할 수도 있습니다. 매일 아침 데이터 상태를 확인하는 “헬스 체크 쿼리” 모음을 만들어두면 운영이 편해집니다.
🖥️ Compute
클러스터와 SQL Warehouse를 생성하고 관리하는 화면입니다.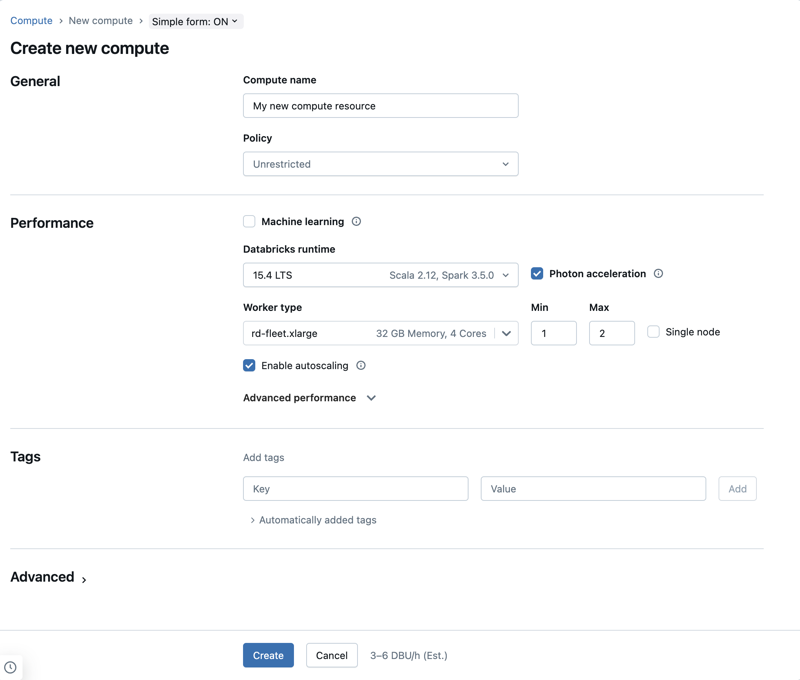 Compute 생성 화면 — 클러스터 이름, 크기, 런타임 버전 등을 설정합니다
Compute 생성 화면 — 클러스터 이름, 크기, 런타임 버전 등을 설정합니다
| 리소스 유형 | 설명 | 언제 쓰나? |
|---|---|---|
| All-Purpose Clusters | 노트북에서 대화형으로 코드를 실행하기 위한 클러스터입니다 | 개발, 탐색, 디버깅 시 |
| Job Clusters | 스케줄된 작업 실행 시 자동으로 생성되는 클러스터입니다 | 프로덕션 ETL 파이프라인 |
| SQL Warehouses | SQL 쿼리 실행에 특화된 컴퓨팅 리소스입니다 | SQL 분석, 대시보드, BI 연동 |
| Serverless | Databricks가 관리하는 인프라에서 즉시 실행됩니다 | 빠른 시작이 필요할 때 (수 초 이내) |
⚠️ 비용 주의: All-Purpose Cluster는 DBU 단가가 Job Cluster의 2배 이상입니다. 개발이 끝나면 반드시 Jobs로 전환하세요. 또한 Auto-termination(자동 종료)을 30분 이내로 설정하는 것을 권장합니다. 퇴근 후 클러스터가 밤새 돌아가는 것이 비용 낭비의 가장 흔한 원인입니다.
⏰ Jobs (Workflows)
데이터 파이프라인과 작업을 스케줄링하고 모니터링하는 화면입니다. 작업의 실행 이력, 성공/실패 현황, 실행 시간 등을 확인할 수 있습니다.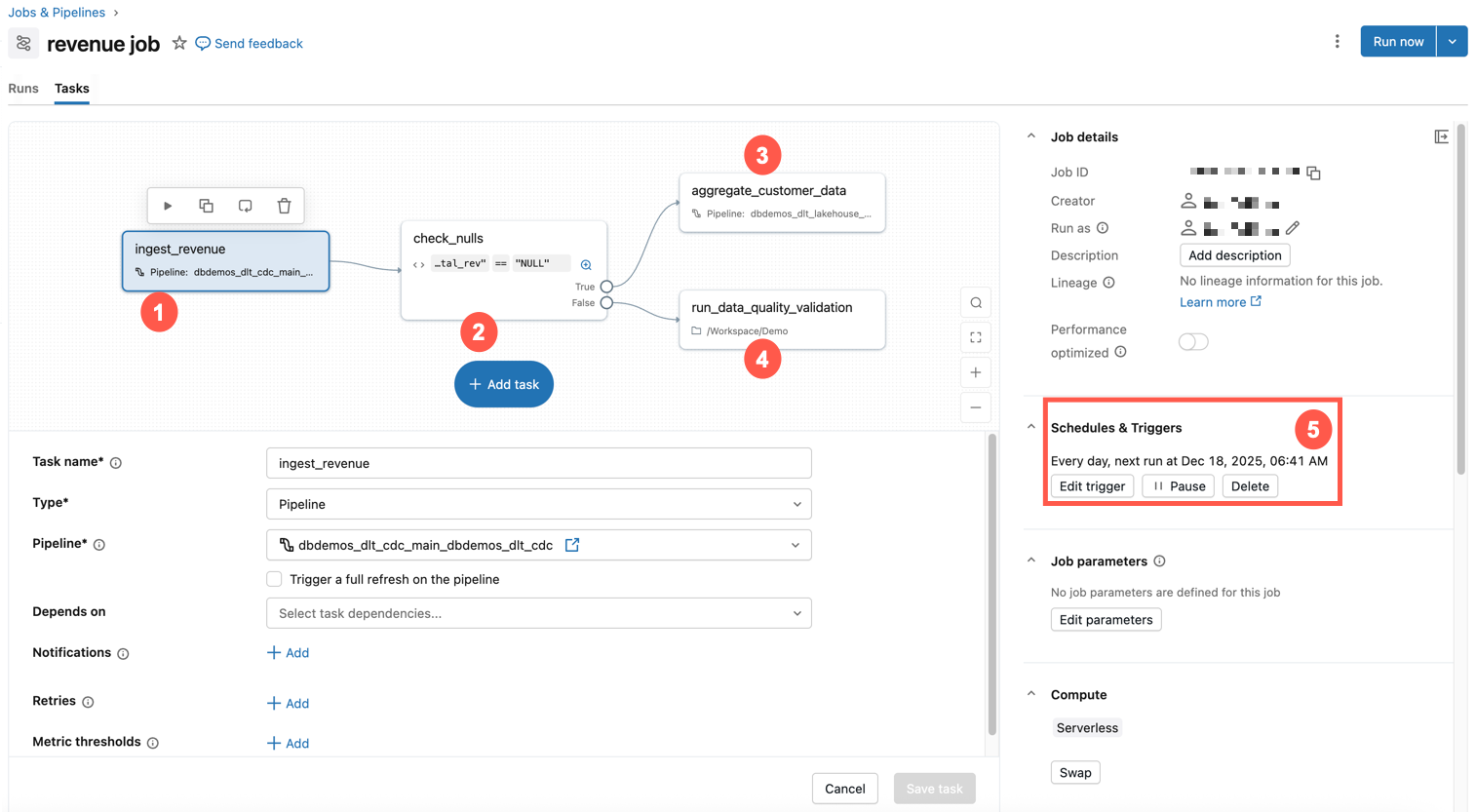 Jobs 화면 — 4개 Task로 구성된 Job과 일일 스케줄 트리거 예시
실무 활용: Jobs 화면에서 가장 중요한 것은 실패 알림 설정 입니다. 작업이 실패하면 Slack/이메일로 알림을 받도록 설정하세요. 또한 Duration 추이 를 주기적으로 확인하여, 작업 시간이 점점 늘어나는 파이프라인을 조기에 발견하는 것이 중요합니다.
Jobs 화면 — 4개 Task로 구성된 Job과 일일 스케줄 트리거 예시
실무 활용: Jobs 화면에서 가장 중요한 것은 실패 알림 설정 입니다. 작업이 실패하면 Slack/이메일로 알림을 받도록 설정하세요. 또한 Duration 추이 를 주기적으로 확인하여, 작업 시간이 점점 늘어나는 파이프라인을 조기에 발견하는 것이 중요합니다.
📈 Dashboards
AI/BI 대시보드를 생성하고 관리하는 공간입니다. SQL 쿼리 결과를 차트, 표, 텍스트 등으로 시각화할 수 있습니다.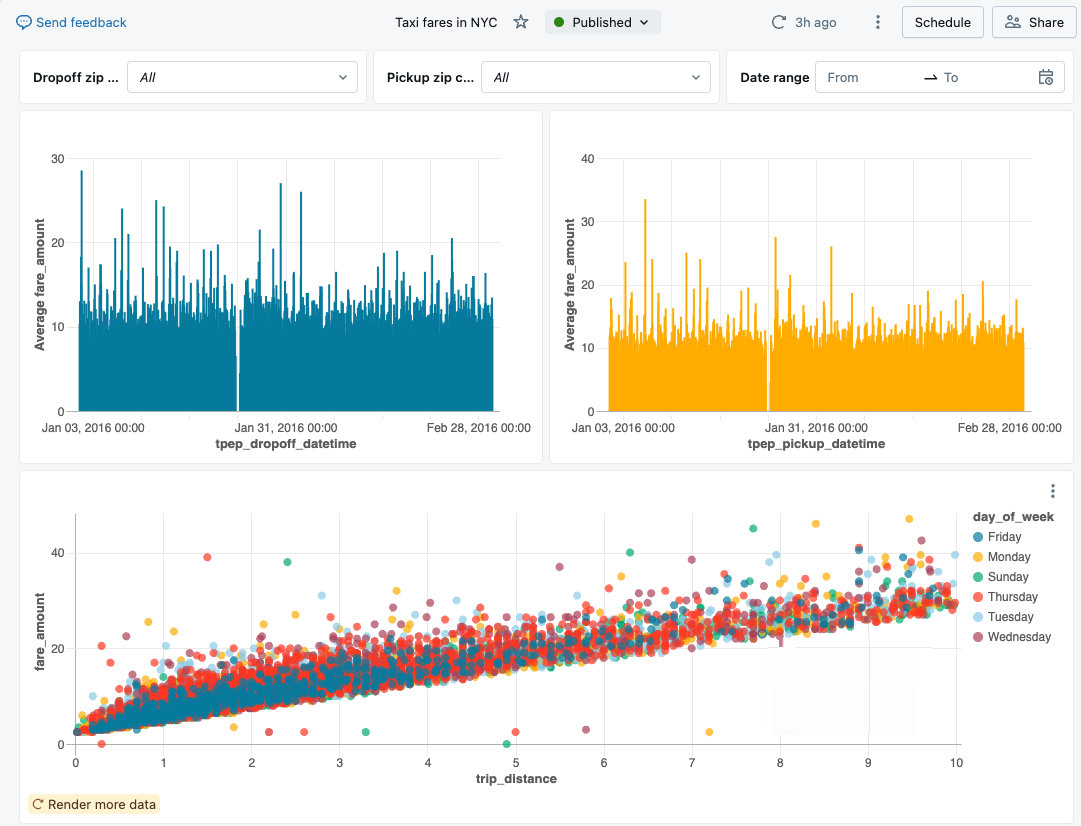 AI/BI Dashboard (Lakeview) — 차트, 표, 필터를 조합한 대시보드 예시
실무 활용: Databricks Dashboard(구 Lakeview Dashboard)는 SQL Warehouse에서 직접 쿼리를 실행하므로, 별도의 BI 도구(Tableau, Power BI) 없이도 기본적인 시각화가 가능합니다. 특히 데이터 파이프라인 모니터링 대시보드(일별 처리량, 에러율 등)를 만들 때 유용합니다.
AI/BI Dashboard (Lakeview) — 차트, 표, 필터를 조합한 대시보드 예시
실무 활용: Databricks Dashboard(구 Lakeview Dashboard)는 SQL Warehouse에서 직접 쿼리를 실행하므로, 별도의 BI 도구(Tableau, Power BI) 없이도 기본적인 시각화가 가능합니다. 특히 데이터 파이프라인 모니터링 대시보드(일별 처리량, 에러율 등)를 만들 때 유용합니다.
🛡️ Catalog
Unity Catalog를 통해 데이터 자산을 탐색하고 관리하는 화면입니다.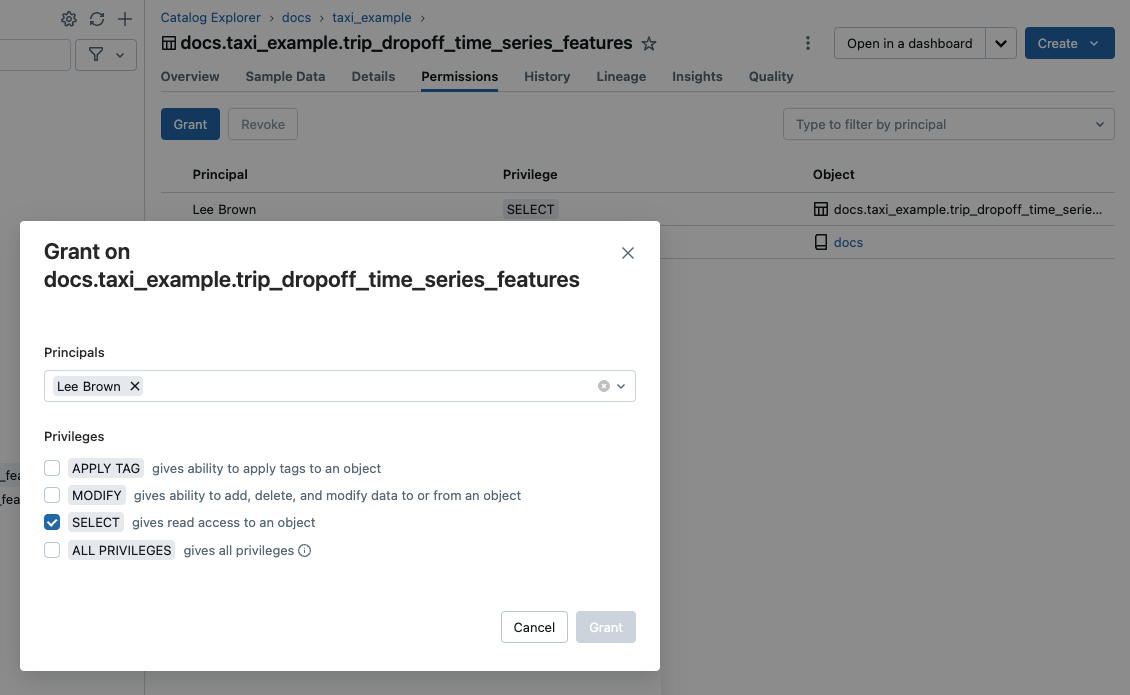 Catalog Explorer — 카탈로그/스키마/테이블을 탐색하고 권한을 관리합니다
Catalog Explorer — 카탈로그/스키마/테이블을 탐색하고 권한을 관리합니다
| 수준 | 오브젝트 | 설명 |
|---|---|---|
| Catalog | 카탈로그 | 최상위 컨테이너 |
| └ Schema | 스키마 | 카탈로그 하위의 논리적 그룹 |
| ├ Tables | 테이블 | 행/열 구조의 데이터 |
| ├ Views | 뷰 | 가상 테이블 (쿼리 정의) |
| ├ Volumes | 볼륨 | 파일 저장소 |
| ├ Functions | 함수 | 사용자 정의 함수 |
| └ Models | ML 모델 | 머신러닝 모델 |
⚙️ Settings
Workspace 설정을 관리하는 영역입니다. 관리자 권한이 필요한 설정도 여기에서 접근합니다. 주요 설정 항목:| 설정 | 역할 | 누가 사용? |
|---|---|---|
| Identity and access | 사용자, 그룹, 서비스 프린시펄 관리 | Workspace 관리자 |
| Security | IP 접근 제어, 토큰 관리 | Workspace 관리자 |
| Compute | 클러스터 정책, 기본 설정 | Workspace 관리자 |
| Developer | Personal Access Token, Git 연동 | 모든 사용자 |
| Notifications | 작업 알림 설정 (이메일, Slack) | 모든 사용자 |
자주 사용하는 주요 기능
새 노트북 만들기
 Notebook 인터페이스 — 셀 기반 코드 작성, 실행, 결과 확인을 한 화면에서 수행합니다
Notebook 인터페이스 — 셀 기반 코드 작성, 실행, 결과 확인을 한 화면에서 수행합니다
- 좌측 사이드바에서 + New 또는 Home 화면에서 New Notebook 클릭
- 노트북 이름 입력
- 기본 언어 선택 (Python, SQL, Scala, R)
- 클러스터 연결 (Serverless 또는 기존 클러스터)
- 코드 작성 및 실행 (Shift + Enter 또는 실행 버튼)
SQL 쿼리 실행
- 좌측 사이드바에서 SQL Editor 클릭
- SQL Warehouse 선택 (없으면 새로 생성)
- 쿼리 작성 후 실행 (Ctrl/Cmd + Enter)
- 결과를 테이블, 차트 등으로 확인
클러스터 생성
- Compute 메뉴 클릭
- Create Compute 또는 Create SQL Warehouse 클릭
- 클러스터 이름, 크기, 자동 종료 시간 등 설정
- Create 클릭 → 클러스터가 시작될 때까지 수 분 대기 (Serverless는 수 초)
Catalog에서 데이터 탐색
- 좌측 사이드바에서 Catalog 클릭
- 사용 가능한 카탈로그 목록 확인
- 카탈로그 → 스키마 → 테이블 순서로 탐색
- 테이블 클릭 → Columns 탭에서 스키마 확인, Sample Data 탭에서 데이터 미리보기
- Lineage 탭에서 데이터 흐름(어디서 왔고 누가 사용하는지) 확인
💡 현업 팁: 새로운 프로젝트를 시작할 때, 코드를 작성하기 전에 Catalog에서 기존 데이터를 먼저 탐색하세요. “이미 누군가 만들어 놓은 테이블”이 있는 경우가 많습니다. 데이터를 중복으로 만들면 스토리지 비용이 낭비될 뿐 아니라, “어떤 테이블이 진짜인가?”라는 혼란이 발생합니다.
Jobs 생성 및 모니터링
- 좌측 사이드바에서 Workflows(또는 Jobs) 클릭
- Create Job 클릭
- Task로 노트북, Python 스크립트, SQL 쿼리 등을 추가
- 스케줄(Cron) 설정 → 예: 매일 오전 6시
- 알림 설정 → 실패 시 이메일/Slack 알림
- 실행 이력에서 성공/실패 현황, 실행 시간 추이 확인
활용 팁, 베스트 프랙티스, 단축키, FAQ는 Workspace 활용 팁과 베스트 프랙티스 에서 이어집니다.