이 문서는 머신러닝 섹션의 일부입니다.
개념
💡 MLflow 는 머신러닝 라이프사이클 전체를 관리하는 오픈소스 플랫폼 입니다. 실험 추적, 모델 패키징, 모델 레지스트리, GenAI 트레이싱, 모델 평가까지 ML/AI 워크플로우의 모든 단계를 지원합니다.Databricks가 주도하여 개발하고 있으며, GitHub Stars 19,000+로 가장 널리 사용되는 ML 라이프사이클 관리 도구입니다. Databricks에서는 별도 설치 없이 기본 내장 되어 있어, 클러스터를 시작하면 바로
import mlflow로 사용을 시작할 수 있습니다.
MLflow는 2018년 Databricks에서 시작된 프로젝트로, 초기에는 실험 추적(Tracking)에 초점을 맞추었지만 현재는 전통 ML부터 GenAI까지 아우르는 종합 ML/AI 플랫폼 으로 발전했습니다. 특히 MLflow 3.0에서는 GenAI 워크플로우에 대한 지원이 대폭 강화되었습니다.
MLflow 3.0의 주요 변화
🆕 MLflow 3.0 은 GenAI 시대에 맞춰 대대적으로 업그레이드된 버전입니다. 기존의 전통 ML 중심 기능에 더해, LLM과 AI 에이전트를 위한 도구가 대폭 강화되었습니다.
| 변화 영역 | MLflow 2.x | MLflow 3.0 |
|---|---|---|
| 트레이싱 | 별도 설정 필요 | GenAI 트레이싱이 핵심 기능으로 승격. 자동 트레이싱 강화 |
| 평가 | 기본적인 메트릭 평가 | LLM Judge 기반 Scorer 시스템 (Correctness, Safety 등) |
| 모델 타입 | sklearn, PyTorch 등 전통 ML | ChatAgent, 에이전트 프레임워크 네이티브 지원 |
| 실험 추적 | 파라미터/메트릭 중심 | 프롬프트 버전 관리, 토큰 사용량 추적 추가 |
| 배포 | 모델 서빙 기본 | Agent 배포 원클릭, A/B 테스트 강화 |
| UI | 실험 비교 중심 | Trace 뷰어, 평가 결과 대시보드 추가 |
MLflow 3.0 핵심 신기능
- Prompt Registry: 프롬프트를 버전 관리하고, 실험 간에 프롬프트 변경 이력을 추적합니다
- Enhanced Tracing: LangChain, OpenAI, Anthropic 등의 GenAI 라이브러리에 대한 자동 트레이싱이 강화되었습니다
- Scorer Framework:
mlflow.genai.scorers로 체계적인 LLM 평가 프레임워크를 제공합니다 - ChatAgent Interface:
mlflow.pyfunc.ChatAgent로 에이전트를 표준화된 형태로 구현하고 배포합니다
MLflow의 핵심 컴포넌트
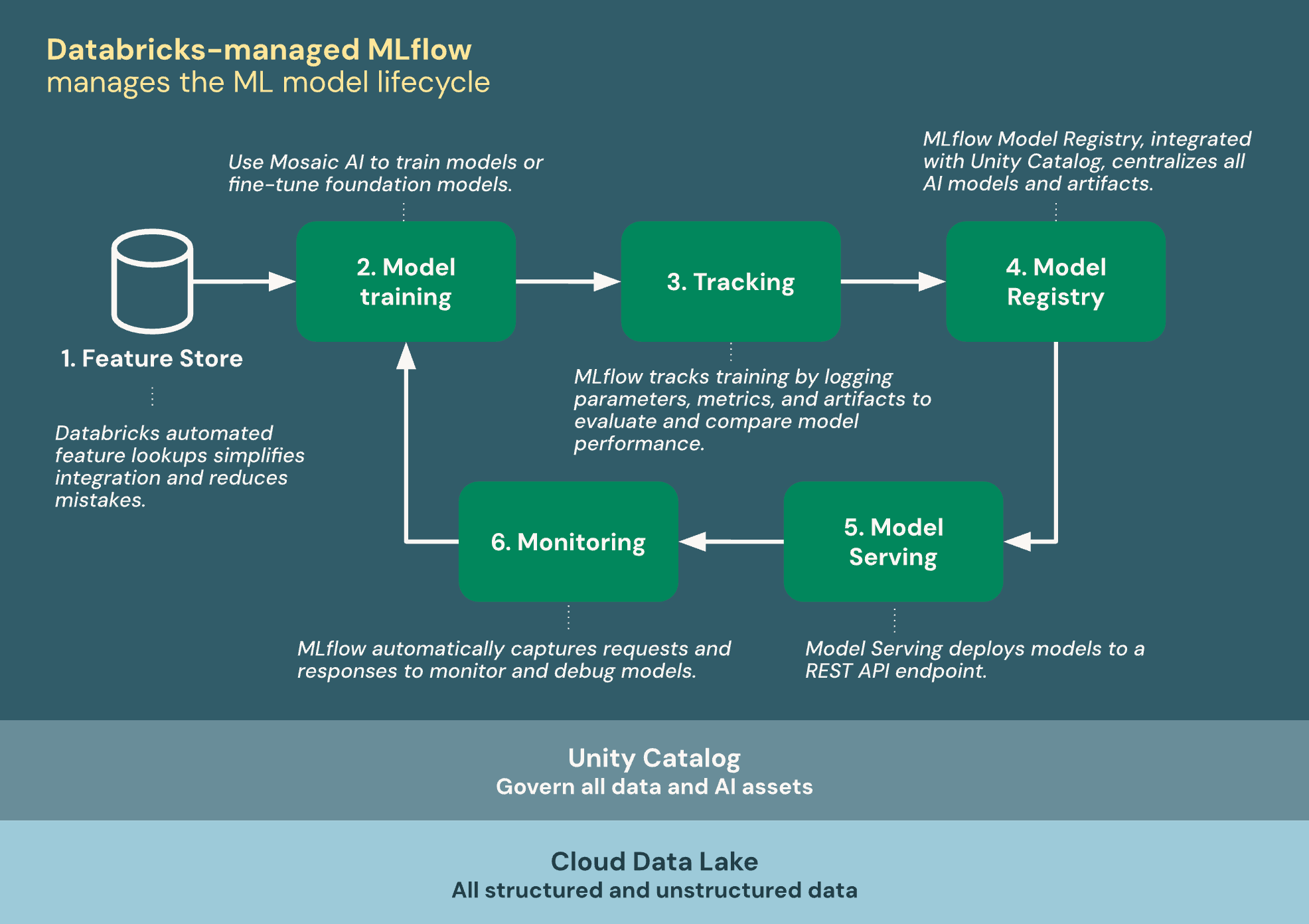 출처: Databricks 공식 문서
출처: Databricks 공식 문서
| 구성 요소 | 역할 | 흐름 |
|---|---|---|
| Tracking | 실험 추적 | 실험/학습 → Tracking |
| Models | 모델 패키징 | Tracking → Models |
| Registry | 모델 레지스트리 | Models → Registry → 배포 |
| Tracing | GenAI 트레이싱 | GenAI 실행 흐름을 추적합니다 |
| Evaluate | 모델 평가 | Tracing 데이터를 기반으로 평가합니다 |
Tracking (실험 추적)
MLflow Tracking은 ML 실험의 파라미터, 메트릭, 아티팩트 를 체계적으로 기록합니다. 동일한 모델을 다른 하이퍼파라미터로 여러 번 학습할 때, 각 실행(Run)의 결과를 비교하여 최적의 설정을 찾을 수 있습니다. Databricks UI에서는 차트와 테이블로 실험을 시각적으로 비교할 수 있어, 의사결정이 훨씬 수월해집니다.Models (모델 패키징)
MLflow Models는 다양한 ML 프레임워크(scikit-learn, PyTorch, Hugging Face 등)의 모델을 표준화된 형식 으로 패키징합니다. 이 표준화 덕분에 어떤 프레임워크로 학습하든 동일한 방식으로 모델을 저장, 로드, 배포할 수 있습니다.mlflow.pyfunc 인터페이스를 통해 커스텀 모델도 지원합니다.
Model Registry (모델 레지스트리)
Model Registry는 학습된 모델의 버전을 관리 하고, 프로덕션 승격을 제어합니다. Unity Catalog와 통합되어 모델에도 데이터 테이블과 동일한 거버넌스(권한, 리니지, 태그) 가 적용됩니다. Alias 기능으로champion(현재 프로덕션), challenger(테스트 중) 등의 레이블을 부여하여 배포 관리를 체계화합니다.
Tracing (GenAI 트레이싱)
MLflow Tracing은 GenAI 앱(RAG, 에이전트 등)의 실행 흐름을 단계별로 추적 합니다. LLM 호출, 도구(Tool) 실행, 벡터 검색 등 각 단계(Span)의 입력/출력, 지연시간, 토큰 사용량을 기록하여 디버깅과 최적화에 활용합니다. LangChain, OpenAI, Anthropic 등 주요 GenAI 라이브러리에 대한 자동 트레이싱 을 지원합니다.Evaluate (모델 평가)
MLflow Evaluate는 모델과 에이전트의 품질을 자동으로 평가 합니다. 전통 ML에서는 정확도, F1, AUC 등의 메트릭을, GenAI에서는 LLM Judge 기반의 Correctness, Safety, RetrievalGroundedness 등을 측정합니다. 내장 Scorer와 커스텀 Scorer를 조합하여 다양한 관점에서 평가할 수 있습니다.| 컴포넌트 | 역할 | 사용 시나리오 |
|---|---|---|
| Tracking | 실험의 파라미터, 메트릭, 아티팩트 를 기록합니다. 여러 실험을 비교할 수 있습니다 | 모델 학습 시 하이퍼파라미터, 정확도 등을 기록 |
| Models | 모델을 표준 형식 으로 패키징합니다. 다양한 프레임워크(sklearn, PyTorch, HuggingFace 등)를 지원합니다 | 학습된 모델을 저장하고 로드 |
| Model Registry | 모델의 버전을 관리 하고, Alias(champion, challenger)를 부여합니다. Unity Catalog와 통합됩니다 | 모델의 프로덕션 승격 관리 |
| Tracing | GenAI 앱의 실행 흐름을 추적 합니다. LLM 호출, Tool 실행, 검색 등 각 단계를 기록합니다 | RAG 파이프라인, AI 에이전트 디버깅 |
| Evaluate | 모델/에이전트의 품질을 자동 평가 합니다. 내장 Scorer와 커스텀 Scorer를 지원합니다 | 정확도, 안전성, 근거성 평가 |
전통 ML vs GenAI에서의 MLflow 역할
MLflow는 전통 ML과 GenAI 양쪽에서 모두 핵심적인 역할을 하지만, 각 영역에서 활용되는 컴포넌트와 방식에 차이가 있습니다. 아래 표는 동일한 MLflow 기능이 두 영역에서 어떻게 다르게 활용되는지 보여줍니다.| 역할 | 전통 ML (scikit-learn, XGBoost) | GenAI (LLM, RAG, Agent) |
|---|---|---|
| 추적 | 파라미터, 메트릭(accuracy, F1) 기록 | 프롬프트, 토큰 사용량, 지연시간 기록 |
| 모델 저장 | 학습된 모델 파일 (.pkl, .pt) | ChatAgent, RAG Chain 등 |
| 평가 | 테스트 데이터 기반 메트릭 | LLM Judge (Correctness, Safety) |
| 모니터링 | 데이터 드리프트 | 답변 품질, 환각율, 지연시간 |
| 핵심 도구 | Tracking, Models, Registry | Tracing, Evaluate, Models |
OSS MLflow vs Databricks 관리형 MLflow
MLflow는 오픈소스 프로젝트이므로 어디서든 직접 설치하여 사용할 수 있지만, Databricks에서 사용하면 여러 관리형 기능이 추가됩니다. 두 버전의 차이를 이해하면 Databricks 환경에서의 이점을 파악할 수 있습니다.| 비교 항목 | OSS MLflow (직접 설치) | Databricks 관리형 MLflow |
|---|---|---|
| Tracking Server | 직접 서버 설치 및 운영 필요 | 자동 제공, 관리 불필요 |
| 인증/보안 | 직접 구현 (OAuth, 방화벽 등) | Databricks 인증 자동 적용 |
| 스토리지 | S3/GCS 등 직접 설정 | Unity Catalog에 자동 저장 |
| Model Registry | 별도 DB 필요 | Unity Catalog 통합 (거버넌스 포함) |
| Tracing 저장 | 로컬 파일 시스템 | Inference Table 자동 기록 |
| UI | 기본 웹 UI | Databricks Workspace에 통합된 고급 UI |
| 서빙 연동 | 별도 배포 인프라 필요 | Model Serving 원클릭 배포 |
| 확장성 | 직접 인프라 스케일링 | Databricks 인프라 자동 확장 |
| 비용 | 무료 (인프라 비용 별도) | Databricks 사용량에 포함 |
💡 핵심: OSS MLflow로 시작한 프로젝트도 코드 변경 없이 Databricks에서 실행할 수 있습니다. import mlflow만으로 관리형 기능이 자동 적용되므로, 마이그레이션 부담이 거의 없습니다.
Databricks와의 통합 상세
Databricks에서 MLflow를 사용하면 다음과 같은 추가 이점이 있습니다. 별도의 설정 코드 없이도 이러한 기능이 자동으로 활성화됩니다.| 기능 | 설명 |
|---|---|
| 자동 설정 | Tracking Server, 인증이 자동으로 구성됩니다. mlflow.set_tracking_uri() 불필요합니다 |
| Unity Catalog 통합 | 모델이 UC에 등록되어, 테이블과 동일한 거버넌스(권한, 리니지)가 적용됩니다 |
| Autolog | 한 줄로 주요 ML 프레임워크의 자동 로깅을 활성화합니다 |
| Workspace UI | 실험, 모델, 트레이스를 웹 UI에서 시각적으로 관리합니다 |
| Model Serving 연동 | 등록된 모델을 클릭 한 번으로 서빙 엔드포인트에 배포합니다 |
| Serverless 실행 | MLflow 작업이 서버리스 컴퓨트에서 실행됩니다 |
빠른 시작 예제: 전통 ML
빠른 시작 예제: GenAI 트레이싱
MLflow의 핵심 개념
MLflow를 효과적으로 사용하려면 아래의 핵심 개념을 이해해야 합니다. 이 개념들은 전통 ML과 GenAI 모두에서 공통으로 적용됩니다.| 개념 | 설명 |
|---|---|
| Experiment | 관련 있는 여러 Run을 묶는 그룹입니다. 프로젝트나 모델 단위로 생성합니다 |
| Run | 하나의 모델 학습/실행을 의미합니다. 파라미터, 메트릭, 아티팩트가 기록됩니다 |
| Parameter | 모델의 입력 설정값입니다 (학습률, 트리 수 등) |
| Metric | 모델의 성능 지표입니다 (정확도, F1 score, 손실 등) |
| Artifact | 모델 파일, 그래프, 데이터 등 실행 중 생성된 파일입니다 |
| Registered Model | Unity Catalog에 등록된 모델. 버전과 Alias로 관리합니다 |
| Alias | 모델 버전에 부여하는 레이블입니다 (예: champion, challenger). 배포 시 Alias로 참조합니다 |
| Trace | GenAI 앱의 한 번의 실행을 기록한 것입니다. 여러 Span으로 구성됩니다 |
| Span | Trace 내의 개별 단계입니다 (LLM 호출, 검색, Tool 실행 등). 입력/출력, 지연시간이 기록됩니다 |
지원 ML 프레임워크
MLflow는 다양한 ML/DL 프레임워크를 네이티브로 지원합니다. 각 프레임워크에 대해 모델 저장/로드, 자동 로깅 등의 기능이 내장되어 있어 별도의 커스텀 코드 없이 바로 사용할 수 있습니다.| 카테고리 | 프레임워크 | MLflow 모듈 |
|---|---|---|
| 전통 ML | scikit-learn | mlflow.sklearn |
| XGBoost | mlflow.xgboost | |
| LightGBM | mlflow.lightgbm | |
| Spark ML | mlflow.spark | |
| 딥러닝 | PyTorch | mlflow.pytorch |
| TensorFlow/Keras | mlflow.tensorflow | |
| LLM/GenAI | OpenAI | mlflow.openai |
| LangChain | mlflow.langchain | |
| Anthropic | mlflow.anthropic | |
| Hugging Face | mlflow.transformers | |
| LlamaIndex | mlflow.llama_index | |
| 범용 | 커스텀 모델 | mlflow.pyfunc |
🆕 MLflow Traces in Unity Catalog (Preview): MLflow 트레이스를 Unity Catalog에 저장하여 SQL로 조회할 수 있는 기능이 출시되었습니다. system.mlflow.traces 테이블을 통해 무제한 용량으로 트레이스를 보존하고 분석할 수 있으며, 기존 SQL 기반 대시보드와 알림 도구에 바로 연결할 수 있습니다.
현업 사례: ML 모델을 Git으로만 관리하다가 재현이 안 되는 상황
🔥 ML을 처음 도입하는 거의 모든 팀이 겪는 문제입니다.“모델 코드를 Git에 커밋하면 되지, 별도 도구가 왜 필요하지?”라고 생각하는 팀이 많습니다. 하지만 6개월 후에 반드시 이런 상황이 벌어집니다.
전형적인 재현 실패 시나리오
Git으로는 관리할 수 없는 것들
| 항목 | Git | MLflow |
|---|---|---|
| 소스 코드 | ✅ 잘 관리됨 | ✅ Artifact로 저장 |
| 하이퍼파라미터 | ❌ 코드에 하드코딩 or 노트북에서 변경 | ✅ Parameter로 자동 기록 |
| 학습 데이터 버전 | ❌ 데이터는 Git에 안 올림 | ✅ 데이터 경로/버전 태그 기록 |
| 라이브러리 버전 | △ requirements.txt (수동 관리) | ✅ conda.yaml/pip 자동 기록 |
| 성능 메트릭 | ❌ 보통 노트북 출력이나 슬랙에만 남음 | ✅ Metric으로 자동 기록 + 비교 UI |
| 학습된 모델 파일 | ❌ .pkl 파일은 Git에 안 올림 (너무 큼) | ✅ Artifact로 자동 저장 |
| 실험 간 비교 | ❌ 수동으로 스프레드시트 작성 | ✅ UI에서 차트로 즉시 비교 |
MLflow가 실제로 해결하는 3가지 고통
고통 1: “이 모델을 누가 언제 만들었고, 어떤 데이터로 학습했나요?”
고통 2: “지난달 모델이 더 좋았는데, 뭐가 달랐지?”
고통 3: “이 모델을 프로덕션에 배포해주세요”
OSS MLflow vs Databricks MLflow: 실전에서의 차이
위 표에서 기능 비교를 했지만, 현업에서 체감하는 가장 큰 차이를 구체적으로 설명하겠습니다.차이 1: 서버 관리 부담
차이 2: 거버넌스
차이 3: 마이그레이션 용이성
💡 가장 좋은 소식: OSS MLflow에서 Databricks MLflow로의 전환은 코드 변경이 거의 없습니다.mlflow.set_tracking_uri() 한 줄만 제거하면 됩니다. Databricks 환경에서는 Tracking URI가 자동으로 설정되기 때문입니다.
💡 현업 팁: “우리는 OSS MLflow를 이미 잘 쓰고 있는데 Databricks MLflow로 전환할 필요가 있나요?”라는 질문을 자주 받습니다. 답은 팀 규모와 거버넌스 요구사항 에 달렸습니다. 데이터 사이언티스트가 3명 이하이고 규제가 없다면 OSS로 충분합니다. 하지만 10명 이상이고 모델 감사가 필요하다면, Databricks MLflow의 Unity Catalog 통합이 수백 시간의 수동 관리 작업 을 절약해줍니다.
정리
| 핵심 개념 | 설명 |
|---|---|
| MLflow | ML 라이프사이클 전체를 관리하는 오픈소스 플랫폼입니다. Databricks에서 기본 내장되어 별도 설치가 필요 없습니다 |
| MLflow 3.0 | GenAI 시대에 맞춘 대폭 업그레이드 버전으로, 트레이싱, LLM 평가, 에이전트 지원이 강화되었습니다 |
| Tracking | 실험의 파라미터, 메트릭, 아티팩트를 추적합니다. 여러 실험을 시각적으로 비교할 수 있습니다 |
| Models | 다양한 프레임워크의 모델을 표준 형식으로 패키징합니다. mlflow.pyfunc로 범용 모델도 지원합니다 |
| Registry | 모델 버전과 프로덕션 승격을 관리합니다 (Unity Catalog 통합) |
| Tracing | GenAI 앱의 실행 흐름을 단계별로 추적합니다. 디버깅과 성능 최적화에 필수적입니다 |
| Evaluate | 모델/에이전트 품질을 자동으로 평가합니다. LLM Judge 기반의 Scorer를 제공합니다 |